【02】基础:单页采集(以微博博主主页采集为例)
请先安装爬虫软件。爬虫软件安装
前言
今天讲讲微博博主主页的采集。
目标是采集博主名称、微博内容、发博日期、微博内容、转发数、评论数和点赞数。
学习流程见下图——

一、加载页面,定义主题名
样本网址:最近很火的宝宝的微博主页
http://weibo.com/wbq?refer_flag=1001030101_&is_hot=1#_rnd1471331959489
操作参见图。

二、建立整理箱进行内容映射
点击操作栏中的“创建规则”,点击新建,给整理箱取一个名称,整理箱就是存放数据的地方,比如“列表”,箱子必须有,否则程序不知道把采集下来的数据放哪里。

接下来告诉整理箱要采集的数据有哪些,分别取个名字。右击“列表”,选择“添加”,选择“包容”。

输入抓取内容的名称(博主名称)之后,后点击保存。
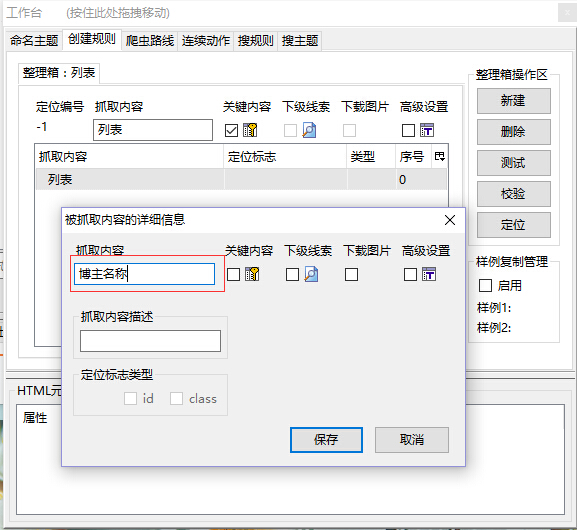
接下来,右击“博主名称”,选择“添加”,选择“其后”,同理,输入抓取内容的名称后点击保存。

前面说了,我们要采集博主名称、微博内容、发博日期、微博内容、转发数、评论数和点赞数这些字段,那就重复上一步操作分别添加。
接下来要告诉爬虫哪些内容是想采集的(内容映射)——

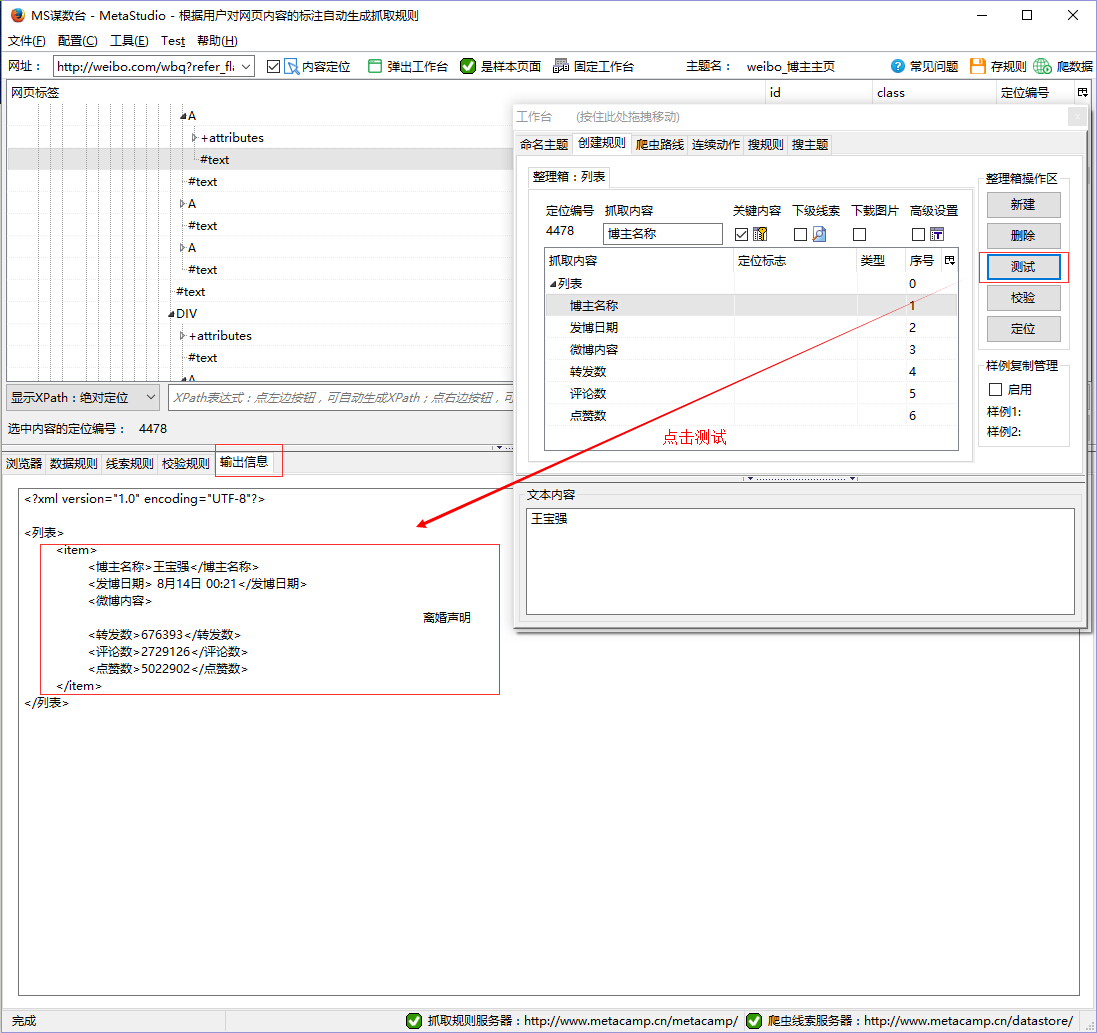
- 在MS谋数台的浏览器窗口,点击博主名称之后,会自动定位到网页标签中的A节点,双击展开A节点,找出包含博主名称的#text节点,我们看到文本内容窗口显示的内容是王宝宝,说明博主名称对应的节点选对了
- 右击#text节点,选择“内容映射>博主名称”,这时定位编号的数字由-1变成了正数,说明映射到了
上面的操作相当于告诉MS谋数台“博主名称”抓什么。
同理,其他的抓取内容也按此操作,先在MS谋数台浏览器中点击要抓取的内容,双击展开在网页标签窗口中定位到的区块节点,找到#text节点,内容映射给抓取内容的名称。
三、样例复制采集多条微博
点击“测试”按钮,弹出一个设置关键内容的框,之后将博主名称设置为关键内容,其实你可以设置任何一个抓取内容为关键内容,只要这个内容一定会在网页中出现就行了。

再次点击“测试”按钮,看到输出信息中只有一条微博内容。
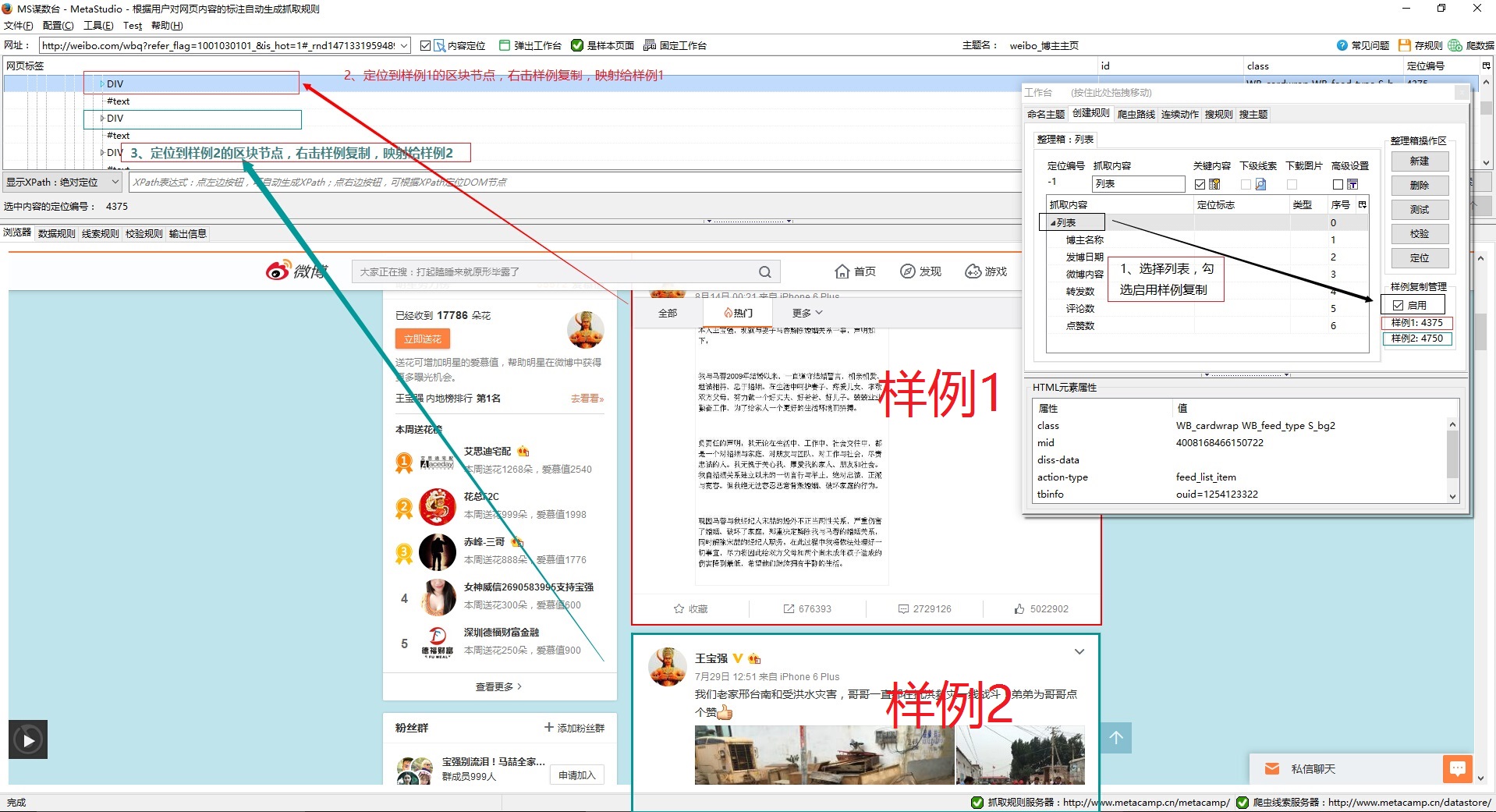
要实现采集博主主页上的多条微博,那么就要做样例复制操作,看图。
- 将鼠标定位到整理箱的容器节点“列表”(容器节点才能做样例复制),勾选启用
- 点击网页上的第一个样例(红框),自动定位后,往上逐层点击找到能框住整个样例的区块节点,然后右击映射给样例1
- 同理,选中相邻的下一个区块节点,映射给样例2
接着点击测试,发现转发数、评论数和点赞数采集的内容不准了,这个原因后面的教程会详细讲解。
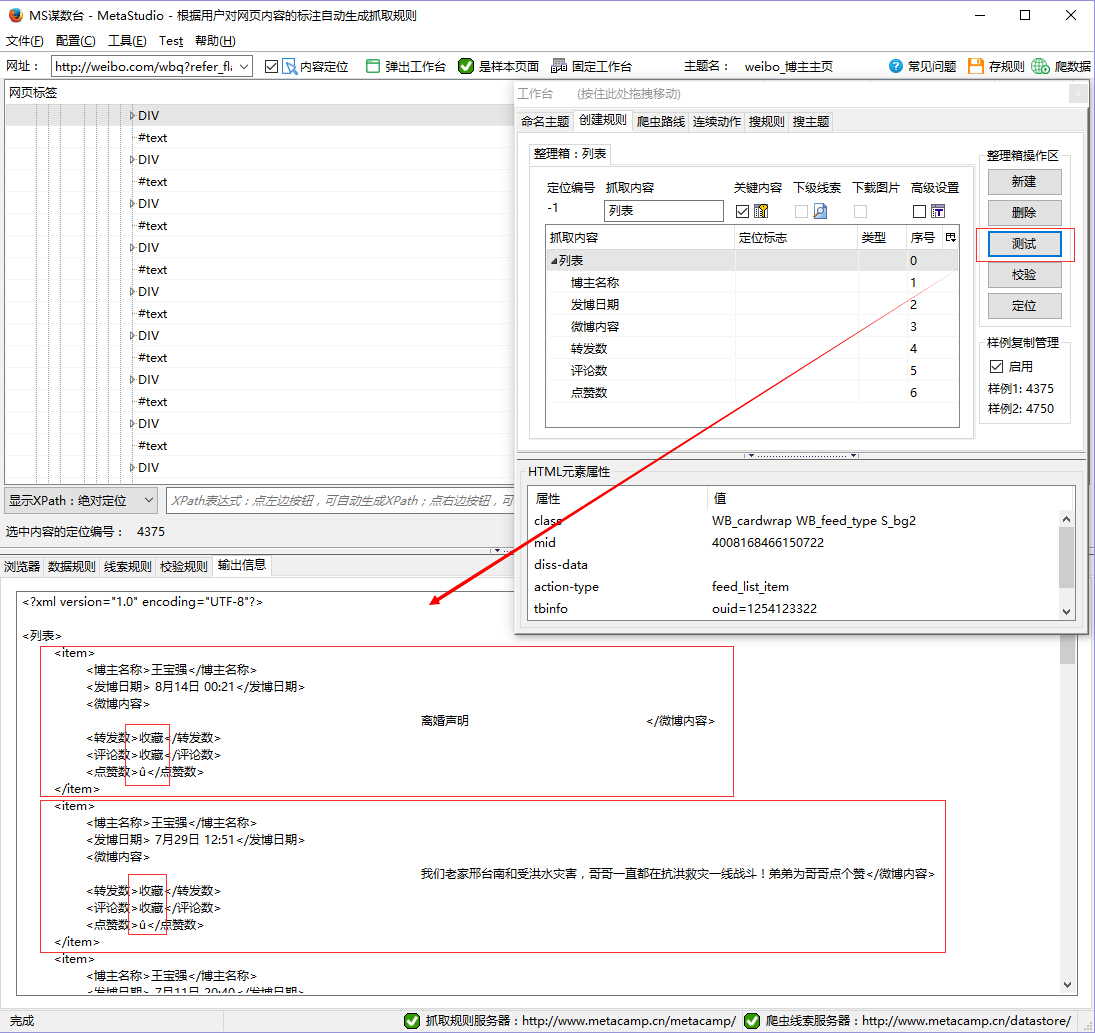
点击测试,将整理箱的定位偏好改为“偏好class”。

四、保存规则,运行DS打数机抓取数据
再次点击测试,采集内容准确了,确认规则没错后点击“存规则”,然后点击“爬数据”,期间会弹出DS打数机在采集数据,不要关闭它

DS打数机页面变成空白表示采集已经完成,点击“文件>存储路径”可以看到DS打数机采集的数据保存在本地哪了

在本地“DataScraperWorks”文件夹中可以看以该规则命名的一个子文件,用浏览器将子文件中的XML格式打开,看到宝宝的第一页微博数据都采集下来了,bingo~

看到这里,留下两个问题——
- 怎么将XML格式的文件转为Excel格式?
- 怎么采集多页的微博数据呢?
后面再学。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号