

python之re正则基础知识点
字符:
重点 {
\w ----> 匹配 字母 或 数字 或 下划线 (word的缩写)
\s ----> 匹配任意的 空白 (space的缩写)
\d ----> 匹配 数字 (digit缩写)
\W ----> 匹配 非字母 或 非数字 或 非下划线
\S ----> 匹配任意的 非空白
\D ----> 匹配 非 字数
}
\n ----> 匹配一个 换行符
\t ----> 匹配一个 制表符
^ ----> 匹配字符串的 开始
$ ----> 匹配字符串的 结尾
a|b ----> 匹配字符 a 或着 b
() ----> 匹配括号内的 表达式 也是一个 组
[...] ----> 匹配字符组 中的 字符
[^...] ----> 匹配除了 字符组 中的 所有字符
. ----> 匹配 除了 换行符 以外的任意字符
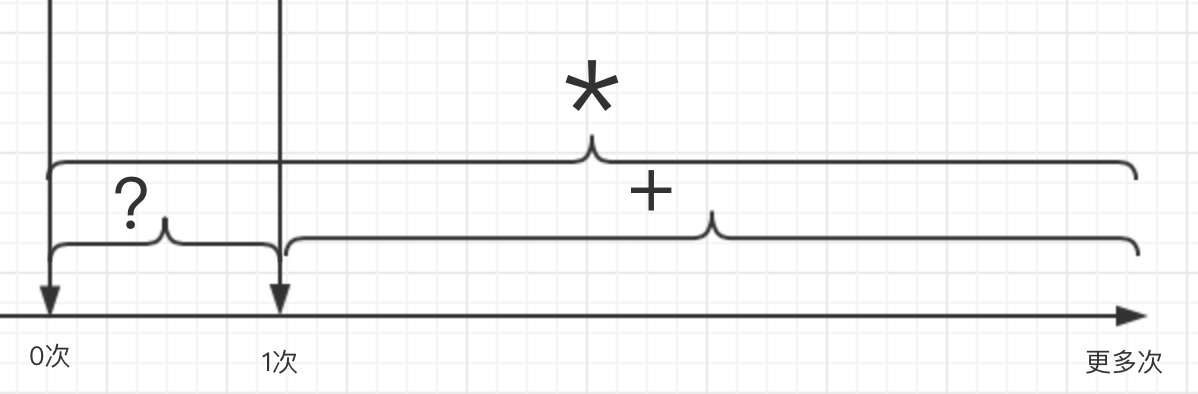
量词:
* ----> 重复零次或更多次
+ ----> 重复一次或更多次
? ----> 重复零次或一次
{n} ----> 重复n次
{n,} ----> 重复n次或更多次
{n,m} ----> 重复n到m次
几个常用的非贪婪匹配 pattern(模式)
*? ----> 重复任意次,但尽可能少重复
+? ----> 重复1次或更多次,但尽可能少重复
?? ----> 重复0次或1次,但尽可能少重复
{n,m}? ----> 重复n到m次,但尽可能少重复
{n,}*? ----> 重复n次以上,但尽可能少重复
.*?的用法
. 是任意字符
* 是取0至无线长度
?是非贪婪模式
合在一起就是 取尽量少的任意字符,一般不会这么单独写,它大多用在:
.*?x(就是取前面任意长度的字符),直到一个x出现
re模块下的常用方法
import re ret = re.findall('a','eva egon yuan') #返回所有满匹配条件的结果,放在一个列表里面 print(ret) #结果:['a', 'a'] ret = re.search('a','abc').group() #函数会在字符串内查找匹配,只要找到第一个匹配项,然后就返回一个包含匹配信息的对象,该对象可以 #通过点用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None,在调用group就报错啦 print(ret) #结果 a ret = re.match('av','avdf asdqwf gasdwda').group() #同search,不过仅在字符串开始处进行匹配 print(ret) #结果 av ret = re.subn('\d','H','1234568',5) #将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) #结果:('HHHHH68', 5) obj = re.compile('\d{3}') #将正则表达式编译成一个 正则表达式对象,规则表达式对象,规则要匹配3个数字 ret = obj.search('abc123eeeee') print(ret.group()) ret = re.finditer('\d','ds3sy4784a') #finditer 返回一个存放匹配结果的迭代器 print(ret) #<callable_iterator object at 0x10b2f2630> 迭代器名称 print(next(ret).group()) #查询第一个结果 print(next(ret).group()) #查询第二个结果 print([i.group() for i in ret]) #表达式生成器 查看剩余的结果
特殊注意findall|split
# findall的优先级查询 即匹配结果的不同 # 在匹配组开头加上 ?: 即可匹配到完整结果 不然 只能是匹配组里面的内容 ret = re.findall('www.(baidu|17game).com','wwww.17game.com,www.baidu.com') print(ret) #这是因为findall会优先把匹配组连的内容返回,如果想匹配结果,取消权限即可 # 结果:['17game', 'baidu'] ret = re.findall('www.(?:baidu|17game).com','wwww.17game.com,www.baidu.com') print(ret) # 结果:['www.17game.com', 'www.baidu.com'] #split的优先级查询 即匹配结果不同 ret = re.split('\d+','eva3egon4yuan') print(ret) # 结果 ['eva', 'egon', 'yuan'] ret = re.split('(\d+)','eva3egon4yuan') print(ret) # 结果:['eva', '3', 'egon', '4', 'yuan'] # 总结:在匹配部分加上()之后切出来的列表不同的 # 没有()的没有保留所有匹配项,但是有()的却能够保留了匹配的项 # 这个在某些需要保留匹配部分的使用过程非常重要
fiags值
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释

 浙公网安备 33010602011771号
浙公网安备 33010602011771号