4. 分数排名
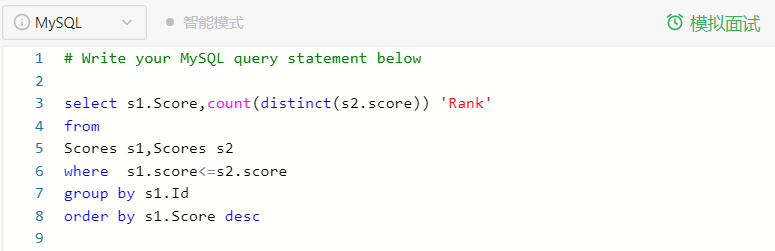

简单分析:
<1> group by s1.Id 是因为用到了聚合函数,需要将每一个个体分为一组,不然将所有的人视为一组进行 count
<2> order by s1.Score desc 是将查询后的结果进行排序,按照分数降序排序
<3> where 是一个筛选条件,满足条件的记录将进行后面的处理(count聚合)
<4> 这里为什么 rank,要打上单引号,因为在新版中,rank 是一个关键字。
<5> 任意一个 s1.Score ,都将与 s2.Score进行对比,并进行一次 count 操作
反思:
<1> 对中间过程不清晰,尤其是查询时生成中间表的原理。
<2> 对下面错误不知道原因在哪。
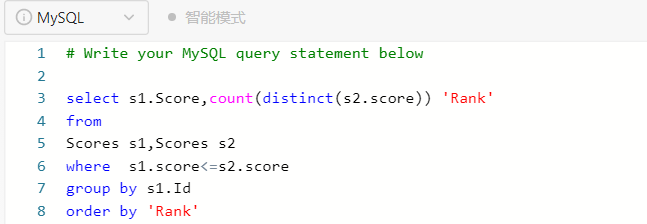
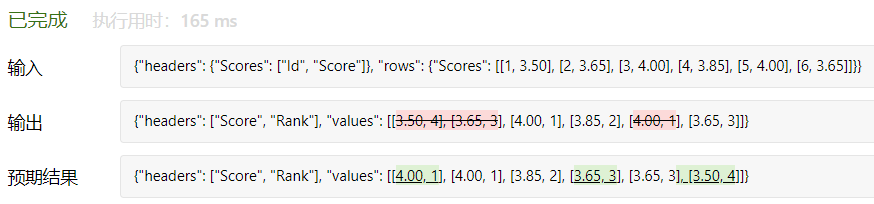
事实上,输出结果是按照测试用例中的 Score 顺序排列的,但在代码中写的是 按照 'Rank' 升序排列,这里面的实现细节不是很清楚。
零碎学习的感觉非常烦恼, SQL和 MySql 又在语法上有所差异,实现原理破破碎碎不连贯。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号