

模拟登录看前端门外汉学习
学语言我个人还是觉得首先了解他的特点和适用场景,然后就是动手干(官方文档+g出来的一大堆ref)。写惯Java的人,一旦介入到动态语言,就会觉得一身轻松。Python可以采用交互的命令行工具,即时写,即时看,也可以搞个eclipse插件和Java一样写。用了urllib库和cookielib库,几句话就可以提交请求和保持cookie了。
接下来就是去看需要登录网站的登录模式。看了一下这个网站没有走https,但是也不是很简单的明文传输,那么就要用个工具看看怎么回事了。Chrome和firefox + firebug都是极佳的工具(以前在IE下搞过破解版的httpwatch,太麻烦了),后面就用chrome来做介绍,它内置的控制台还是很强大的,包括我这里没有介绍的性能检测部分的功能。
首先你需要记录下你进入这个登录首页时候所有的http请求,不是说一定只记录临门一脚的提交请求就可以了,现在为了防范CSRF等攻击,都会做一些安全方面的preload page,下面就一张图一些描述来说明这个过程:

这张图是用chrome来记录进入页面到点击提交过程中所有的请求,其中红色圈圈中的那个红色点就是记录所有的请求,就算当前页面被重新载入或者302跳转到其他地方去,前面的记录依然存在,这很有必要,不然登录成功后就找不到前面的记录了。可以看到红色的圈中有一个prelogin的页面,当然现在还不好确定干啥用,接着往下看。
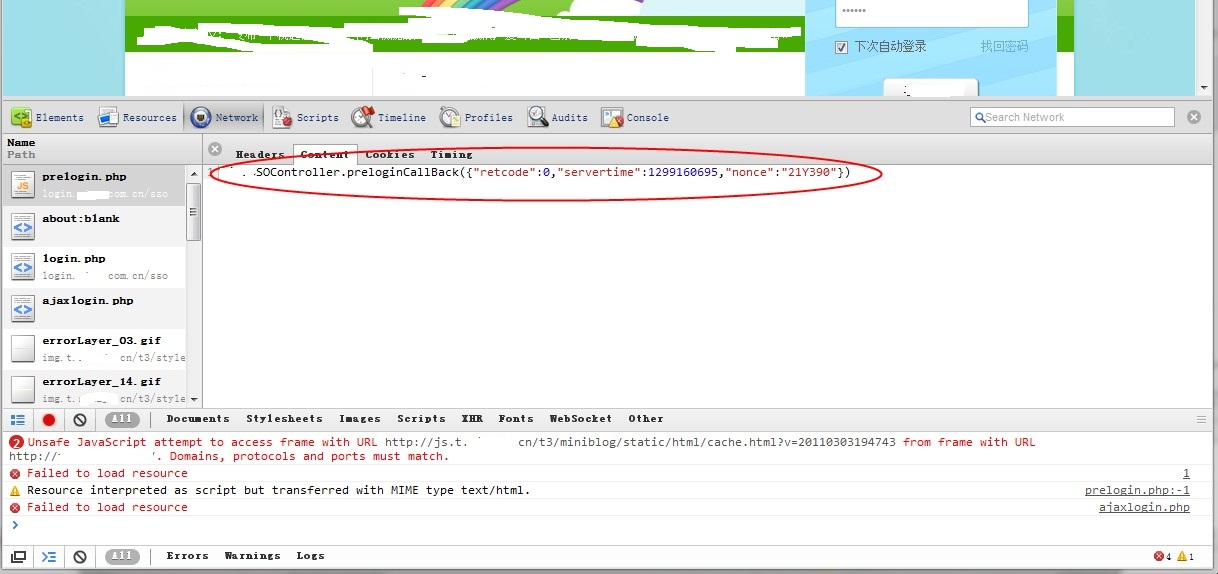
选中这个prelogin页面,然后看到右面就会出现其相关内容,可以选择content看看它的范围,结果是有范围的,返回了三个值,其中nonce(随机数)常常被用于防CSRF攻击或者防重放。至此还看不出什么端倪,接着看
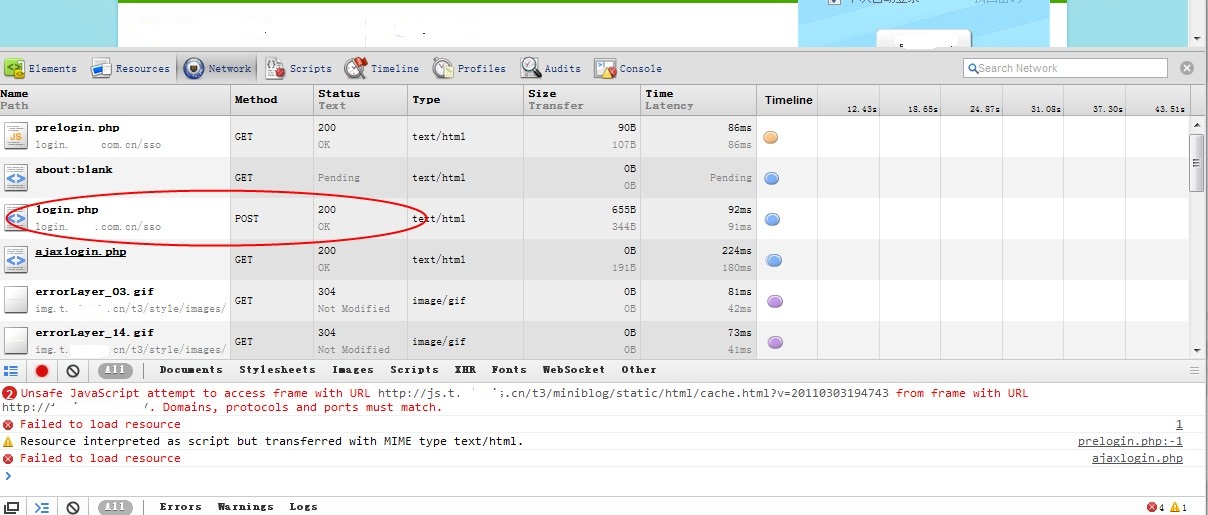
Login.php是post类型的,多半就是提交验证的(当然后面谈到仔细去看两个来回交互的js就可以很清楚的知道点击的那个超链接的btn就是触发这个提交)
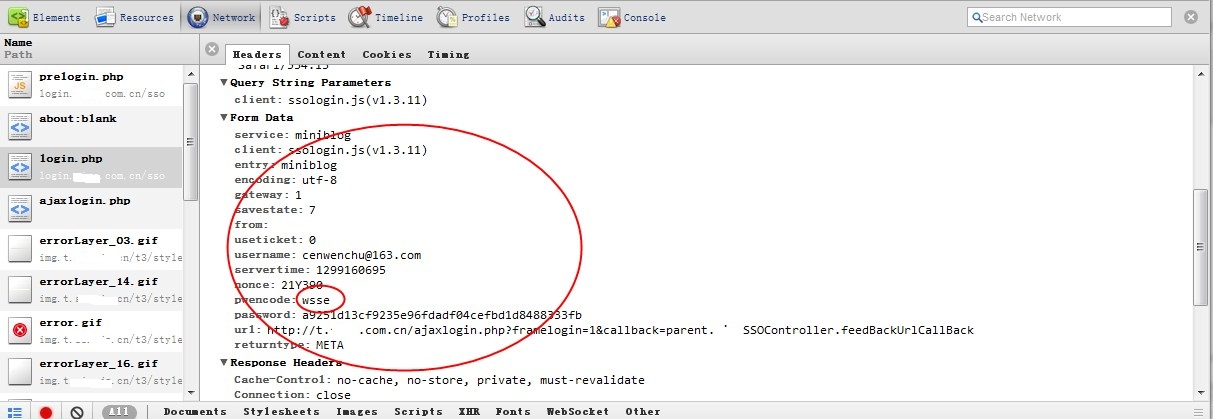
选中login.php的这个post请求,直接看它的Form Data,里面就是所有提交的参数,可以发现nonce,servertime都在此列,同时看password已经被加密,而下面有个关键词“wsse”,其实当年在做webservice接触的比较多,是一种避免用户密码明文传递的验证加密算法,有兴趣的同学可以直接搜索一下,有一个pdf很清楚的说明了一切。其实这个页面我反复不同的密码请求了几次,相同的密码请求了几次,最后确定哪些内容是动态变化的,哪些是固定的,最后其实就是password,nonce,servertime是变化的,其他都是固化的。这下就简单了,首先模拟请求prelogin,这直接看看prelogin的get中url便知如何请求,然后将结果拼凑到下一次post到login的请求中,但最后就是password怎么计算出来,先尝试了直接用标准的模式来生成base64(sha(password+nonce+servertime)),结果不行,那么就要仔细看看js代码了,其实从刚才到现在都是从现象来猜一些问题,真的不行的时候还是要靠看代码。

找到了对应的Dom元素,看到login_submit_btn是个超链接,然后用了一个啥都不做的js(很多网站都用这种模式,采用动态add event listener的方式),这下就要找js代码了。因为wsse机制就是在本地做好签名,然后发送签名到服务端,服务端做同样的签名,由于不可逆,所以保证了安全性和身份有效性,因此只要找到提交的js代码,然后看清楚里面的签名算法就可以搞定了。
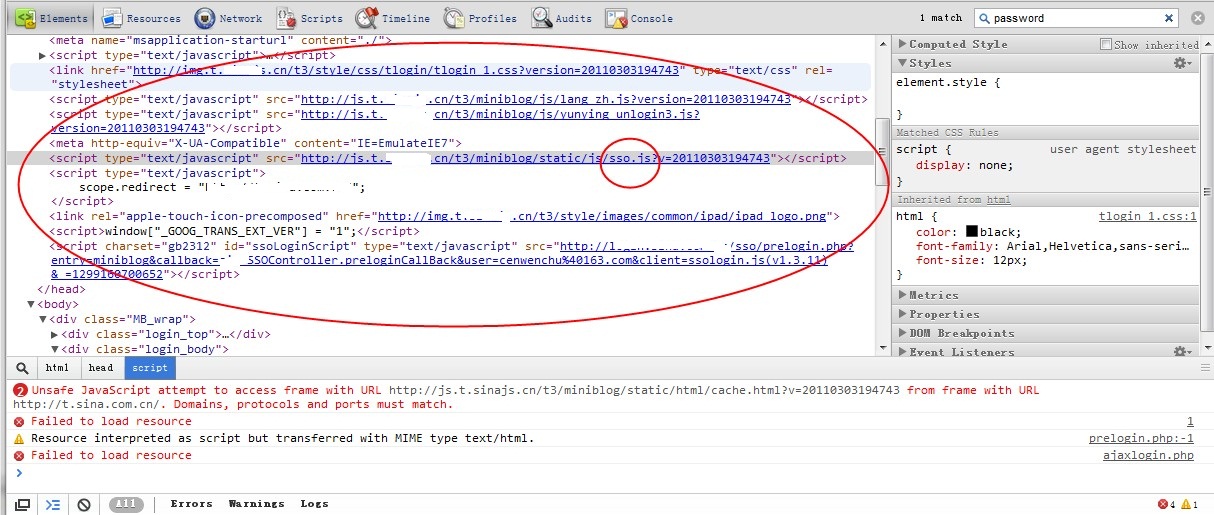
网站的同学写的很规范,都在head里面放了几个js,其中sso顾名思义就是用来做登录的,遂直接下载看看,结果:
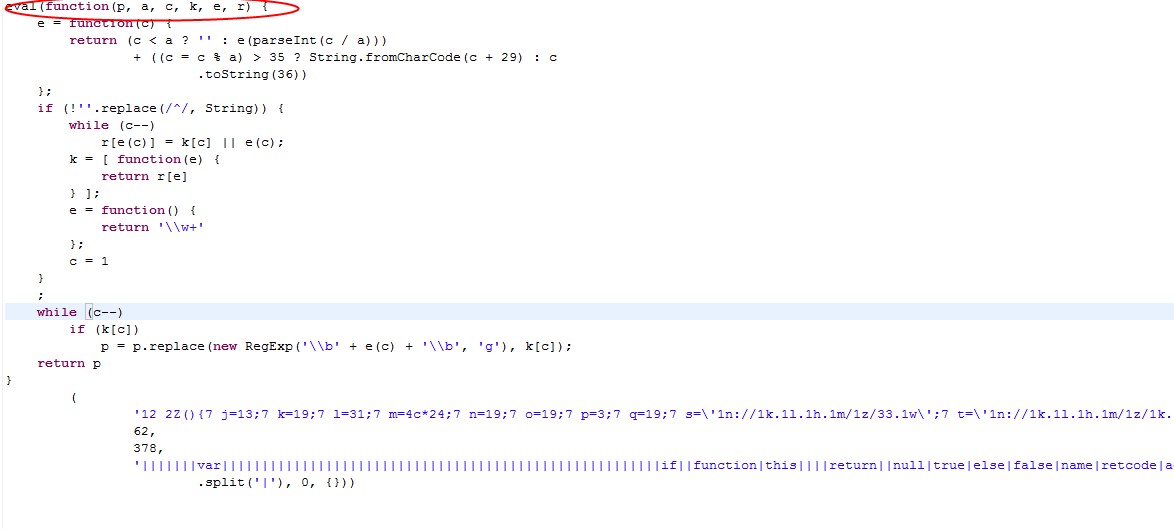
由于上次仔细搞js还是4年多以前的事情了,现在完全落伍,看到这样的代码,以为就是直接用document.write执行以下就可以了(原本以为就是用来压缩的,其实还有混淆的功能,解也不能这么简单的解开),当然此时我对于词语的敏感最后还是帮助了我(我红色标注的地方),其实很多时候对于一些现象和词语的敏感可以直接帮你在Google中找到答案。
用那种自以为可以的方式解开后却发现还有一些js函数居然没有出现@_@,一头汗阿,此时反复去刷页面看现象的时候,突然发现原来在另外一个浮起登陆的页面提交登陆时候是明文的,就是去掉了pwencode=wsse和nonce及servertime,测试了一把,成功登录并且进入群页面获得了自己的所有群中信息。本来到此也就算了,因为目的达到了,但是对于js混淆及调试心里还是有些不甘,所以停下原本要做的事,继续摸索。

这是用chrome在线调试js的界面,你可以在右边Event listener breakpoints中设置鼠标点击事件的debug,当然也可以设置其他的方式,但是由于混淆和压缩的缘故,左边的js都是一条语句,调试很困难,不过可以看到右边的call stack就好比java的调用堆栈输出(当然没java那么强大)local可以观察每次进入不同的请求或者闭包时一些内部变量的变化,总的来说调试正常的js一定是很强大的。
由于调试不成功,只好仔细的去看几个js,幸好整个页面就4个js,其中两个一看就可以过滤掉,另外一个名字取得很怪,里面却做了它不该做的事情,包括对于事件监听器的增加,页面结构的输出等等,最后调用了sso那个js,又进入死循环了。
想起了js压缩混淆的事情,想了想花了太多时间了,感觉也许真的很难搞(我也咨询了我们的前端专家,谈到如果没有源码,光调试想搞清楚混淆的js工作会很困难),不过出于对混淆和压缩原理的好奇心,就去搜索了一下(本来就是为了学习一下基础,也许哪天可以用在Java中),可前面提到的对参数使用(p,a,c,k,e,r)的敏感最后让我看到了js压缩比较出名的作品,同时他的blog也收录囊中(以后慢慢看),最后自然找到了破解之法,翻译出了那段混淆的编码,得到了宝贵的算法,在微博中喊了一句:爽,hex_sha1("" + hex_sha1(hex_sha1(b)) + j.servertime + j.nonce),结束了这次前端探索之旅,下面是最后一个图:

对于前端的内行来说,这点雕虫小技算不上什么,当然从开头我就写了,记录这个只是想说一些学东西的思维,要做深,这样是远远不够的,需要更加沉下心来积累很多背后的故事(比如说看完那个高手的blog,了解数据压缩和混淆的机制,自己写一个反混淆的代码)。

