springboot jpa-hibernate
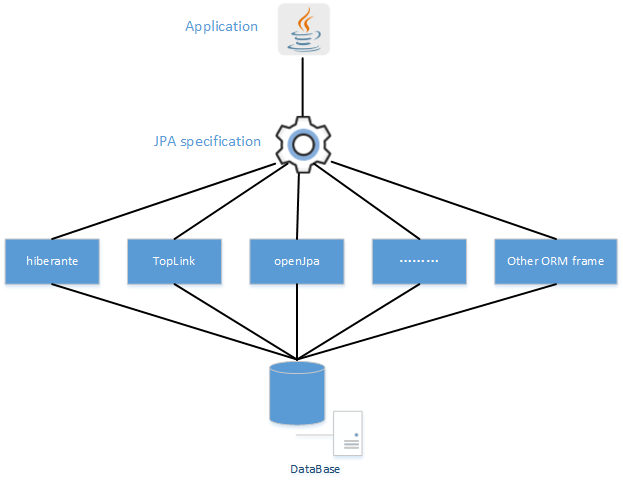
jpa:它是Java Persistence API的简称,中文名Java持久层API,是通过JDK注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中
hibernate:它是全自动orm(object relation mapping对象关系映射)框架,自动生成sql语句。
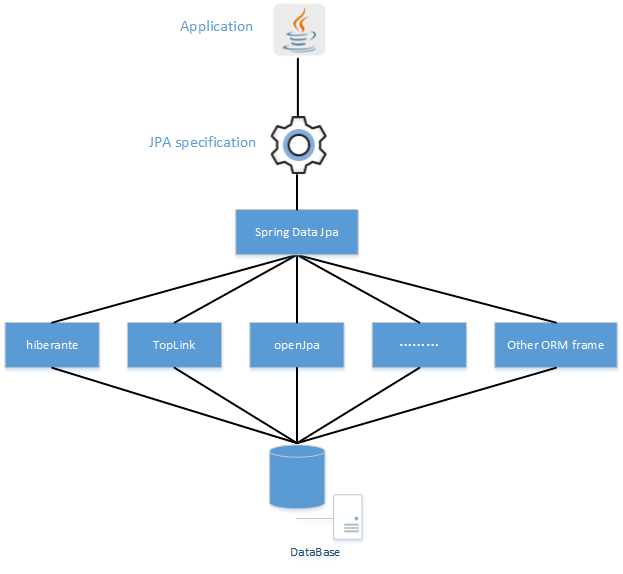
spring data简化数据库的访问(类似spring framework对jdbc,orm的支持一样)
spring data jpa:简化jpa的写法,单独的jpa,代码开发和jdbc一样繁琐,封装了curd,分页,排序等功能。只需编写一个接口,继承一个类就实现curd了。
(hibernate是jpa的实现者,而spring data jpa在hibernate的基础上,再封装几层,数据访问更加方便和快速,通过提供基于JPA的Repository极大地减少了JPA作为数据访问方案的代码量)
一图胜千言:
添加mysql驱动依赖,添加spring-boot-starter-data-jpa依赖,其中spring-boot-starter-data-jpa它整合了(hibernate,aop。。。。)
首先Application应该放在包的最外层。然后在包下创建Cat类:写如:
package com.example.sprintboot.jpahibernate; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; @Entity public class Cat { private String catName; private String catAge; @Id @GeneratedValue(strategy = GenerationType.AUTO) private int id; public String getCatName() { return catName; } public void setCatName(String catName) { this.catName = catName; } public String getCatAge() { return catAge; } public void setCatAge(String catAge) { this.catAge = catAge; } public int getId() { return id; } public void setId(int id) { this.id = id; } }
其中@Entity进行类的持久化操作,当ApplicationSpringBoot扫描完所有包后,jpa又会去检测,检测到我们的实体类@Entity,会在数据库中生成对应的表结构信息,(即生成表)
运行程序,就会在数据库中看到表。
(@GenerationType.TABLE,SEQUENCE,IDENTITY,AUTO)
JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO.
TABLE:使用一个特定的数据库表格来保存主键。
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
IDENTITY:主键由数据库自动生成(主要是自动增长型)
AUTO:主键由程序控制。
创建一个接口:CatRepository(需要两个参数,实体类的名称,主键的类型)
jpa-hibernate完成增删改查代码分析:
增删改查的操作主要由封装好的crudRepository类完成,我们只需写一个接口继承crudRepository接口,再分别调用它的增删改查方法即可,这样我们可以把精力放在业务逻辑层的代码的编写。
crudRepository接口继承Reposition接口,而Reposition接口不提供任何的方法
@Indexed public interface Repository<T, ID> { }
它是一个空接口,,即标记接口,继承了Repository的接口都会被ioc容器识别为一个Reposotory Beannaruioc容器中,在定义的接口中的方法(方法名)需要遵循一定的规则(规范),也可通过@RepositoryDefination注解代替继承@repository接口
查询方法(方法名)要以find,read,get开头,,查询的方法名的属性的首字母要大写(如:findOne())
可以使用@Query注解自定义JPQL语句进行更灵活的查询。crudReposity提供的接口有:
T save(T entity)//保存单个实体
Iterable<T>save(Iterable<? extends T>entities)//保存集合
T findOne(ID id)根据id找实体
void deleteById(ID id)根据id删除实体
void delete(T entity)删除一个实体
Iterable<T>findAll(Sort sort) //排序
Page <T> findAll(Pageable pageable) //分页查询(含排序功能)
。。。。。。。。。。
类似还有别的接口Jparepository(查找所有实体,排序,执行缓存。。。),jpaSpecificationExecutor,(不属于repository体系,封装的是jpa criteria)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号