

2016-6-18
--今天实现了第一个用urllib2实现的爬虫程序。
--过程中发现
req = urllib2.Request(url,headers = headers)
总是报错: 主要原因在于 url 地址错误。
例如:http://www.neihan8.com/wenzi/index_1.html
这个网址打开的是404网页错误。
但是 http://www.neihan8.com/wenzi/index_2.html 这个网页却可以了。
源代码如下:
#-*- coding:utf-8 -*-
import urllib2
class Spider:
'''
内涵段子吧。。。
'''
def load_page(self,page):
'''
发送内涵段子url
'''
url = 'http://www.neihan8.com/wenzi/index_'+ str(page) +'.html'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36"}
req = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(req)
html = response.read()
return html
#main
'''
'''
if __name__ == '__main__':
mySpider = Spider()
the_page = mySpider.load_page(2)
print the_page
综上,我们可以在代码中加一个判断 url 是否打开正常的代码,这个需要学习。
-----------------------------------------------------------华丽丽的分割线-------------------------------------------------------------------------------------------------
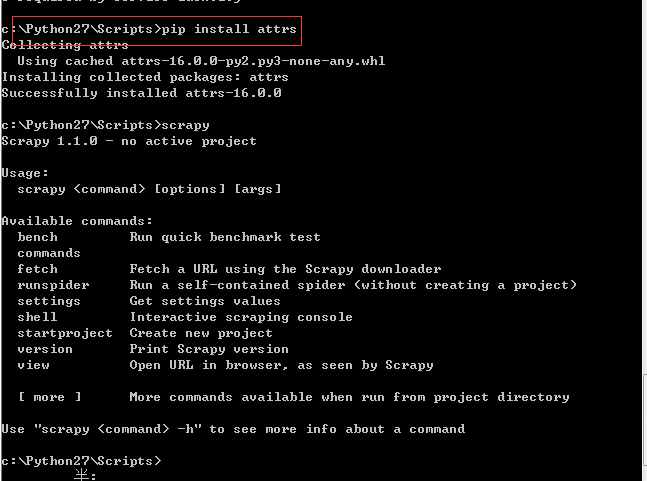
安装Scrapy

--安装scrapy 都要快被安装死了
首先会发现提示 一下问题:
1.版本问题,就是说 Scrapy 所依赖的模块版本太低。'>=1.00' 表明你要使用大于1.0的版本
2.
说明 你有一个包 attrs 没有安装。
那就使用 pip install attrs 安装即可
安装完之后终于正常了。。。。
Python教程:pywin32下载安装
下载链接http://sourceforge.net/projects/pywin32/files/pywin32/Build%20218/pywin32-218.win32-py2.7.exe/download
-------------------------开启爬虫之路----------------------------------------------
首先先说明当中可能遇到的问题:
1.String or binary data would be truncated.解决方法
步骤:在执行插入语句时,会提示上面的error。
原因:是因为数据库中定义的字段长度比较小,在插入或者更新的时候,用一个比这个字段长度大的值去操作,就会引起这个错误。
2.
python向数据库插入中文乱码问题
第一步:数据库那边总得把字段类型设置为utf8之类类的吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号