Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop分布式集群部署安装
在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步activenamenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当ActiveNameNode挂掉了,会自动切换Standby NameNode为standby状态。
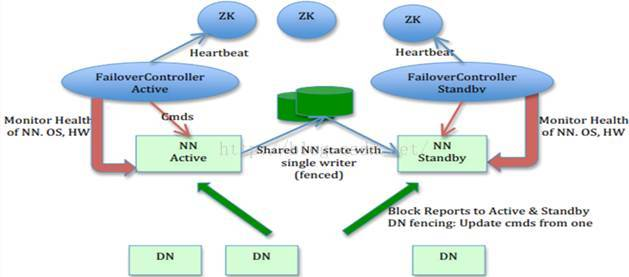
1.1 Hadoop分布式集群工作原理图
1.2 集群规划
主机名
IP
安装软件
运行进程
Hadoop1
192.168.1.121
Jdk、Hadoop
NameNode、DFSZKFailoverController
Hadoop2
192.168.1.122
Jdk、Hadoop
NameNode、DFSZKFailoverController
Hadoop3
192.168.1.123
Jdk、Hadoop
ResourceManager
Hadoop4
192.168.1.124
Jdk、Hadoop、Zookeep
DataNode、NodeManager、JournalNode、QuorumPeerMain
Hadoop5
192.168.1.125
Jdk、Hadoop、Zookeep
DataNode、NodeManager、JournalNode、QuorumPeerMain
Hadoop6
192.168.1.126
Jdk、Hadoop、Zookeep
DataNode、NodeManager、JournalNode、QuorumPeerMain
1.3 相关下载
1、JDK下载地址:jdk-8u66-linux-x64.tar.gz
Linux安装JDK及环境变量配置,参见:http://blog.csdn.net/yuan_xw/article/details/49948285
2、Hadoop下载:hadoop-2.7.1.tar.gz
3、Zookeeper下载:zookeeper-3.4.5.tar.gz
1.4 配置hosts文件
配置Hadoop1服务器,执行命令:vi /etc/hosts
127.0.0.1 localhost
192.168.1.121 Hadoop1
192.168.1.122 Hadoop2
192.168.1.123 Hadoop3
192.168.1.124 Hadoop4
192.168.1.125 Hadoop5
192.168.1.126 Hadoop6
其它服务scp命令进行复制:
scp /etc/hosts192.168.1.122:/etc/
scp /etc/hosts192.168.1.123:/etc/
scp /etc/hosts192.168.1.124:/etc/
scp /etc/hosts 192.168.1.125:/etc/
scp /etc/hosts 192.168.1.126:/etc/
1.5 配置ssh免密码登录
产生密钥,执行命令:ssh-keygen -t rsa,按4回车,密钥文件位于~/.ssh文件
在Hadoop1上生产一对钥匙,将公钥拷贝到其他节点,包括自己,执行命令:
ssh-copy-id Hadoop1
ssh-copy-id Hadoop2
ssh-copy-id Hadoop3
ssh-copy-id Hadoop4
ssh-copy-id Hadoop5
ssh-copy-id Hadoop6
在Hadoop3上生产一对钥匙,配置Hadoop3到Hadoop4、Hadoop5、Hadoop6的免密码登陆,执行命令:
产生密钥,执行命令:ssh-keygen -t rsa,按4回车,密钥文件位于~/.ssh文件,将公钥拷贝到其他节点
ssh-copy-id Hadoop4
ssh-copy-id Hadoop5
ssh-copy-id Hadoop6
在Hadoop2上生产一对钥匙,两个namenode之间要配置ssh免密码登陆,执行命令:
产生密钥,执行命令:ssh-keygen -t rsa,按4回车,密钥文件位于~/.ssh文件,将公钥拷贝到其他节点
ssh-copy-id -i Hadoop1
1.6 关闭防火墙
1、关闭防火墙:
安装iptables-services命令:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
验证:firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
关闭防火墙自动运行:
执行命令:systemctl disable iptables.service
验证:systemctl list-unit-files |grep iptables
用上述同样的方法在Hadoop2、Hadoop3、Hadoop4、Hadoop5、Hadoop6中如法炮制即可。
1.7 上传服务器
Hadoop1服务器创建/usr/local/software/package目录后,再进行上传:

解压JDK:
执行命令:tar -zxvf jdk-8u66-linux-x64.tar.gz -C /usr/local/software/
解压:Hadoop:
执行命令:tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/software/
重命名:mv hadoop-2.7.1/ hadoop_2.7.1/
Hadoop4服务器创建/usr/local/software/package目录后,再进行上传:

解压Zookeeper:
执行命令:tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/local/software/
重命名:mv zookeeper-3.4.5zookeeper_3.4.5
在服务器节点(Hadoop2、Hadoop3、Hadoop4、Hadoop5、Hadoop6),创建/usr/local/software目录。
解压完后成后,分别在Hadoop1、Hadoop4删除/usr/local/software/package目录:
执行命令:rm -rf /usr/local/software/package/
1.8 修改配置文件(Hadoop1):
2、修改hadoop-env.sh配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/etc/hadoop/hadoop-env.sh
修改内容:
export JAVA_HOME=/usr/local/software/jdk1.8.0_66
3、修改core-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1/ etc/hadoop/core-site.xml
修改内容:
<configuration>
<!--指定hdfs的nameService1节点URL地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- Hadoop的运行时文件存放路径,如果不存在此目录需要格式化 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/software/hadoop_2.7.1/tmp</value>
</property>
<!-- Zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>Hadoop4:2181,Hadoop5:2181,Hadoop6:2181</value>
</property>
</configuration>
4、修改hdfs-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1 /etc/hadoop/hdfs-site.xml
修改内容:
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>Hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>Hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>Hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>Hadoop2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Hadoop4:8485;Hadoop5:8485;Hadoop6:8485/ns1
</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/itcast/hadoop-2.2.0/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
5、修改mapred-site.xml配置文件:
执行命令:
切换目录:cd /usr/local/software/hadoop_2.7.1/etc/hadoop/
重命名:mv mapred-site.xml.template mapred-site.xml
修改文件:vi mapred-site.xml
修改内容:
<configuration>
<!-- 指定Hadoop的MapReduce运行在YARN环境 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6、修改yarn-site.xml配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1 /etc/hadoop/yarn-site.xml
修改内容:
<configuration>
<!--指定YARN的master节点( ResourceManager) 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop3</value>
</property>
<!-- NodeManager获取数据方式:shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7、修改slaves配置文件:
执行命令:
vi /usr/local/software/hadoop_2.7.1 /etc/hadoop/slaves
Hadoop4
Hadoop5
Hadoop6
1.9 环境变量
1、Hadoop1修改profilie文件:执行命令:vi/etc/profile
export JAVA_HOME=/usr/local/software/jdk1.8.0_66
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/software/hadoop_2.7.1
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
2、Hadoop1复制文件到服务器:Hadoop2、Hadoop3、Hadoop4、Hadoop5、Hadoop6
Hadoop1复制JDK:
scp -r /usr/local/software/ Hadoop2:/usr/local/
scp -r /usr/local/software/ Hadoop3:/usr/local/
scp -r /usr/local/software/ Hadoop4:/usr/local/
scp -r /usr/local/software/ Hadoop5:/usr/local/
scp -r /usr/local/software/ Hadoop6:/usr/local/
3、Hadoop1复制环境变量:Hadoop2、Hadoop3
scp /etc/profile Hadoop2:/etc/
scp /etc/profile Hadoop3:/etc/
4、Hadoop4修改profilie文件:执行命令:vi/etc/profile
export JAVA_HOME=/usr/local/software/jdk1.8.0_66
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/software/hadoop_2.7.1
export ZOOKEEPER_HOME=/usr/local/software/zookeeper_3.4.5
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
5、Hadoop4复制文件到服务器:Hadoop5、Hadoop6
Hadoop1复制zookeeper:
scp -r zookeeper_3.4.5/ Hadoop5:/usr/local/software/zookeeper_3.4.5/
scp -r zookeeper_3.4.5/ Hadoop6:/usr/local/software/zookeeper_3.4.5/
6、Hadoop4复制环境变量: Hadoop5、Hadoop6
scp /etc/profile Hadoop5:/etc/
scp /etc/profile Hadoop6:/etc/
7、在Hadoop1、Hadoop2、Hadoop3、Hadoop4、Hadoop5、Hadoop6,分别刷新环境变量
执行命令:source /etc/profile 刷新环境变量
1.10 Zookeeper集群配置:
1、修改zoo.cfg文件:
执行命令:
cd /usr/local/software/zookeeper_3.4.5/conf
mv zoo_sample.cfgzoo.cfg
修改内容,执行命令:vi zoo.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/software/zookeeper_3.4.5/data
clientPort=2181
server.4 = Hadoop4:2888:3888
server.5 = Hadoop5:2888:3888
server.6 = Hadoop6:2888:3888
2、服务器标识配置
创建文件夹:mkdir data。
创建文件myid并填写内容为4:vi myid (内容为服务器标识:4)。
把Hadoop5、Hadoop6中的myid文件里的值修改为5和6路径(vi %ZOOKEEPER_HOME%/data/myid)。
按照相同的步骤,为其它机器都配置上zoo.cfg和myid文件。
1.11 启动Zookeeper:
分别在Hadoop4、Hadoop5、Hadoop6服务器上启动zookeeper:
Hadoop4执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh start #启动zookeeper
Hadoop5执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh start #启动zookeeper
Hadoop6执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh start #启动zookeeper
Hadoop4执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh status #查看启动状态
Hadoop5执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh status #查看启动状态
Hadoop6执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkServer.sh status #查看启动状态
1.12 启动journalnode:
在Hadoop1上启动所有journalnode,注意:是调用的hadoop-daemon.sh这个脚本:
Hadoop4执行命令:/usr/local/software/hadoop_2.7.1/sbin/hadoop-daemon.shstart journalnode #启动journalnode
Hadoop5执行命令:/usr/local/software/hadoop_2.7.1/sbin/hadoop-daemon.shstart journalnode #启动journalnode
Hadoop6执行命令:/usr/local/software/hadoop_2.7.1/sbin/hadoop-daemon.shstart journalnode #启动journalnode
1.13 格式化文件系统:
在Hadoop1服务器上进行:HDFS文件系统进行格式化,执行命令:
# hadoop namenode -formate(已过时)
hdfs namenode -format推荐使用
验证:提示如下信息表示成功:

INFO common.Storage: Storage directory/usr/local/software/hadoop_2.7.1/tmp/dfs/name has been successfully formatted.
Hadoop的运行时文件存放路径为:tmp目录,Hadoop2需要和Hadoop1一致,进行拷贝:
执行命令:scp -r/usr/local/software/hadoop_2.7.1/tmp Hadoop2:/usr/local/software/hadoop_2.7.1/
1.14 格式化formatZK:
只需要在Hadoop1上进行执行命名即可:
执行命令:hdfs zkfc -formatZK
验证:
打开Hadoop4服务器zookeeper客户端,查看是否存在hadoop-ha节点
执行命令:/usr/local/software/zookeeper_3.4.5/bin/zkCli.sh
查看节点命令:ls /

1.15 启动HDFS:
1、只需要在Hadoop1上启动HDFS,
执行命令:/usr/local/software/hadoop_2.7.1/sbin/start-dfs.sh
验证启动HDFS:
Jps:JDK提供查看当前java进程的小工具。
NameNode:它是Hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
DFSZKFailoverController会定期通过该rpc调用proxy.monitorHealth()来监测NN的健康状况。

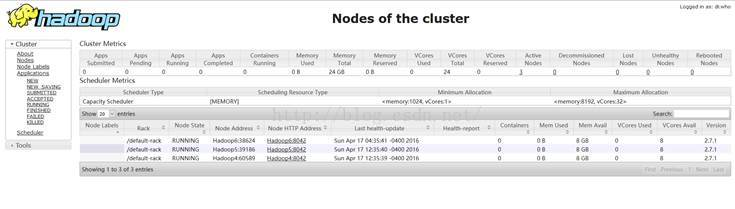
1.16 启动YARN:
1、只需要在Hadoop3上启动YARN,
执行命令:/usr/local/software/hadoop_2.7.1/sbin/start-yarn.sh
2、验证启动YARN:

Jps:JDK提供查看当前java进程的小工具。
ResourceManager:接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
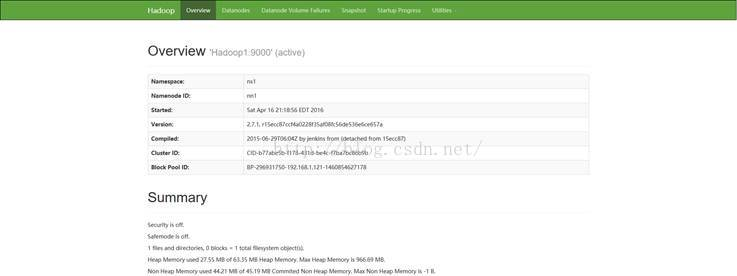
1.17 访问Hadoop服务页面:
访问地址验证启动服务,访问地址:
HDFS管理界面:http://192.168.1.121:50070/
YARN管理界面:http://192.168.1.123:8088/
1.18 验证HDFS - HA主备切换:
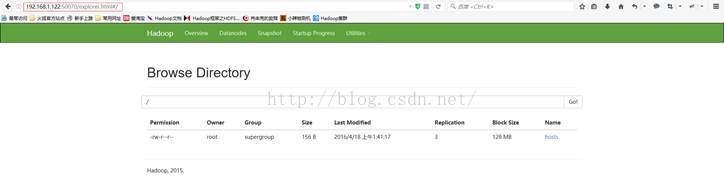
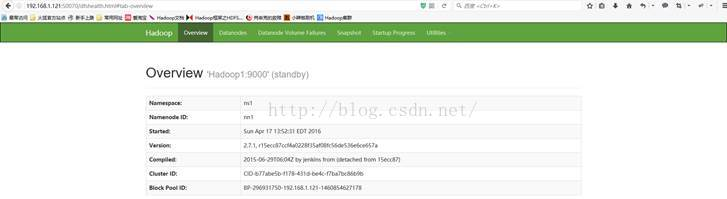
1、验证Hadoop1服务器NameNode和Hadoop2服务器NameNode数据文件是否可以共享:
在Hadoop1上传文件hosts文件:
执行命令:hadoop fs-put /etc/hosts /

杀掉Hadoop1 NameNode进程,执行命令:
查看进程:jps
Kill -9 6068

验证成功
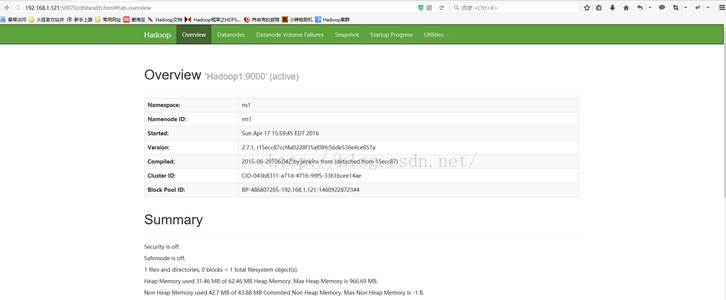
2、启动Hadoop1上的NameNode进程,将Hadoop2服务器进行强制关机,验证是否可以激活Hadoop1:
启动Hadoop1服务器NameNode进程:
执行命令:/usr/local/software/hadoop_2.7.1/sbin/hadoop-daemon.shstart namenode

将Hadoop2服务进行关机处理:
主备切换对比图:
————————————————
版权声明:本文为CSDN博主「_否极泰来_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yuan_xw/article/details/51175171

 浙公网安备 33010602011771号
浙公网安备 33010602011771号