[apue] 进程环境那些事儿
![[apue] 进程环境那些事儿](https://img2023.cnblogs.com/blog/1707550/202308/1707550-20230829102027055-1196170961.png) atexit 注册的处理器中可以再调 atexit 或 exit 吗?putenv 或 setenv 增加一个环境变量后 environ 指针地址为什么变了?setjmp & longjmp 跨函数跳转后自动变量为什么回退了?设置 RLIMIT_NPROC 为 10 为何连一个子进程也 fork 不了?设置 RLIMIT_NOFILE 后为何 sysconf 的返回值也受到了影响?本文为你一一解答
atexit 注册的处理器中可以再调 atexit 或 exit 吗?putenv 或 setenv 增加一个环境变量后 environ 指针地址为什么变了?setjmp & longjmp 跨函数跳转后自动变量为什么回退了?设置 RLIMIT_NPROC 为 10 为何连一个子进程也 fork 不了?设置 RLIMIT_NOFILE 后为何 sysconf 的返回值也受到了影响?本文为你一一解答
main 函数与进程终止
众所周知,main 函数为 unix like 系统上可执行文件的"入口",然而这个入口并不是指链接器设置的程序起始地址,后者通常是一个启动例程,它从内核取得命令行参数和环境变量值后,为调用 main 函数做好安排。main 函数原型为:
int main (int argc, char *argv[]);这是 ISO C 和 POSIX.1 指义的,当然还存在下面几种不太标准的 main 原型:
void main (int argc, char *argv[]);
void main (void);
int main (void);不带 argc & argv 参数的表示不打算接受命令行参数;void 返回值的表示不打算返回一个结束状态。
进程的结束状态码与 main 的返回值关系如下:
- main 声明为 int 类型返回值
- main 结束前执行了 return x 语句:x
- main 结束前执行了无参数 return 语句:未定义 (warning: ‘return’ with no value, in function returning non-void)
- main 结束前执行了 exit(x) 函数:x
- main 结束前未执行以上语句:未定义 (warning: control reaches end of non-void function)
- main 结束前未执行以上语句 [-std=c99]:0
- main 声明为 void 类型返回值 (warning: return type of ‘main’ is not ‘int’)
- main 结束前执行了 return x 语句:未定义 (warning: ‘return’ with a value, in function returning void)
- main 结束前执行了无参数 return 语句:未定义
- main 结束前执行了 exit(x) 函数:x
- main 结束前未执行以上语句:未定义
测试机为 CentOS 7.9,gcc 版本 4.8.5,每一项的 warning 信息就是基于这两个版本测得。未定义的场景中,均返回 25 这个魔数。
开了 -std=c99 后大部分场景没有改善,仅 main 返回值被声明为 int 类型且在结束前没有调用任何 return 或 exit 时 (第 1 项第 4 小项) 发生了显著变化:从未定义变为返回 0。
进程有 8 种终止方式,其中 5 种为正常终止:
- 从 main 返回 (无论是否有返回值)
- 调用 exit
- 调用 _exit 或 _Exit
- 最后一个线程从其启动例程返回
- 最后一个线程调用 pthread_exit
另有 3 种为异常终止:
- 调用 abort
- 接到一个信号并终止
- 最后一个线程对取消请求做出响应
下面重点看一下 3 个 exit 函数:
#include <unistd.h>
void _exit(int status);
#include <stdlib.h>
void exit(int status);
void _Exit(int status);声明差别不大,_exit 与 _Exit 分别是 POSIX.1 与 ISO C 的标准,不过可以将它们视为等价,都直接进入内核。exit 则在它们的基础上做了一些清理工作,主要包含以下几个方面:
- 清理线程局部存储 (TLS) 信息
- 按顺序调用注册的终止处理程序
- 为所有标准 I/O 库打开的流调用 fclose 函数,这会 flush 缓冲的输出数据
关于标准 I/O 库,请参考之前写的这篇文章:《[apue] 标准 I/O 库那些事儿 》。
有了上面的铺垫,可以这样理解可执行程序的启动例程与 main 之间的关系:
...
exit (main (argc, argv));即 main 的返回值是直接传递给 exit 的 status 参数作为进程结束状态的。
atexit
关于终止处理程序,一般通过 atexit 函数进行注册:
#include <stdlib.h>
int atexit(void (*function)(void));这里的 function 参数就是希望在 exit 时被调用的清理程序,关于终止处理程序,有下面几点需要注意:
- 调用次数有上限,通过 sysconf (_SC_ATEXIT_MAX) 查询 (实测为 2147483647, 即 INT_MAX)
- FILO,先注册的后被调用,类似于堆栈,而非队列
- 调用次数等于注册次数,同一清理程序可多次注册,注册几次调用几次
- 执行 exec 函数族执行另一个程序的时候,自动清空 atexit 注册的清理程序
- 在清理程序中调用 exit "无效",如果调用 _exit 或 _Exit,会导致程序直接退出,后续清理程序不再被调用
- 进程异常终止时清理程序不会被调用
下面这个例子验证了调用次数与 FILO 特性:
#include "../apue.h"
void do_dirty_work ()
{
printf ("doing dirty works!\n");
}
void bye ()
{
printf ("bye, forks~\n");
}
void times ()
{
static int counter = 32;
printf ("times %d\n", counter--);
}
int main ()
{
int ret = 0;
ret = atexit (do_dirty_work);
if (ret != 0)
err_sys ("atexit");
ret = atexit (bye);
if (ret != 0)
err_sys ("bye1");
ret = atexit (bye);
if (ret != 0)
err_sys ("bye2");
for (int i=0; i<32; i++)
{
ret = atexit (times);
if (ret != 0)
err_sys ("times");
}
printf ("main is done!\n");
return 0;
}执行它会有如下输出:
$ ./atexit
main is done!
times 32
times 31
times 30
times 29
times 28
times 27
times 26
times 25
times 24
times 23
times 22
times 21
times 20
times 19
times 18
times 17
times 16
times 15
times 14
times 13
times 12
times 11
times 10
times 9
times 8
times 7
times 6
times 5
times 4
times 3
times 2
times 1
bye, forks~
bye, forks~
doing dirty works!在 bye 中增加一些 exit 调用,观察是否会有变化:
void bye ()
{
printf ("bye, forks~\n");
exit (2); // no effect
printf ("after exit (2)\n");
}结果与之前完全一致,不过进程结束状态变为了 2:
$ ./atexit
main is done!
times 32
...
times 1
bye, forks~
bye, forks~
doing dirty works!
> echo $?
2可见 exit 并非没有生效,一个合理的推断是:第二次进入 exit 后,继续处理之前没处理完的清理程序,使得输出看起来就像"没生效"一样。真正的 _exit 是被第二次进入 bye 的那个 exit 所调用,对程序稍加改动来看个明白:
int exit_status = 10;
void bye ()
{
printf ("bye, forks~\n");
exit (exit_status++); // no effect
printf ("after exit (%d)\n", exit_status-1);
}为了便于区别,这里给的初始值为 10,每调用一次 bye,exit_status 递增 1,如果最后进程结束状态码为 10 就证明是第一次 exit 结束了进程,否则就是第二次。
$ ./atexit
main is done!
times 32
...
times 1
bye, forks~
bye, forks~
doing dirty works!
> echo $?
11结论已经非常明显,之前的猜测成立!如此就可以合理的推断 exit 调用清理程序后,会将其从 FILO 结构中移除,从而避免再次调用,进而引发无限循环。
下面试试 _exit 的效果:
void bye ()
{
printf ("bye, forks~\n");
_exit (3); // quit and no other atexit function running anymore !
printf ("after _exit (3)\n");
}改为 _exit 后输出发生了截断:
$ ./atexit
main is done!
times 32
...
times 1
bye, forks~
$ echo $?
3进入 bye 处理程序后进程就终止了,后续的处理程序不再调用。检查进程结束状态码为 3,正好是 _exit 的 status 参数。
将上面 exit 和 _exit 全都打开后,_exit 反而不起作用了:
void bye ()
{
printf ("bye, forks~\n");
exit (2); // no effect
printf ("after exit (2)\n");
_exit (3); // no effect
printf ("after _exit (3)\n");
}经过上面的分析,想必读者已经知道了答案,正确的做法是将 _exit 放在 exit 前面,这样才能避免进入 exit 之后不再返回,从而被忽略。
最后再试一种场景,就是在处理器中继续调用 atexit 注册新的处理器,观察新的处理器是否能被调用,参考下面这个例子:
#include "../apue.h"
void do_dirty_work ()
{
printf ("doing dirty works!\n");
}
void bye ()
{
printf ("bye, forks~\n");
int ret = atexit (do_dirty_work);
if (ret != 0)
err_sys ("do_dirty_work");
}
int main ()
{
int ret = 0;
ret = atexit (bye);
if (ret != 0)
err_sys ("bye");
printf ("main is done!\n");
return 0;
}先注册处理器 bye,在其被回调时再注册处理器 do_dirty_work,结果是两个处理器都能被回调:
$ ./atexit_term
main is done!
bye, forks~
doing dirty works!如果注册的处理器形成循环会如何?参考下面的例子:
#include "../apue.h"
extern void bye ();
void do_dirty_work ()
{
printf ("doing dirty works!\n");
int ret = atexit (bye);
if (ret != 0)
err_sys ("bye2");
}
void bye ()
{
printf ("bye, forks~\n");
int ret = atexit (do_dirty_work);
if (ret != 0)
err_sys ("do_dirty_work");
}
int main ()
{
int ret = 0;
ret = atexit (bye);
if (ret != 0)
err_sys ("bye");
printf ("main is done!\n");
return 0;
}在 do_dirty_work 中再次注册 bye 作为处理器,重新编译后运行,发现程序果然陷入了死循环:
$ ./atexit_term
main is done!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
...
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!
bye, forks~
doing dirty works!^C直到输入 Ctrl+C 才能退出,看起来 atexit 并不能检测这种情况,需要程序员自己避免调用环的形成,好在这种场景并不多见。
命令行参数与环境变量
ISO C 与 POSIX.1 都要求 argv[argc] 参数为 NULL,因此下面两种遍历命令行参数的方式是等价的:
int i;
for (i=0; i<argc; ++ i)
...
for (i=0; argv[i]!=NULL; ++i)
...环境变量也有类似的约定。大多数 unix like 都支持以下的 main 声明:
int main (int argc, char* argv[], char* envp[]);将环境变量放在 main 第三个参数上,不过标准的 ISO C 和 POSIX.1 不支持,它们规定使用单独的全局变量访问环境变量:
extern char **environ; 由于没有类似 argc 的参数来说明参数表长度,环境变量的遍历只能依赖结尾 NULL 的方式。
环境变量
环境变量的内容通常为以下形式:
name=valuename 通常大写,不过这只是一种惯例,内核并不检查环境变量内容,它的解释完全取决于各个应用程序。例如 PATH 变量可以通过冒号指定多个路径:
PATH=/home/users/yunhai01/.local/bin:/home/users/yunhai01/bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/usr/bin:/opt/bin:/home/opt/bin:/usr/local/sbin:/usr/sbin:/opt/bin:/home/opt/binISO C & POSIX.1 定义了一组处理环境变量的函数:
#include <stdlib.h>
[ISO C/POSIX.1] char *getenv(const char *name);
[POSIX.1] int setenv(const char *name, const char *value, int overwrite);
[POSIX.1] int unsetenv(const char *name);
[XSI] int putenv(char *string);
[linux] int clearenv(void);它们属于的标准在函数声明前做了标识。其中:
- getenv 根据 name 参数查找变量并获取 value 部分返回给用户
- setenv 根据 name 参数查找变量
- 变量不存在,直接设置新的变量 name=value
- 变量存在
- overwrite == 0:保留原有变量不变,返回 0
- overwrite != 0:删除原有变量,设置新的变量 name=value
- unsetenv 删除 name 的定义,不存在也返回 0
- putenv 与 setenv 类似,不同的是
- string 参数本身是 name=value 的组合体
- 变量存在时删除,没有标志位可以控制覆盖行为
- setenv 需要分配新的存储区,因此不要求用户为 name & value 参数分配存储空间;putenv 则必需由用户分配
- clearenv 是 linux 平台的专有扩展,用于清空环境变量
关于增删改环境变量导致的空间变化问题,下一节详细说明。
最后需要说明的是,对环境变量的更改只对当前进程及之后启动的子进程生效,不对父进程及之前启动的子进程产生影响。
存储空间布局
直接上图:
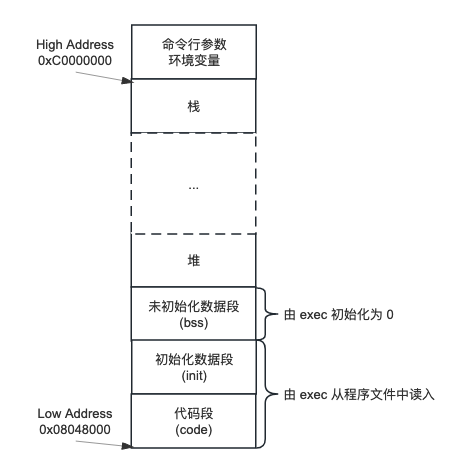
上面是一种典型的内存排布,只是举个例子,并不代表所有平台和架构都以此这种方式安排其存储空间,图中的内存地址更是以 Linux x86 处理器为例的。
其中:
- 代码段也称正文段,存储可执行程序的机器指令部分,一般是只读、共享的
- 初始化数据段也称为数据段,包含了程序中明确赋初值的全局或静态变量,以上两段从程序文件中读入
- 非初始化数据段也称为 bss (block started by symbol),没有初始化的全局或静态变量包含在这个段中。由于不需要保存初始化值,程序文件中甚至没有这个段,它是由 exec 初始化为 0 的
- 堆,动态存储分配区域,由低地址向高地址增长
- 栈,自动变量及函数调用所需的信息存放在此段。一个函数调用实例中的变量不会影响另一个函数调用实例中的变量。由高地址向低地址增长
- 命令行参数与环境变量存放在栈底以上的空间
其中除堆和栈外,其它段都变化很小或不变,所以设置堆和栈对向增长是非常聪明的做法。当向下增长的栈与向上增长的堆相遇时,进程的地址空间就用光了。
下面的程序验证了 C 程序的内存布局:
#include "../apue.h"
int data1 = 2;
int data2 = 3;
int data3;
int data4;
int main (int argc, char *argv[])
{
char buf1[1024] = { 0 };
char buf2[1024] = { 0 };
char *buf3 = malloc(1024);
char *buf4 = malloc(1024);
printf ("onstack %p, %p\n",
buf1,
buf2);
extern char ** environ;
printf ("env %p\n", environ);
printf ("arg %p\n", argv);
printf ("onheap %p, %p\n",
buf3,
buf4);
free (buf3);
free (buf4);
printf ("on bss %p, %p\n",
&data3,
&data4);
printf ("on init %p, %p\n",
&data1,
&data2);
printf ("on code %p\n", main);
return 0;
}在 linux 上编译运行:
$ ./layout
onstack 0x7ffe31b752a0, 0x7ffe31b74ea0
env 0x7ffe31b757b8
arg 0x7ffe31b757a8
onheap 0x1984010, 0x1984420
on bss 0x6066b8, 0x6066bc
on init 0x606224, 0x606228
on code 0x40179d虽然具体地址和书上讲的有出入,但是总体布局确实是 code -> init -> bss -> heap -> stack -> env / arg 的顺序没错。
size
size 命令用于报告可执行文件的 code/data/bss 段的长度:
$ size ./layout ./layout_s /bin/sh
text data bss dec hex filename
20073 2152 80 22305 5721 ./layout
802535 7292 11120 820947 c86d3 ./layout_s
905942 36000 22920 964862 eb8fe /bin/shdec/hex 列分别是三者加总后的十进制与十六进制长度。示例中 layout_s 是静态链接版本,可见使用共享库的动态链接在各个段的尺寸上都有明显缩减。
堆分配
栈的增长主要依赖函数调用层次的增加;堆的增长主要依赖以下存储器分配函数:
#include <stdlib.h>
void *malloc(size_t size);
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
void free(void *ptr);其中:
- malloc 分配 size 长度的存储区
- calloc 分配 nmemb*size 长度的存储区
- realloc 可更改以前分配区到 size 长度 (增加或减小)
对于新增的存储区
- calloc 初始值为 0
- malloc 和 realloc 初始值不确定
对于 realloc,新旧地址之间的关系:
- 当存储区减小时,新旧地址保持一致
- 当存储区增加时
- 原存储区后有足够的空间时,新旧地址保持一致
- 原存储区后没有足够的空间,新旧地址不同,会先分配足够大的空间,复制数据,再释放原存储区
realloc(NULL, size) 等价于 malloc(size)。
sbrk
这些分配例程通常用 sbrk 系统调用来扩充进程的堆:
#include <unistd.h>
void *sbrk(intptr_t increment);这通常是通过调用 program break 的位置来实现的,参考 man 这段说明:
DESCRIPTION
brk() and sbrk() change the location of the program break, which defines the end of the process's data segment (i.e., the pro‐
gram break is the first location after the end of the uninitialized data segment). Increasing the program break has the effect
of allocating memory to the process; decreasing the break deallocates memory.program break 就是 bss 段的结尾,参考上图应该就是堆底。
sbrk 也可以减小堆大小,不过大多数 malloc 和 free 的实现都不减小进程的存储空间,释放的空间可供以后再分配,但通常将它们保持在 malloc 池中而不返回给内核。
环境变量空间的变更
有上面内容的铺垫,就可以回顾下上一节中增删改环境变量对存储空间的影响了:
- 删除环境变量,之后的变量前移填补删除后的空位
- 修改环境变量
- 新值长度小于等于旧值,在原字符串空间中写入新值
- 新值长度大于旧值,在堆上分配新字符串空间并赋值,更新环境变量表中的指针使之指向新分配的字符串
- 新增环境变量
- 第一次新增环境变量,在堆上分配新的环境变量表,将原来的环境变量"复制"到新分配的环境变量表中,然后把新增的环境变量字符串放在表尾,再新增一个空指针放在最后,最后使用 environ 变量指向新分配的环境变量表,基本上就是将环境变量从栈顶搬到了堆中,不过大多数环境变量仍指向栈顶中分配的字符串而已
- 非第一次新增,使用 realloc 重新分配 environ 变量,以容纳新增加的环境变量
环境变量空间改变如此复杂,主要是因为它的大小被栈顶限制死了,没有办法扩容,当增加环境变量数目时,只能从栈顶搬到堆中。
下面的程序演示了这一过程:
#include "../apue.h"
void print_envs()
{
extern char **environ;
printf ("base %p\n", environ);
for (int i=0; environ && environ[i] != 0; ++ i)
{
printf ("[%p] %s\n", environ[i], environ[i]);
}
}
int
main (int argc, char *argv[])
{
print_envs ();
setenv ("HOME", "ME", 1);
printf ("\nafter set HOME:\n");
print_envs ();
setenv ("LOGNAME", "this is a very very long user name", 1);
printf ("\nafter set LOGNAME:\n");
print_envs ();
unsetenv ("PATH");
printf ("\nafter unset PATH:\n");
print_envs ();
setenv ("DISAPPEAR", "not exist before", 0);
printf ("\nafter set DISAPPEAR:\n");
print_envs ();
setenv ("ADDISION", "addision adding", 0);
printf ("\nafter set ADDISION:\n");
print_envs ();
return 0;
}程序比较简单,依次执行以下操作:add HOME -> add LOGNAME -> remove PATH -> add DISAPPEAR -> add ADDISION,每次操作后都打印整个环境变量表,以观察 environ 和各个环境变量的变化:
$ ./envpos
base 0x7fff15e16468
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17c5f] PATH=/home/yunh/.BCloud/bin:/home/users/yunhai01/.local/bin:/home/users/yunhai01/bin:/home/users/yunhai01/tools/bin:/home/users/yunhai01/project/android-ndk-r20:/usr/lib64/qt-3.3/bin:/usr/local/bin:/usr/bin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin:/usr/local/sbin:/usr/sbin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x7fff15e17e58] HOME=/home/users/yunhai01
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x7fff15e17e8a] LOGNAME=yunhai01
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos启动后先打印整个环境变量表,大概有 30 个环境变量。
after set HOME:
base 0x7fff15e16468
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17c5f] PATH=/home/yunh/.BCloud/bin:/home/users/yunhai01/.local/bin:/home/users/yunhai01/bin:/home/users/yunhai01/tools/bin:/home/users/yunhai01/project/android-ndk-r20:/usr/lib64/qt-3.3/bin:/usr/local/bin:/usr/bin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin:/usr/local/sbin:/usr/sbin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x16fc010] HOME=ME
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x7fff15e17e8a] LOGNAME=yunhai01
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos设置 HOME 变量,虽然新值长度小于旧值,这里仍然为新值在堆上分配了空间,看起来 linux 上的实现偷懒了。
after set LOGNAME:
base 0x7fff15e16468
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17c5f] PATH=/home/yunh/.BCloud/bin:/home/users/yunhai01/.local/bin:/home/users/yunhai01/bin:/home/users/yunhai01/tools/bin:/home/users/yunhai01/project/android-ndk-r20:/usr/lib64/qt-3.3/bin:/usr/local/bin:/usr/bin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin:/usr/local/sbin:/usr/sbin:/opt/bin:/home/opt/bin:/home/users/yunhai01/tools/node-v14.17.0-linux-x64/bin
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x16fc010] HOME=ME
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x16fc060] LOGNAME=this is a very very long user name
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos设置 LOGNAME 变量,新值长度大于旧值,这里没有悬念的在堆上进行了分配。
after unset PATH:
base 0x7fff15e16468
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x16fc010] HOME=ME
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x16fc060] LOGNAME=this is a very very long user name
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos删除 PATH 变量,这一步主要验证再次新增环境变量时,会不会重复利用已删除的空位,到目前为止 environ 指针地址 (0x7fff15e16468) 没有发生变化,仍位于栈顶之上。
after set DISAPPEAR:
base 0x16fc0d0
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x16fc010] HOME=ME
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x16fc060] LOGNAME=this is a very very long user name
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos
[0x16fc1e0] DISAPPEAR=not exist before增加 DISAPPEAR 变量,没有悬念的在堆上分配了空间,最大的变化在于 environ 指针变了!从栈顶之上移动了到了堆中 (0x16fc0d0),看起来之前删除 PATH 变量腾空的位置没有利用上。
after set ADDISION:
base 0x16fc0d0
[0x7fff15e17488] XDG_SESSION_ID=318004
[0x7fff15e1749e] HOSTNAME=yunhai.bcc-bdbl.baidu.com
[0x7fff15e174c1] SHELL=/bin/bash
[0x7fff15e174d1] TERM=xterm-256color
[0x7fff15e174e5] HISTSIZE=1000
[0x7fff15e174f3] SSH_CLIENT=172.31.23.41 52661 22
[0x7fff15e17514] ANDROID_SDK_ROOT=/home/users/yunhai01/android_sdk
[0x7fff15e17546] QTDIR=/usr/lib64/qt-3.3
[0x7fff15e1755e] QTINC=/usr/lib64/qt-3.3/include
[0x7fff15e1757e] SSH_TTY=/dev/pts/6
[0x7fff15e17591] USER=yunhai01
[0x7fff15e17c57] TMOUT=0
[0x7fff15e17de4] MAIL=/var/spool/mail/yunhai01
[0x7fff15e17e02] PWD=/home/users/yunhai01/code/apue/07.chapter
[0x7fff15e17e30] LANG=en_US.UTF-8
[0x7fff15e17e41] HISTCONTROL=ignoredups
[0x16fc010] HOME=ME
[0x7fff15e17e72] SHLVL=2
[0x7fff15e17e7a] GTAGSFORCECPP=1
[0x16fc060] LOGNAME=this is a very very long user name
[0x7fff15e17e9b] QTLIB=/usr/lib64/qt-3.3/lib
[0x7fff15e17eb7] SSH_CONNECTION=172.31.23.41 52661 10.138.62.136 22
[0x7fff15e17eea] LESSOPEN=||/usr/bin/lesspipe.sh %s
[0x7fff15e17f0d] ANDROID_NDK_HOME=/home/users/yunhai01/project/android-ndk-r20
[0x7fff15e17f4b] XDG_RUNTIME_DIR=/run/user/383278
[0x7fff15e17f6c] LLVM_HOME=/home/users/yunhai01/project/ndk-llvm
[0x7fff15e17f9c] HISTTIMEFORMAT=%Y-%m-%d %H:%M:%S
[0x7fff15e17fbe] OLDPWD=/home/users/yunhai01/code/apue
[0x7fff15e17fe4] _=./envpos
[0x16fc1e0] DISAPPEAR=not exist before
[0x16fc240] ADDISION=addision adding增加 ADDISION 变量,仍然在堆上分配空间,而且 environ 指针地址 (0x16fc0d0) 没有发生变化,看起来仍有足够的空间让 realloc 分配。
指令跳转 (setjmp & longjmp)
说到指令跳转,第一印象就是 goto。由于程序的执行本质是一条条机器代码的执行,有些指令本身自带跳转属性,像函数调用 (call)、函数返回 (return) 、switch-case 都是某种形式的指令跳转,goto 则将这种能力公布给了开发者,然而下面的两个限制导致它在实际应用上的推广受阻:
- 只能在函数内部跳转,无法跨越函数栈
- 滥用 goto 导致代码逻辑不清晰、后期维护困难
setjmp & longjmp 完美的解决了上述 goto 的缺点,支持跨函数栈的跳转、且使用上更不易被滥用,也被称为非局部 goto。
它的跳转逻辑和现代 C++ 的异常机制已经非常相似了,区别是后者加入了对栈上对象析构函数的自动调用等更多的内容。
先来看函数原型:
#include <setjmp.h>
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);书上给的例子就不错,这里找到另外一个更简单的例子:
#include <setjmp.h>
#include <stdio.h>
static jmp_buf g_jmpbuf;
void exception_jmp()
{
printf ("throw_exception_jmp start.\n");
longjmp(g_jmpbuf, 1);
printf ("throw_exception_jmp end.\n");
}
void call_jmp()
{
exception_jmp();
}
int main(int argc, char *argv[])
{
/* using setjmp and longjmp */
if (setjmp(g_jmpbuf) == 0)
{
call_jmp();
}
else
{
printf ("catch exception via setimp-longjmp.\n");
}
return 0;
}编译运行这个 demo,输出如下:
throw_exception_jmp start.
catch exception via setimp-longjmp.对于没有接触过非局部 goto 的人来说还是比较直观的。
compiler explorer
这里推荐一个在线的 c++ 编译器 compiler explorer,对于没有 Linux 环境的人来说非常友好,下面是编译运行上述 demo 的过程:

可以看到这个工具非常强大,可以:
- 选择编译语言
- 选择编译器
- 选择编译模式 (是否开启 Vim)
- 修改编译链接选项
- 查看反汇编
- 查看预处理结果
- 查看运行输出
- 更改窗口布局
有兴趣的读者可以自行探索。
回归代码,注意 longjmp 第二个参数,这个不是随便给的,它将作为跳转后 setjmp 的返回值,要与初始化时返回的 0 有一些区别,另外允许任意多个 longjmp 跳向同一个 jmp_buf 实例,这种情况下,通过指定不同的 val 参数也能区别出跳转源,是不是想的很周到?
longjmp 跳转时,当前所在的函数栈到 setjmp 之间的栈将被回收,依附之上的自动变量将不复存在,但是跳转目的地所在的栈帧还是存在的,此外还有不在当前栈上的全局变量、静态变量等等也是存在的。
变量值回退
虽然没读过 setjmp & longjmp 的源码,但原理应该就是存储和恢复函数栈 (各种寄存器),那这些未被撤销的变量,是恢复到 setjmp 时的状态,还是保留最后的状态呢?对上面的例子稍加修改来进行一番考察:
#include <setjmp.h>
#include <stdio.h>
static jmp_buf g_jmpbuf;
static int globval;
void exception_jmp()
{
printf ("throw_exception_jmp start.\n");
longjmp(g_jmpbuf, 1);
printf ("throw_exception_jmp end.\n");
}
void call_jmp(int i, int j, int k, int l)
{
printf ("in call_jmp (): \n"
"globval = %d,\n"
"autoval = %d,\n"
"regival = %d,\n"
"volaval = %d,\n"
"statval = %d\n\n",
globval,
i,
j,
k,
l);
exception_jmp();
}
int main(int argc, char *argv[])
{
int autoval;
register int regival;
volatile int volaval;
static int statval;
globval = 1;
autoval = 2;
regival = 3;
volaval = 4;
statval = 5;
/* using setjmp and longjmp */
if (setjmp(g_jmpbuf) == 0)
{
/*
* Change variables after setjmp, but before longjmp
*/
globval = 95;
autoval = 96;
regival = 97;
volaval = 98;
statval = 99;
call_jmp(autoval, regival, volaval, statval);
}
else
{
printf ("catch exception via setimp-longjmp.\n");
printf ("in main (): \n"
"globval = %d,\n"
"autoval = %d,\n"
"regival = %d,\n"
"volaval = %d,\n"
"statval = %d\n\n",
globval,
autoval,
regival,
volaval,
statval);
}
return 0;
}在原来的基础上添加了几种类型的变量:
- globaval:全局变量
- autoval:main 栈上自动变量
- regival:main 栈上寄存器变量
- valaval:main 栈上易失变量
- statval:main 栈上静态变量
并分别在 call_jmp 内部和 longjmp 后 (第二次从 setjmp 返回) 时打印它们的值:
$ ./jumpvar
in call_jmp ():
globval = 95,
autoval = 96,
regival = 97,
volaval = 98,
statval = 99
throw_exception_jmp start.
catch exception via setimp-longjmp.
in main ():
globval = 95,
autoval = 96,
regival = 97,
volaval = 98,
statval = 99在没开优化的情况下,各个变量都最新的状态,没有发生值回退现象,添加 -O 编译选项:
...
jumpvar: jumpvar.o apue.o
gcc -Wall -g $^ -o $@
jumpvar.o: jumpvar.c ../apue.h
gcc -Wall -g -c $< -o $@ -std=c99
jumpvar_opt: jumpvar_opt.o apue.o
gcc -Wall -g $^ -o $@
jumpvar_opt.o: jumpvar.c ../apue.h
gcc -Wall -g -c $< -o $@ -std=c99 -O
...再次运行:
$ ./jumpvar
in call_jmp ():
globval = 95,
autoval = 96,
regival = 97,
volaval = 98,
statval = 99
throw_exception_jmp start.
catch exception via setimp-longjmp.
in main ():
globval = 95,
autoval = 2,
regival = 3,
volaval = 98,
statval = 99这次 autoval 和 regival 的值发生了回退。加优化选项后为提高程序运行效率,这些变量的值从内存提升到了寄存器,从而导致恢复 main 堆栈时被一并恢复了。这里有几个值得注意的点:
- 声明为 register 的 regival 在未开启优化前编译器并没有遵循指令将其放置在寄存器,再一次证实了 register 关键字只是建议而非强制
- 开优化后,栈上的自动变量也被放置在了寄存器中
- 即使开优化,volatile 关键字声明的变量也不存在于寄存器中
所以最终的结论是:如果不想栈上的变量受 setjmp & longjmp 影响发生值回退,最好将它们声明为 volatile。
这里出于好奇,也使用 compiler explorer 运行了一把,结果没加优化的第一次运行输出就不一样:
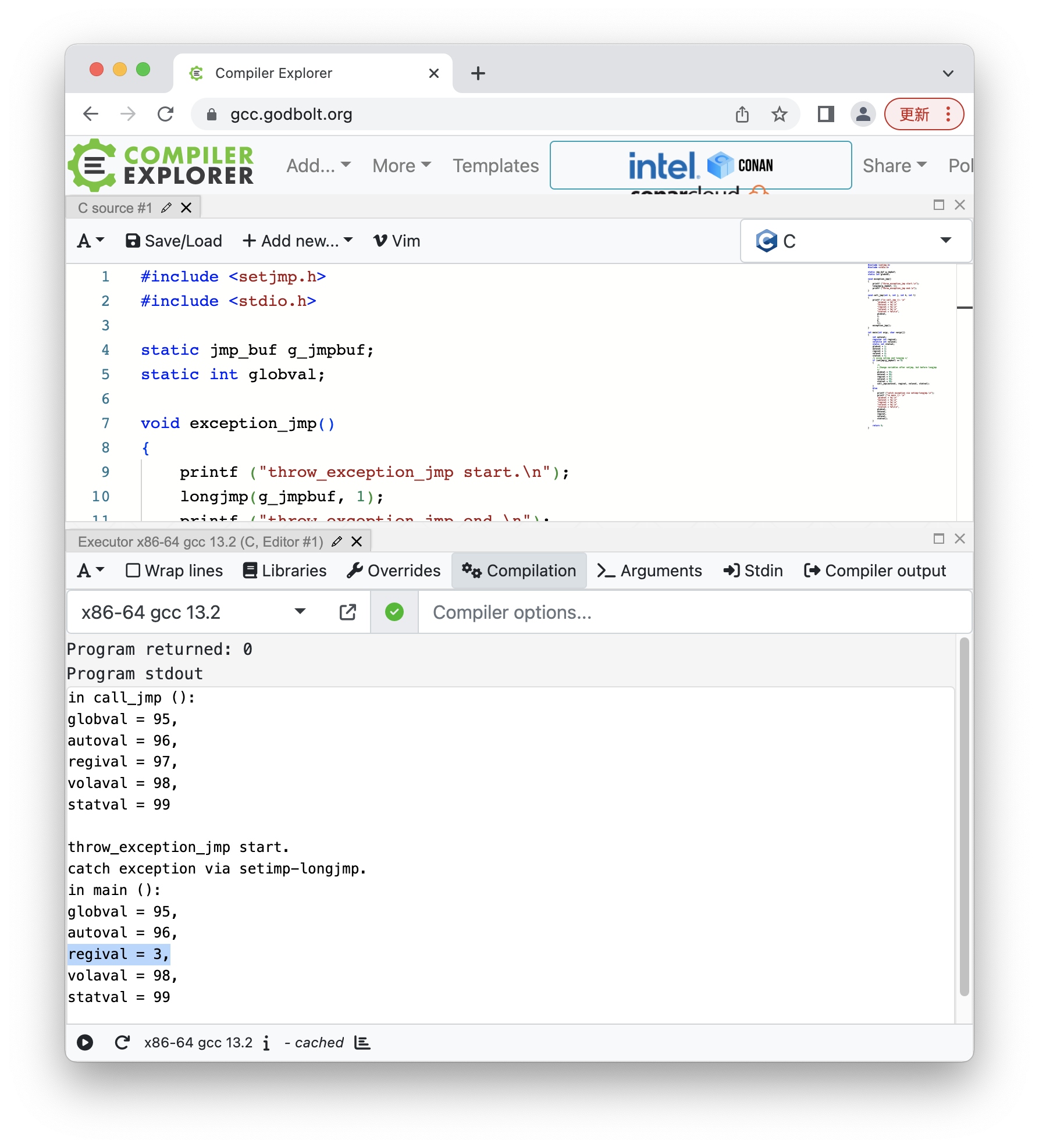
主要区别在于 regival 会回退,将 compiler explorer 中的 gcc 版本降到和我本地一样的 4.8.5 后输出就一致了,因此主要区别在于编译器版本。
这一方面展示了 compiler explorer 强大的切换编译器版本的能力,另一方面也显示高版本 gcc 版本器倾向于"相信"用户提供的 register 关键字。
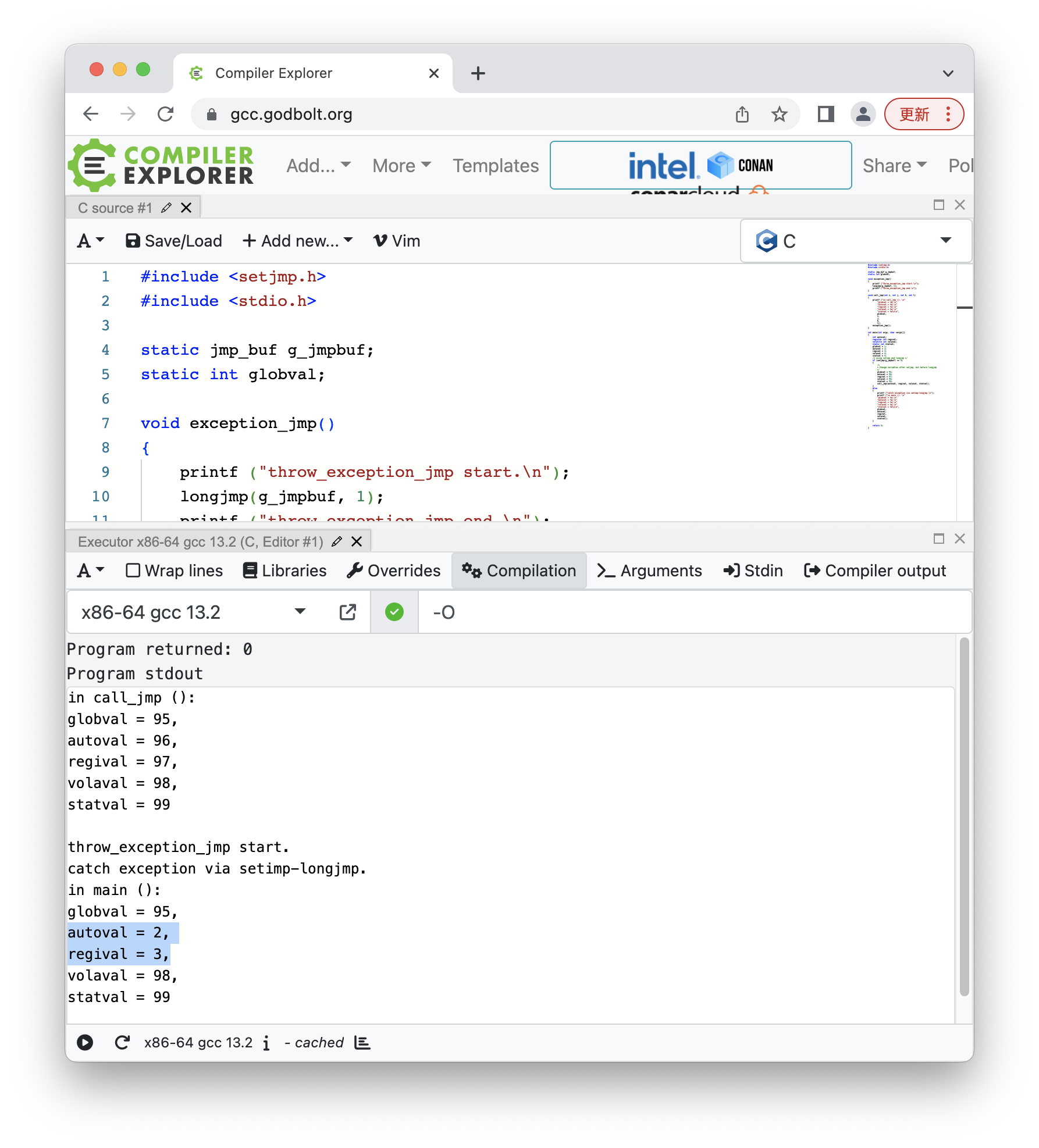
最后在 compiler explorer 中增加 -O 编译器参数,会得到和之前一样的结果:
资源限制 (getrlimit & setrlimit)
进程对系统资源的请求并不是没有上限的,使用 getrlimit 和 setrlimit 查询或更改它们:
#include <sys/resource.h>
// struct rlimit {
// rlim_t rlim_cur; /* Soft limit */
// rlim_t rlim_max; /* Hard limit (ceiling for rlim_cur) */
// };
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);resource 指定了限制的类型,rlim 则包含了资源限制的信息,主要包含两个成员:
- rlim_cur:软限制值,当前生效的限制值
- rlim_max:硬限制值,大于等于软限制值,软限制值的提升上限
- 任何用户可以降低硬限制值,只有超级用户可以提升硬限制值
- 每次降低的硬限制值必需大于等于软限制值
RLIM_INFINITY 表示无限量:
# define RLIM_INFINITY ((__rlim_t) -1)可以指定的资源限制类型及在本地环境上的软硬限制值列表如下:
| resource | 含义 | 软限制 | 硬限制 |
| RLIMIT_AS | 进程可用存储区的最大字节长度,会影响 sbrk & mmap 函数,非 Linux 平台也命名为 RLIMIT_VMEM | infinite | infinite |
| RLIMIT_CORE | 崩溃转储文件的最大字节数,0 表示阻止创建,生成的 core 文件大于限制值时会被截断 | 0 | infinite |
| RLIMIT_CPU | CPU 的最大量值,单位秒,超过软限制时,向进程发送 SIGXCPU 信号;超过硬限制时,向进程发送 SIGKILL 信号 | infinite | infinite |
| RLIMIT_DATA | 数据段的最大字节长度,是 init + bss + heap 的总长度,即除栈、环境变量、命令行参数外的内存总长度 | infinite | infinite |
| RLIMIT_FSIZE | 可以创建的文件的最大字节长度,当超过软限制时,向进程发送 SIGXFSZ 信号,若信号被捕获,则 write 返回 EBIG 错误 | infinite | infinite |
| RLIMIT_LOCKS | 一个进程可持有的文件锁的最大数量 (仅 Linux 支持) | infinite | infinite |
| RLMIT_MEMLOCK | 一个进程使用 mlock 能够锁定在存储器中的最大字节长度,当超过软限制时,mlock 返回 ENOMEM 错误 | 65536 | 65536 |
| RLIMIT_NOFILE | 每个进程能打开的最大文件数,当超过软限制时,open 返回 EMFILE 错误,更改软限制会影响 sysconf (_SC_OPEN_MAX) 返回的值 | 1024 | 4096 |
| RLIMIT_NPROC | 每个实际用户 ID 可拥有的最大进程数,当超过软限制时,fork 返回 EAGAGIN 错误,更改软限制会影响 sysconf (_SC_CHILD_MAX) 返回的值 | 4096 | 63459 |
| RLIMIT_RSS | 最大驻内存集的字节长度 (resident set size in bytes),如果物理内存不足,内核将从进程处取回超过 RSS 的部分 | infinite | infinite |
| RLMIT_SBSIZE | 用户任意给定时刻可以占用的套接字缓冲区的最大字节长度 (仅 FreeBSD 支持) | n/a | n/a |
| RLMIT_STACK | 栈的最大字节长度 | 8388608 | infinite |
限制值获取的 demo 就直接用书上提供的,感兴趣的读者可以查看原书,这里就不再列出了。
进程的资源限制通常是在系统初始化时由进程 0 建立的,然后由每个后续进程继承,对于其中非 RLIM_INFINITY 限制值的,进程终其一生无法提升限制值 (超级用户进程除外)。
shell 也提供相应的内置命令 (一般为 ulimit) 来修改默认的限制值,在启动命令前设置各种限制值才能在新进程中生效,在 CentOS 上使用 -a 选项可以查看所有的限制值:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 63459
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited大部分限制值与调用接口的 demo 打印的一致,但是单位可能和接口不同,使用时需要注意。
下面大体按上表的顺序对各个限制类型分别施加资源限制,观察程序的行为是否和预期一致。
RLIMIT_AS (RLIMIT_VMEM)
#include "../apue.h"
#include <sys/resource.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1024 * 1024;
lmt.rlim_max = RLIM_INFINITY;
ret = setrlimit (RLIMIT_AS, &lmt);
if (ret == -1)
err_sys ("set rlimit as failed");
char *ptr = malloc (1024 * 1024);
if (ptr == NULL)
err_sys ("malloc failed");
printf ("alloc 1 MB success!\n");
free (ptr);
}设置进程内存软限制 1M ,然后分配 1M 的堆内存:
$ ./lmt_as
malloc failed: Cannot allocate memory果然内存超限失败了。
RLIMIT_DATA
例子同上,只需将 RLIMIT_AS 修改为 RLIMIT_DATA 即可,输出也一致。
毕竟 RLIMIT_DATA 所包含的三个段 (init / bss / heap) 中有堆内存,通过分配堆内存肯定是会挤占这部分限制的。
RLIMIT_CORE
#include "../apue.h"
#include <sys/resource.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1024;
lmt.rlim_max = 102400;
ret = setrlimit (RLIMIT_CORE, &lmt);
if (ret == -1)
err_sys ("set rlimit core failed");
char *ptr = 0;
*ptr = 1;
return 0;
}设置崩溃转储文件软限制为 1K,在遭遇空指针崩溃后,能正常生成 core 文件:
$ ./lmt_core
Segmentation fault (core dumped)
$ ls -l core.22482
-rw------- 1 yunhai01 DOORGOD 1024 Aug 27 21:59 core.22482文件大小未超过 1K。当然前提是需要通过 ulimit -c 指定一个大于 1K 的数值 (非 root 用户),否则在 setrlimit 时会报错:
$ ./lmt_core
set rlimit core failed: Operation not permitted另外生成的 core 文件应该是被截断了,通过 gdb 加载过程日志可以判断:
$ gdb --core=./core.22482
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
"/home/users/yunhai01/code/apue/07.chapter/./core.22482" is not a core dump: File truncated
(gdb)因此也是不能用的。最后补充一点,设置 core 文件的最小尺寸必需大于 1,否则不会生成任何 core 文件。
RLIMIT_CPU
#include "../apue.h"
#include <sys/resource.h>
void sigxcpu_handler (int sig)
{
printf ("ate SIGXCPU...\n");
signal (SIGXCPU, sigxcpu_handler);
}
int main (int argc, char *argv[])
{
int ret = 0;
signal (SIGXCPU, sigxcpu_handler);
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1;
lmt.rlim_max = 5;
ret = setrlimit (RLIMIT_CPU, &lmt);
if (ret == -1)
err_sys ("set rlimit cpu failed");
int i = 1, j = 1;
while (1)
{
i *= j++;
}
return 0;
}设置了 CPU 软限制为 1 秒,硬限制为 5 秒,且捕获 SIGXCPU 信号,之后进入一个计算死循环,不停消耗 CPU 时间:
$ ./lmt_cpu
ate SIGXCPU...
ate SIGXCPU...
ate SIGXCPU...
ate SIGXCPU...
Killed日志几乎是一秒输出一行,第 5 秒时达到 CPU 硬限制,进程被强制杀死。
RLIMIT_FSIZE
#include "../apue.h"
#include <sys/resource.h>
#include <sys/file.h>
void sigxfsz_handler (int sig)
{
printf ("ate SIGXFSZ...\n");
signal (SIGXFSZ, sigxfsz_handler);
}
int main (int argc, char *argv[])
{
int ret = 0;
signal (SIGXFSZ, sigxfsz_handler);
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1024;
lmt.rlim_max = RLIM_INFINITY;
ret = setrlimit (RLIMIT_FSIZE, &lmt);
if (ret == -1)
err_sys ("set rlimit fsize failed");
int fd = open ("core.tmp", O_RDWR | O_CREAT, 0644);
if (fd == -1)
err_sys ("open file failed");
char buf[16];
int total = 0;
while (1)
{
ret = write (fd, buf, 16);
if (ret == -1)
err_sys ("write failed");
total += ret;
printf ("write %d, total %d\n", ret, total);
}
close (fd);
return 0;
}设置最大写入文件字节数软限制 1K,捕获 SIGXFZE 信号后打开 core.tmp 文件不停写入,每次写入 32 字节直到失败:
$ ./lmt_fsize
write 32, total 32
write 32, total 64
write 32, total 96
write 32, total 128
write 32, total 160
write 32, total 192
write 32, total 224
write 32, total 256
write 32, total 288
write 32, total 320
write 32, total 352
write 32, total 384
write 32, total 416
write 32, total 448
write 32, total 480
write 32, total 512
write 32, total 544
write 32, total 576
write 32, total 608
write 32, total 640
write 32, total 672
write 32, total 704
write 32, total 736
write 32, total 768
write 32, total 800
write 32, total 832
write 32, total 864
write 32, total 896
write 32, total 928
write 32, total 960
write 32, total 992
write 32, total 1024
ate SIGXFSZ...
write failed: File too large写满 1K 后收到了 SIGXFSZ 信号,捕获信号避免了进程 abort,不过 write 返回了 EBIG 错误。
这里需要注意不应使用 fopen/fclose/fwrite 来进行测试,因标准 I/O 库的缓存机制,导致写入的字节数大于实际落盘的字节数,从而得不到准确的限制值。
RLMIT_MEMLOCK
#include "../apue.h"
#include <errno.h>
#include <sys/resource.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 32 * 1024;
lmt.rlim_max = 64 * 1024;
ret = setrlimit (RLIMIT_MEMLOCK, &lmt);
if (ret == -1)
err_sys ("set rlimit memlock failed");
char *ptr = malloc (32 * 1024);
if (ptr == NULL)
err_sys ("malloc failed");
printf ("alloc 32K success!\n");
#define BLOCK_NUM 32
for (int i=0; i<BLOCK_NUM; ++ i)
{
ret = mlock (ptr + 1024 * i, 1024);
if (ret == -1)
err_sys ("mlock failed, %d", errno);
printf ("lock 1 KB success!\n");
}
for (int i=0; i<BLOCK_NUM; ++ i)
{
ret = munlock (ptr + 1024 * i, 1024);
if (ret == -1)
err_sys ("munlock failed, %d", errno);
printf ("unlock 1 KB success!\n");
}
free (ptr);
return 0;
}程序设置内存锁总长度软限制为 32K,硬限制 64K,分配 32K 内存后,在该内存上施加 32 个 1K 的范围锁:
$ ./lmt_memlock
alloc 32K success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
mlock failed, 12: Cannot allocate memory在达到 27K 左右时 mlock 报错了,没有达到 32K 的上限可能和 glibc 内部也有一些 mlock 调用有关。
如果将 1K 的块调整为 16 个,总的锁长度调整为 16K,再次运行 demo:
$ ./lmt_memlock
alloc 32K success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
lock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!
unlock 1 KB success!这回能成功。最后需要注意的是,默认 memlock 的上限是 64K,如果需要测试大于 64K 的场景,需要提前使用 ulimit 提升该限制。
RLIMIT_NOFILE
#include "../apue.h"
#include <sys/resource.h>
#include <sys/file.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 5;
lmt.rlim_max = 10;
ret = setrlimit (RLIMIT_NOFILE, &lmt);
if (ret == -1)
err_sys ("set rlimit nofile failed");
ret = sysconf (_SC_OPEN_MAX);
printf ("sysconf (_SC_OPEN_MAX) = %d\n", ret);
#define FD_SIZE 10
char filename[256] = { 0 };
int fds[FD_SIZE] = { 0 };
for (int i=0; i<FD_SIZE; ++ i)
{
sprintf (filename, "core.%02d.lck", i+1);
fds[i] = open (filename, O_RDWR | O_CREAT, 0644);
if (fds[i] == -1)
err_sys ("open file failed");
printf ("open file %s\n", filename);
}
for (int i=0; i<FD_SIZE; ++ i)
{
if (fds[i] != 0)
{
close (fds[i]);
}
}
return 0;
}设置打开文件数软限制为 5,硬限制为 10,之后创建 10 个文件 (core.xx.lck):
$ ./lmt_nofile
sysconf (_SC_OPEN_MAX) = 5
open file core.01.lck
open file core.02.lck
open file failed: Too many open files在打开第 3 个文件时失败,open 返回 EMFILE,这是由于程序本身的 stdin/stdout/stderr 会占用 3 个文件句柄,导致只剩下 2 个指标了。
值得注意的是在设置软限制后,sysconf 对应的返回值也变为 5 了。
RLIMIT_LOCKS
#include "../apue.h"
#include <sys/resource.h>
#include <sys/file.h>
void sigxfsz_handler (int sig)
{
printf ("ate SIGXFSZ...\n");
signal (SIGXFSZ, sigxfsz_handler);
}
int main (int argc, char *argv[])
{
int ret = 0;
signal (SIGXFSZ, sigxfsz_handler);
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1;
lmt.rlim_max = 1;
ret = setrlimit (RLIMIT_LOCKS, &lmt);
if (ret == -1)
err_sys ("set rlimit locks failed");
#define FD_SIZE 10
char filename[256] = { 0 };
int fds[FD_SIZE] = { 0 };
for (int i=0; i<FD_SIZE; ++ i)
{
sprintf (filename, "core.%02d.lck", i+1);
fds[i] = open (filename, O_RDWR | O_CREAT, 0644);
if (fds[i] == -1)
err_sys ("open file failed");
ret = flock (fds[i], LOCK_EX /*| LOCK_NB | LOCK_SH*/);
if (ret == -1)
err_sys ("lock file failed");
printf ("establish lock %2d OK\n", i+1);
}
for (int i=0; i<FD_SIZE; ++ i)
{
if (fds[i] != 0)
{
//flock (fds[i], LOCK_UN);
close (fds[i]);
}
}
return 0;
}在上一小节例子的基础上修改:设置文件锁数量软硬限制均为 1,在创建文件后为每个文件施加一个文件锁:
$ ./lmt_locks
establish lock 1 OK
establish lock 2 OK
establish lock 3 OK
establish lock 4 OK
establish lock 5 OK
establish lock 6 OK
establish lock 7 OK
establish lock 8 OK
establish lock 9 OK
establish lock 10 OK
$ ls -lh core.*
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.01.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.02.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.03.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.04.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.05.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.06.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.07.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.08.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.09.lck
-rw-r--r-- 1 yunhai01 DOORGOD 0 Aug 27 22:26 core.10.lck看起来没有生效,不清楚是否和文件长度为零有关,但是 flock 接口确实返回了成功,有功夫再研究。
RLIMIT_NPROC
#include "../apue.h"
#include <sys/resource.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 10;
lmt.rlim_max = 10;
ret = setrlimit (RLIMIT_NPROC, &lmt);
if (ret == -1)
err_sys ("set rlimit nproc failed");
#define PROC_SIZE 10
int pids[PROC_SIZE] = { 0 };
for (int i=0; i<PROC_SIZE; ++ i)
{
pids[i] = fork ();
if (pids[i] == -1)
err_sys ("fork failed");
if (pids[i] == 0)
{
printf ("child %d running\n", getpid ());
sleep (1);
exit (0);
}
printf ("create child %d\n", pids[i]);
}
sleep (1);
return 0;
}设置进程数软硬限制均为 10,启动 10 个子进程,如果算上本身已达到 11 个,所以肯定会有进程 fork 失败:
$ ./lmt_nproc
fork failed: Resource temporarily unavailable但没想到第一个子进程就创建失败了,又研究了一下 RLIMIT_NPROC 的含义——"每个实际 UID 用户拥有的最大进程数"——原来是用户维度的,并不是子进程维度的,所以还得看目前系统中存在的进程数:
$ ps -aux | grep yunhai01 | wc -l
259参考这个设置为 265,留 6 个余量,结果还是一样。直接调大到 512 ,这回倒是成功了,但是没法验证边界情况了,于是有了下面探索边界的代码:
#include "../apue.h"
#include <sys/resource.h>
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
int base = 10;
int success_cnt = 0;
#define PROC_SIZE 50
ret = sysconf (_SC_CHILD_MAX);
printf ("sysconf (_SC_CHILD_MAX) = %d\n", ret);
while (base < 1024 && base + PROC_SIZE < 1024)
{
printf ("============================\n");
printf ("detect with limit based %d\n", base);
lmt.rlim_cur = base;
lmt.rlim_max = 1024;
ret = setrlimit (RLIMIT_NPROC, &lmt);
if (ret == -1)
err_sys ("set rlimit nproc failed");
ret = sysconf (_SC_CHILD_MAX);
printf ("sysconf (_SC_CHILD_MAX) = %d\n", ret);
success_cnt = 0;
int pids[PROC_SIZE] = { 0 };
for (int i=0; i<PROC_SIZE; ++ i)
{
pids[i] = fork ();
if (pids[i] == -1)
{
if (success_cnt > 0)
err_sys ("fork failed");
else
{
err_msg ("fork failed");
break;
}
}
else if (pids[i] == 0)
{
printf ("child %d running\n", getpid ());
sleep (1);
exit (0);
}
printf ("create child %d\n", pids[i]);
success_cnt ++;
}
sleep (1);
if (base > PROC_SIZE)
base += PROC_SIZE;
else
base *= 2;
}
return 0;
}与之前相比,在外侧增加了一个循环,用于不停提升探索 RLIMIT_NPROC 的基数,初始时设置为 10,之后以指数方式递增,直到超过探查子进程数量 (PROC_SIZE),这之后每次增加的数量固定为 PROC_SIZE。
这样做的上的是在尽快定位边界的同时,保证一次探查能完全覆盖失败的情况,为此也将 PROC_SIZE 从 10 提升到了 50。
设置 RLIMIT_NPROC 时需注意保持硬限制不变 (1024),如果硬限制同软限制一同降低,后面就再也无法提升软限制。
最后增加了 sysconf(_SC_CHILD_MAX) 的调用,验证与 RLMIT_NPROC 的软限制设置是否同步:
$ ./lmt_nproc
sysconf (_SC_CHILD_MAX) = 4096
============================
detect with limit based 10
sysconf (_SC_CHILD_MAX) = 10
fork failed
============================
detect with limit based 20
sysconf (_SC_CHILD_MAX) = 20
fork failed
============================
detect with limit based 40
sysconf (_SC_CHILD_MAX) = 40
fork failed
============================
detect with limit based 80
sysconf (_SC_CHILD_MAX) = 80
fork failed
============================
detect with limit based 130
sysconf (_SC_CHILD_MAX) = 130
fork failed
============================
detect with limit based 180
sysconf (_SC_CHILD_MAX) = 180
fork failed
============================
detect with limit based 230
sysconf (_SC_CHILD_MAX) = 230
fork failed
============================
detect with limit based 280
sysconf (_SC_CHILD_MAX) = 280
fork failed
============================
detect with limit based 330
sysconf (_SC_CHILD_MAX) = 330
fork failed
============================
detect with limit based 380
sysconf (_SC_CHILD_MAX) = 380
create child 8623
create child 8624
create child 8625
child 8624 running
create child 8626
child 8625 running
create child 8627
child 8627 running
create child 8628
child 8628 running
create child 8629
child 8629 running
create child 8630
child 8630 running
create child 8631
child 8631 running
create child 8632
child 8632 running
create child 8633
child 8633 running
create child 8634
child 8634 running
create child 8635
child 8635 running
create child 8636
child 8623 running
create child 8637
child 8626 running
create child 8638
child 8637 running
create child 8639
child 8638 running
create child 8640
child 8639 running
create child 8641
child 8640 running
create child 8642
child 8641 running
create child 8643
child 8642 running
create child 8644
child 8643 running
create child 8645
fork failed: Resource temporarily unavailable
child 8644 running
child 8645 running
child 8636 running在限制值为 380 且创建了 22 个进程时出现 fork 失败,可以推算之前用户的进程数不到 360,这和 ps 输出的 259 差距不小,可能是 ps 选项没设置对的缘故。
另外 sysconf (_SC_CHILD_MAX) 的输出与软限制的设置基本同步,只是第一次调用它返回的 1024 看起来并不实用,因为在已有 360 个用户进程的情况下,只能再新建不到 700 个进程,与 sysconf 返回的 1024 差距还是比较大的。
可以推断这个返回值只是简单的将系统软限制返回,并没有参考当前的系统负载,使用时需谨慎。
最后补充一点,在 compiler explorer 中运行上面的程序,第一轮就可以覆盖到失败的场景:1
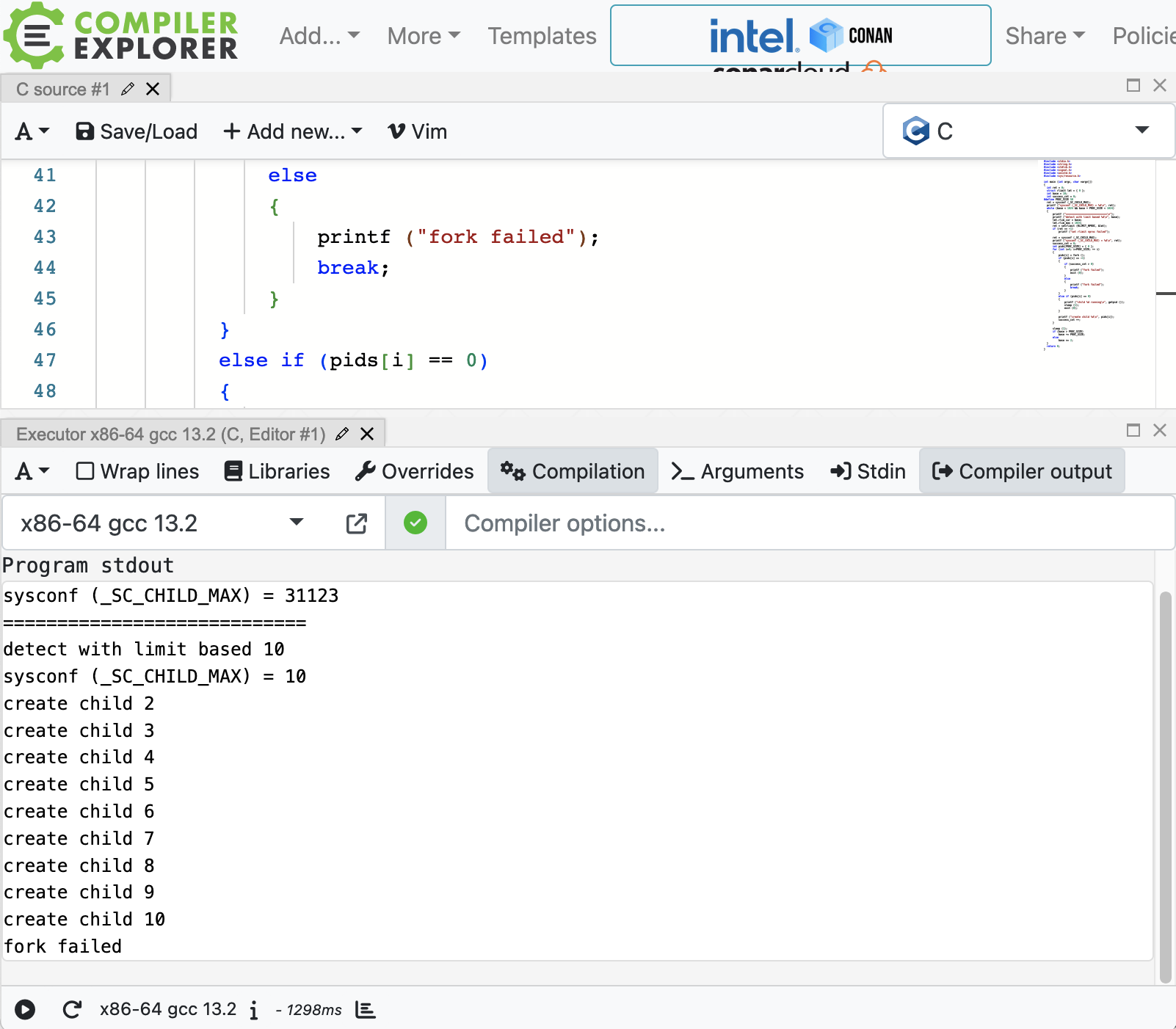
看起来使用的系统非常干净 ~
RLMIT_STACK
#include "../apue.h"
#include <sys/resource.h>
int stack_depth = 0;
void call_stack_recur ()
{
char buf[1024] = { 0 };
printf ("call stack %d\n", stack_depth++);
call_stack_recur ();
}
int main (int argc, char *argv[])
{
int ret = 0;
struct rlimit lmt = { 0 };
lmt.rlim_cur = 1024 * 10;
lmt.rlim_max = 1024 * 10;
ret = setrlimit (RLIMIT_STACK, &lmt);
if (ret == -1)
err_sys ("set rlimit stack failed");
call_stack_recur ();
return 0;
}设置软硬限制均为 10K,然后递归调用 call_stack_recur,后者栈上有一个 1K 大小的数组,理论上只能递归不到 10 次,demo 运行结果如下:
查看代码
$ ./lmt_stack
call stack 0
call stack 1
call stack 2
call stack 3
call stack 4
call stack 5
call stack 6
call stack 7
call stack 8
call stack 9
call stack 10
call stack 11
call stack 12
call stack 13
call stack 14
call stack 15
call stack 16
call stack 17
call stack 18
call stack 19
call stack 20
call stack 21
call stack 22
call stack 23
call stack 24
call stack 25
call stack 26
call stack 27
call stack 28
call stack 29
call stack 30
call stack 31
call stack 32
call stack 33
call stack 34
call stack 35
call stack 36
call stack 37
call stack 38
call stack 39
call stack 40
call stack 41
call stack 42
call stack 43
call stack 44
call stack 45
call stack 46
call stack 47
call stack 48
call stack 49
call stack 50
call stack 51
call stack 52
call stack 53
call stack 54
call stack 55
call stack 56
call stack 57
call stack 58
call stack 59
call stack 60
call stack 61
call stack 62
call stack 63
call stack 64
call stack 65
call stack 66
call stack 67
call stack 68
call stack 69
call stack 70
call stack 71
call stack 72
call stack 73
call stack 74
call stack 75
call stack 76
call stack 77
call stack 78
call stack 79
call stack 80
call stack 81
call stack 82
call stack 83
call stack 84
call stack 85
call stack 86
call stack 87
call stack 88
call stack 89
call stack 90
call stack 91
call stack 92
call stack 93
call stack 94
call stack 95
call stack 96
call stack 97
call stack 98
call stack 99
call stack 100
call stack 101
call stack 102
call stack 103
call stack 104
call stack 105
call stack 106
call stack 107
call stack 108
call stack 109
call stack 110
call stack 111
call stack 112
call stack 113
call stack 114
call stack 115
call stack 116
call stack 117
call stack 118
call stack 119
call stack 120
call stack 121
call stack 122
Segmentation fault (core dumped)却运行了 122 次之多,难道是 buf 数组被编译器优化了?调整 buf 尺寸为 5120,再次运行:
$ ./lmt_stack
call stack 0
call stack 1
call stack 2
call stack 3
call stack 4
call stack 5
call stack 6
call stack 7
call stack 8
call stack 9
call stack 10
call stack 11
call stack 12
call stack 13
call stack 14
call stack 15
call stack 16
call stack 17
call stack 18
call stack 19
call stack 20
call stack 21
call stack 22
call stack 23
call stack 24
Segmentation fault (core dumped)尺寸变大 5 倍,递归次数减少为 1/5 左右,应该是生效的。最终的结果是限制值的 12 倍之多,没有限制住。
使用 compiler explorer 运行上面的 demo,事情有些不同:

首先需要的起始内存比较大,500K,其次递归的数量没那么多,不到 300 次。可以对 compiler explorer 使用的系统做如下合理推测:
- 系统需要的栈空间更大,小于 500K 无法运行 demo
- 对 RLIMIT_STACK 的限制控制更精准了,且其它地方有消耗栈空间,导致实际可递归的次数大大下降
其它
现代 linux 除了书上列的这些,还有其它许多方面的限制 (例如限制消息队列的 RLIMIT_MSGQUEUE),这里就不一一列举了,感兴趣的可以参考 setrlimit 的 man 手册页。
另外表中的 RLIMIT_RSS 并没有验证,因为这需要一种极端内存紧张的系统环境,不太好搭建。
RLMIT_SBSIZE 仅在 FreeBSD 上有效,Linux 是通过套接字接口设置底层 buffer 大小的,而系统层级的缓冲大小限制是通过 proc 文件系统来查看和修改的。
结语
进程环境的核心还是这张内存布局图,有必要再复习一下:
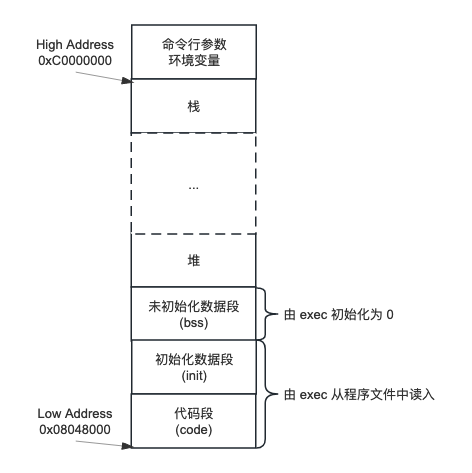
从这里可以看到程序的各个段是如何排布的,就可以:
- 了解栈与堆的对向生长
- 了解环境变量新增的难点
- 了解 setjmp & longjmp 跳转时栈上自动变量的回退
- 了解内存资源限制的三个方面
- 总内存:RLIMIT_AS (RLIMIT_VMEM)
- 栈空间:RLIMIT_STACK
- 堆+bss+init:RLIMIT_DATA
参考
[1]. C/C++ 异常处理之 01:setjmp 和 longjmp
[2]. compiler explorer
本文来自博客园,作者:goodcitizen,转载请注明原文链接:https://www.cnblogs.com/goodcitizen/p/things_about_process_environment.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号