
Java眼中的XML--文件读取--1 应用DOM方式解析XML
初次邂逅XML:

需要解析的XML文件:

这里有两个book子节点。
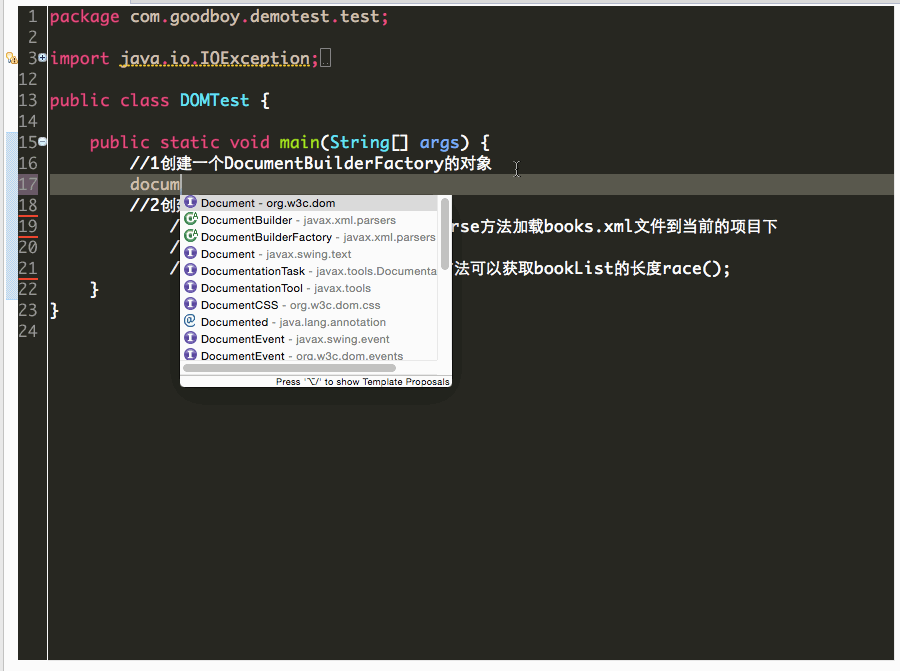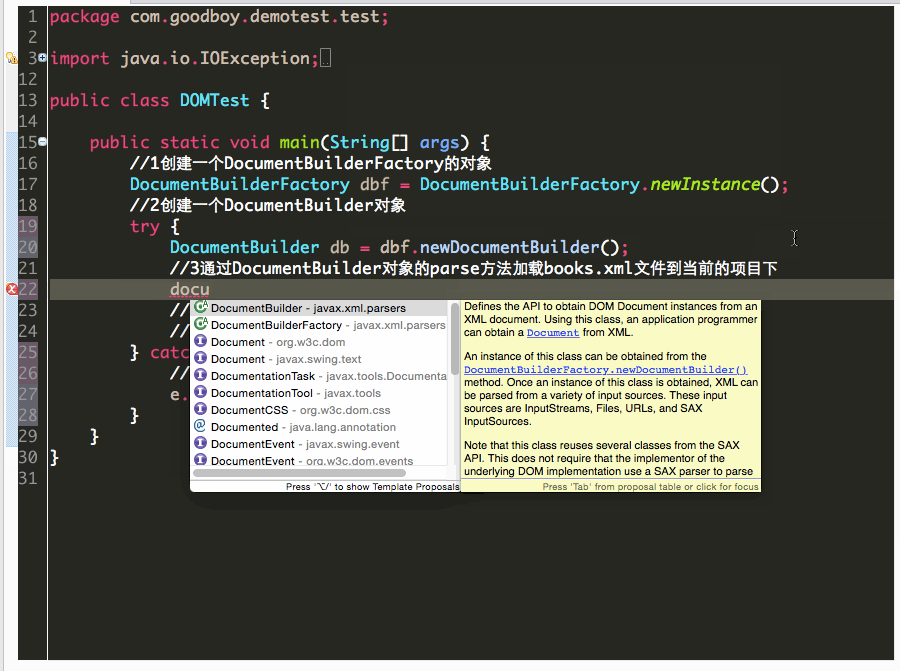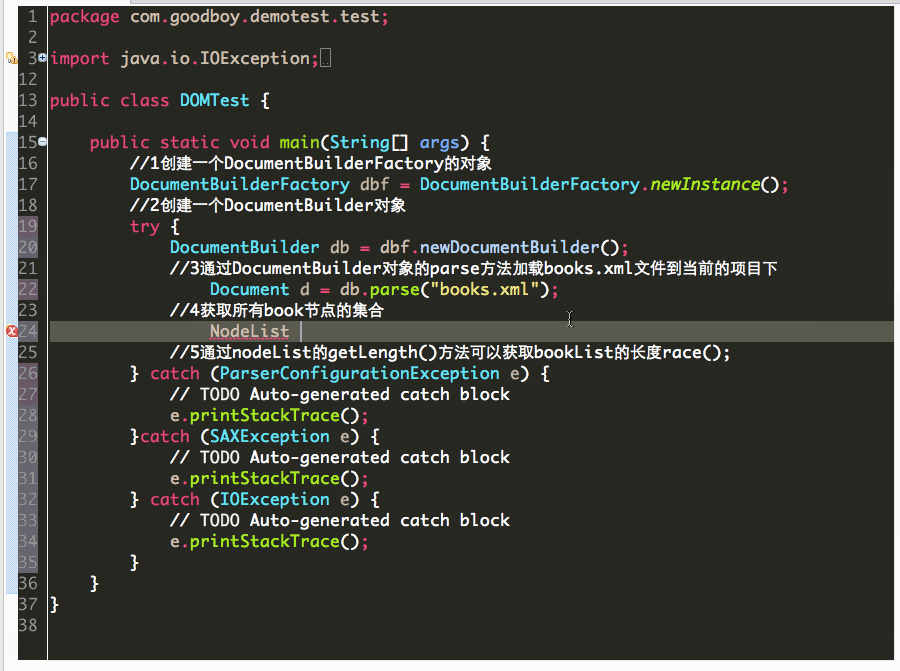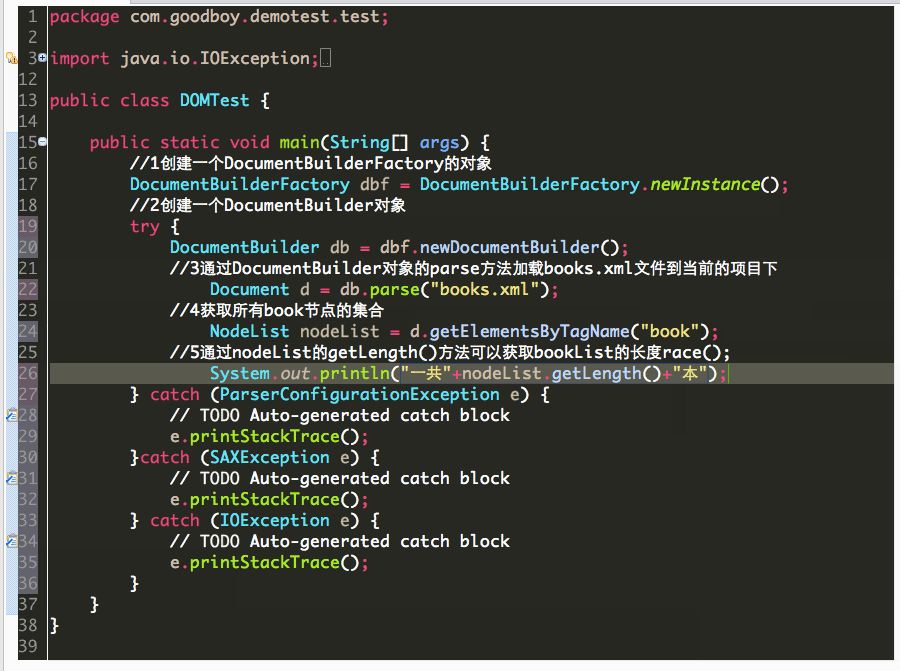
1、如何进行XML文件解析前的准备工作,另外解析先获取book节点。
这个我后来看懂了:

这个Node的ELEMENT_NODE=1和上面是一样的。

2、使用DOM解析XML文件的属性名和属性值(分两种情况)
第一种,当属性个数是1~N个的时候:



1 public class DOMTest { 2 3 public static void main(String[] args) { 4 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 5 try { 6 DocumentBuilder db = dbf.newDocumentBuilder(); 7 Document d = db.parse("books.xml"); 8 //1、根据节点名book,获取节点集合 9 NodeList nodelist = d.getElementsByTagName("book"); 10 //2、遍历集合中所有的元素(节点) 11 for (int i = 0; i < nodelist.getLength(); i++) { 12 Node node = nodelist.item(i); 13 //3、获取每个节点的属性集合,并输出属性的个数 14 NamedNodeMap attrMap = node.getAttributes(); 15 System.out.println("属性的个数是:"+attrMap.getLength()); 16 //4、遍历所有属性,并输出属性值 17 for (int j = 0; j < attrMap.getLength(); j++) { 18 Node attr = attrMap.item(j); 19 System.out.println(attr.getNodeName()+":"+attr.getNodeValue()); 20 } 21 } 22 } catch (ParserConfigurationException e) { 23 // TODO Auto-generated catch block 24 e.printStackTrace(); 25 } catch (SAXException e) { 26 // TODO Auto-generated catch block 27 e.printStackTrace(); 28 } catch (IOException e) { 29 // TODO Auto-generated catch block 30 e.printStackTrace(); 31 } 32 } 33 }
第二种,当节点属性值只有一个的时候,可以这样:
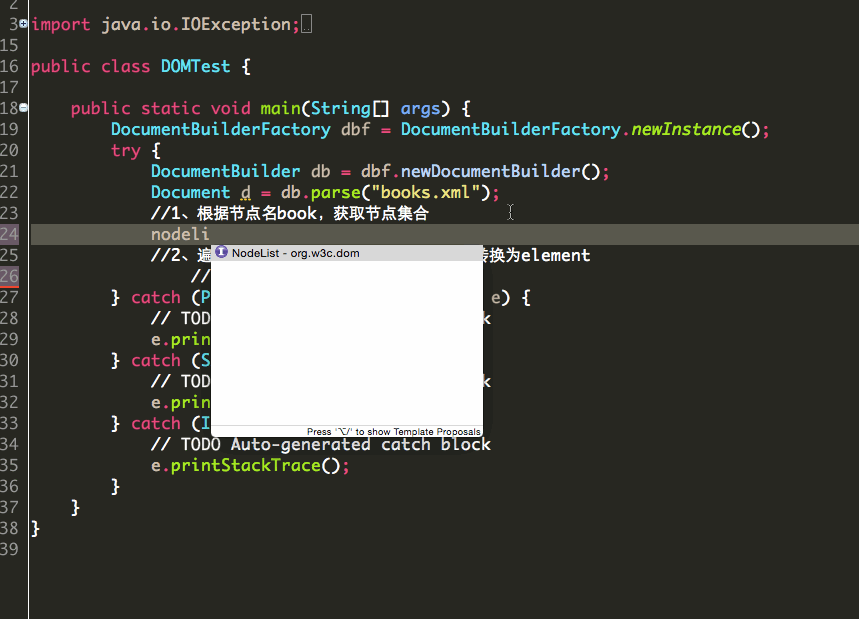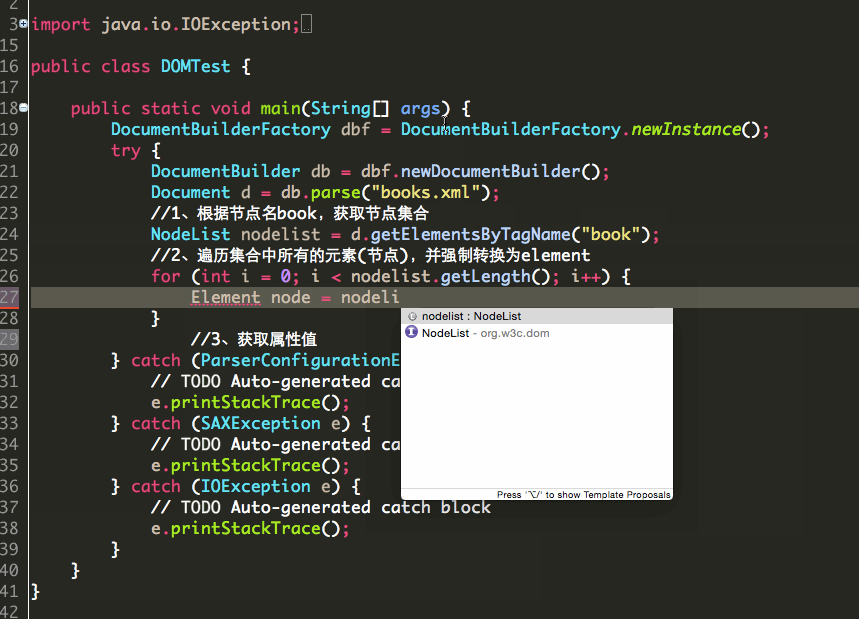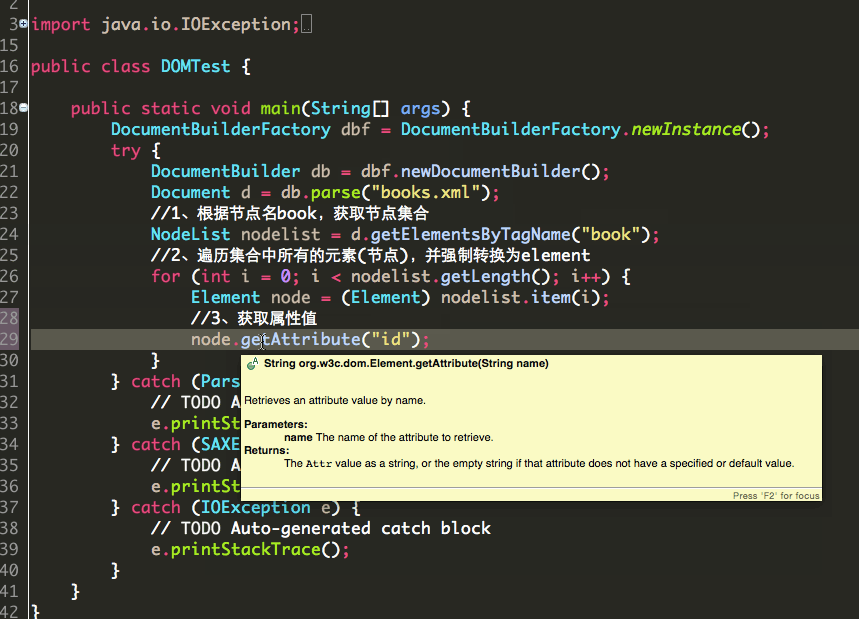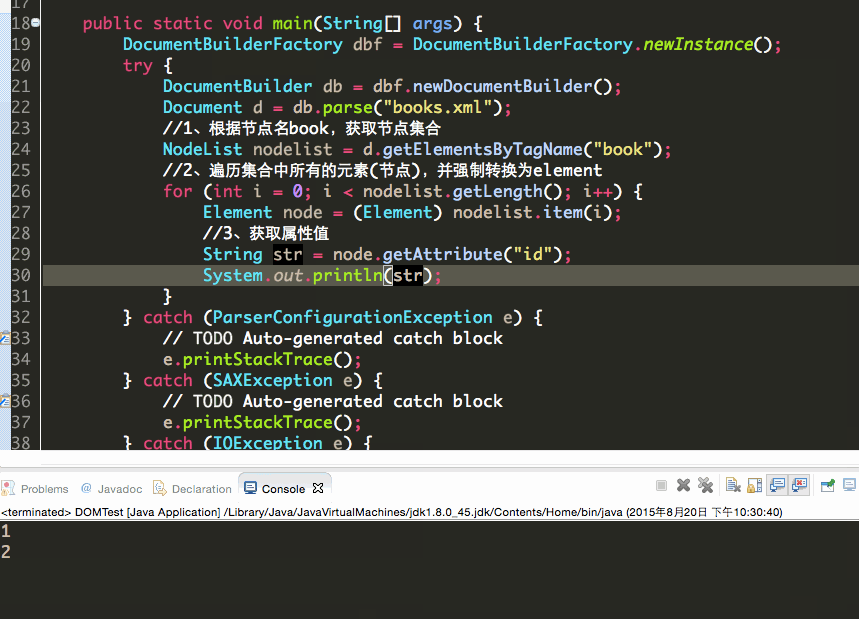
1 public class DOMTest { 2 3 public static void main(String[] args) { 4 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 5 try { 6 DocumentBuilder db = dbf.newDocumentBuilder(); 7 Document d = db.parse("books.xml"); 8 //1、根据节点名book,获取节点集合 9 NodeList nodelist = d.getElementsByTagName("book"); 10 //2、遍历集合中所有的元素(节点),并强制转换为element 11 for (int i = 0; i < nodelist.getLength(); i++) { 12 Element node = (Element) nodelist.item(i); 13 String str = node.getAttribute("id"); 14 System.out.println(str); 15 } 16 } catch (ParserConfigurationException e) { 17 // TODO Auto-generated catch block 18 e.printStackTrace(); 19 } catch (SAXException e) { 20 // TODO Auto-generated catch block 21 e.printStackTrace(); 22 } catch (IOException e) { 23 // TODO Auto-generated catch block 24 e.printStackTrace(); 25 } 26 } 27 }
上面两种情况的对比归纳,理解的时候,脑子里要有XML节点的图:
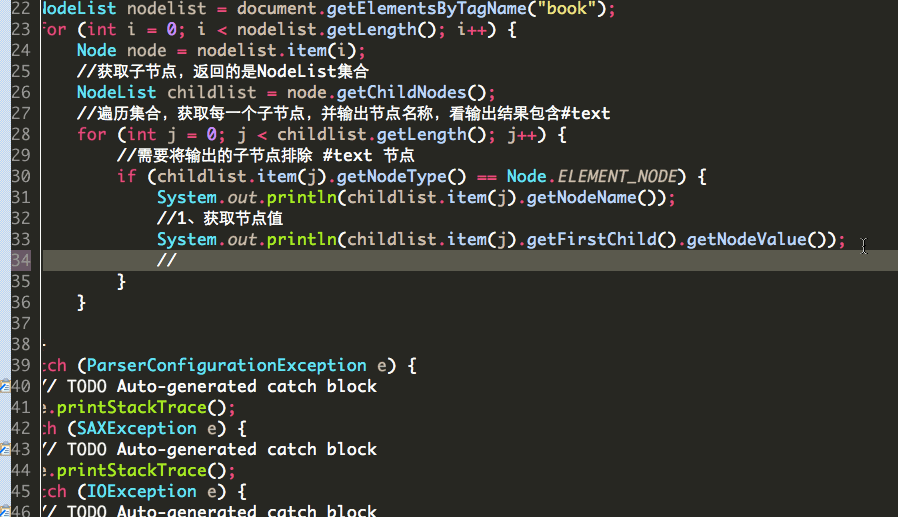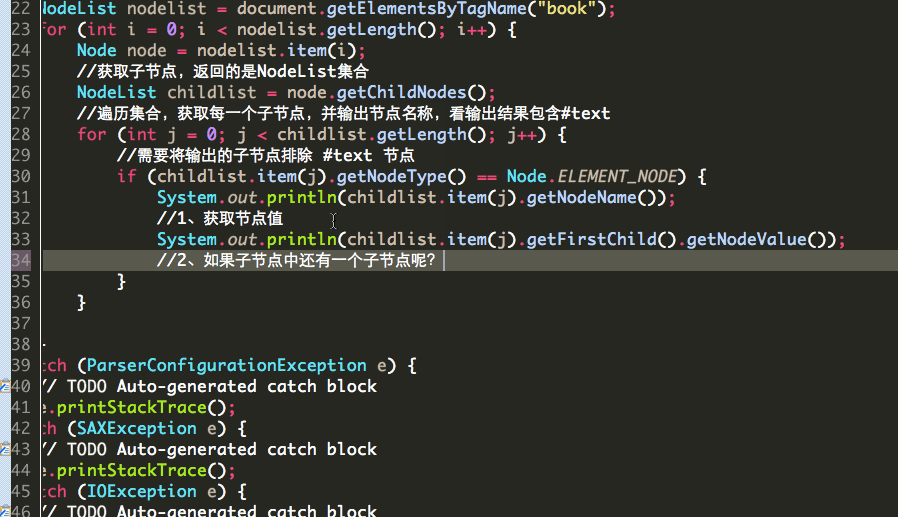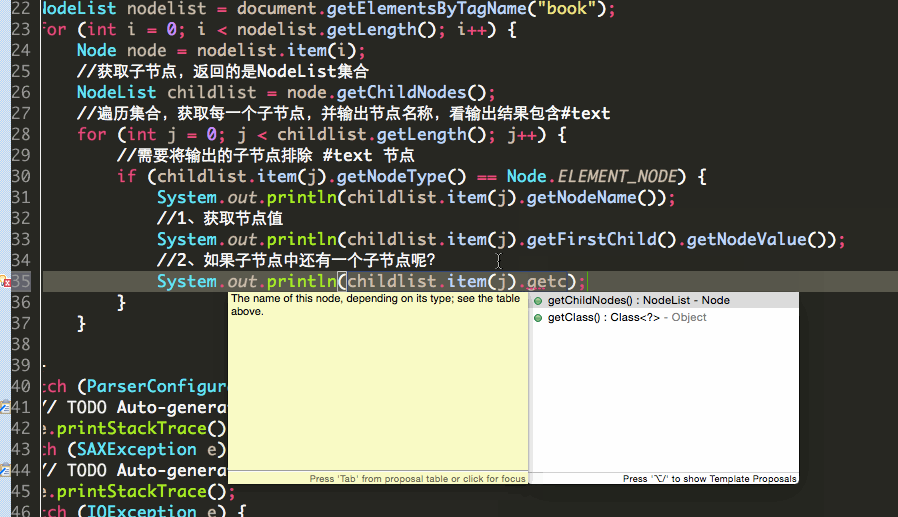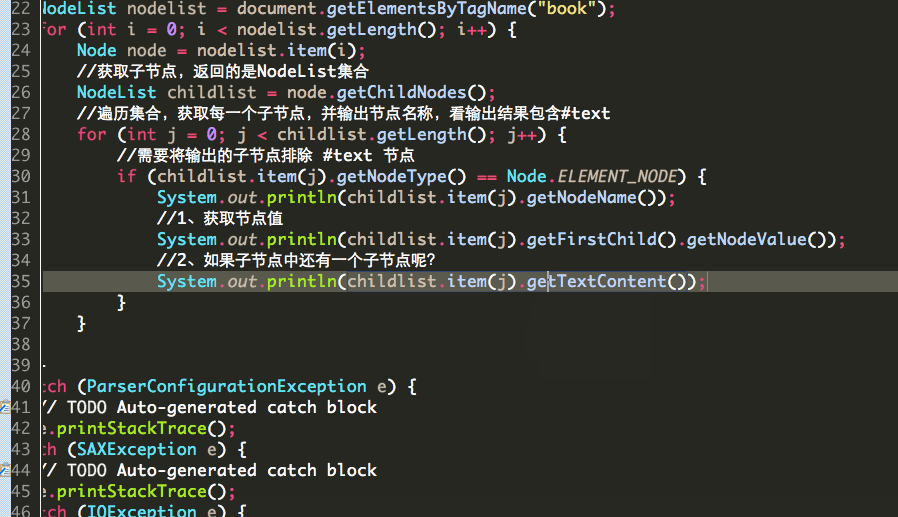
3、使用DOM解析XML文件的节点名和节点值
再来看XML的代码:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <bookstore> 3 <book id="1"> 换行符算一个子节点,这里是第一个 4 <name>冰与火之歌</name> 第二个换行符 5 <author>乔治马丁</author> 第三个 6 <year>2014</year> 第四个 7 <price>89</price> 第五个,所以加上正儿八经的四个节点,一共9个子节点 8 </book> 9 <book id="2"> 10 <name>安徒生童话</name> 11 <year>2004</year> 12 <price>77</price> 13 <language>English</language> 14 </book> 15 </bookstore>
下面进行解析子节点:
获取节点名

获取节点值:
因为一个节点转为Element类型之后,比如<name>冰火之歌</name>中,冰火之歌就不是该节点的值NodeValue而是该节点的子节点。
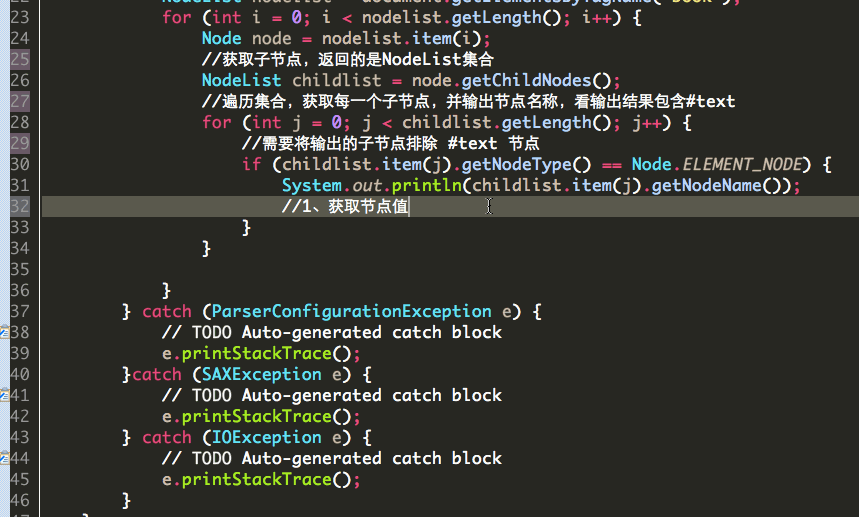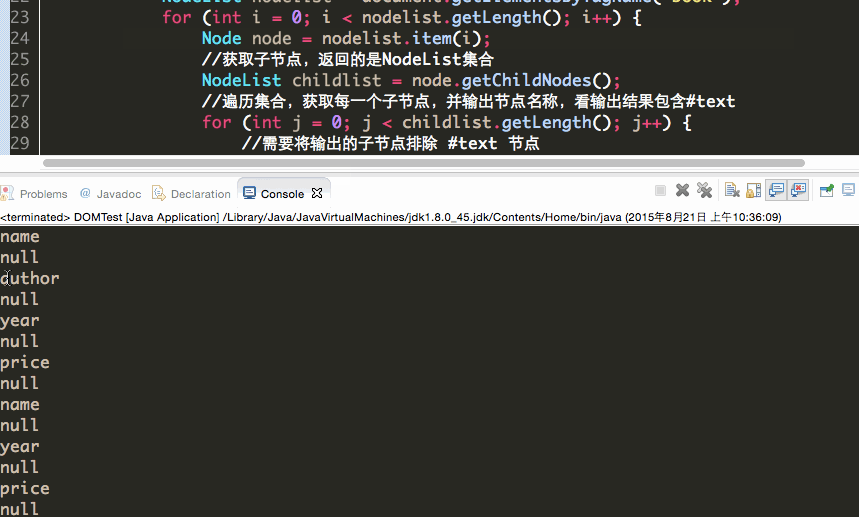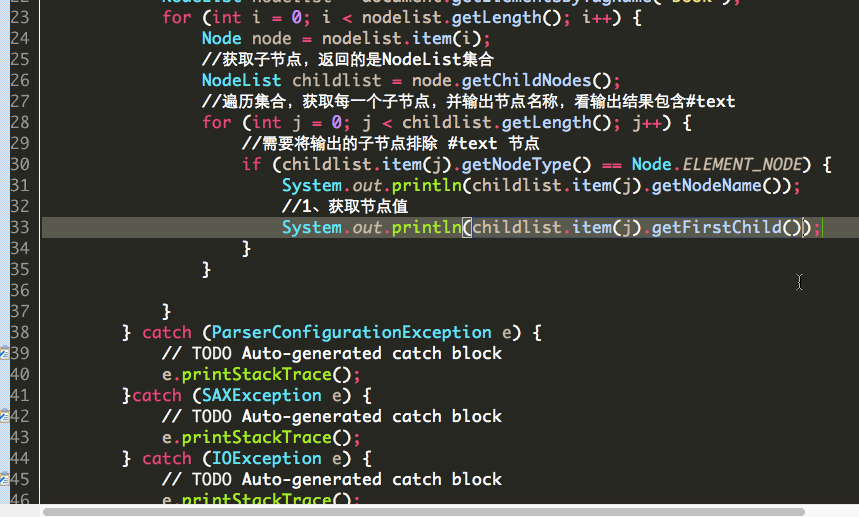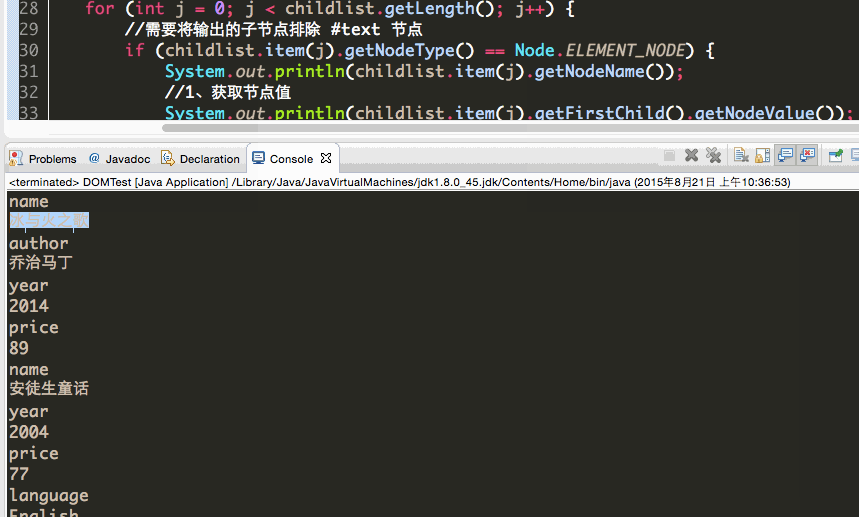
两种获取子节点的value:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号