
分布式锁没那么难,手把手教你实现 Redis 分布锁!|保姆级教程
书接上文
上篇文章「MySQL 可重复读,差点就让我背上了一个 P0 事故!」发布之后,收到很多小伙伴们的留言,从中又学习到很多,总结一下。

上篇文章可能举得例子有点不恰当,导致有些小伙伴没看懂为什么余额会变负。

这次我们举得实际一点,还是上篇文章 account 表,假设 id=1,balance=1000,不过这次我们扣款 1000,两个事务的时序图如下:

这次使用两个命令窗口真实执行一把:
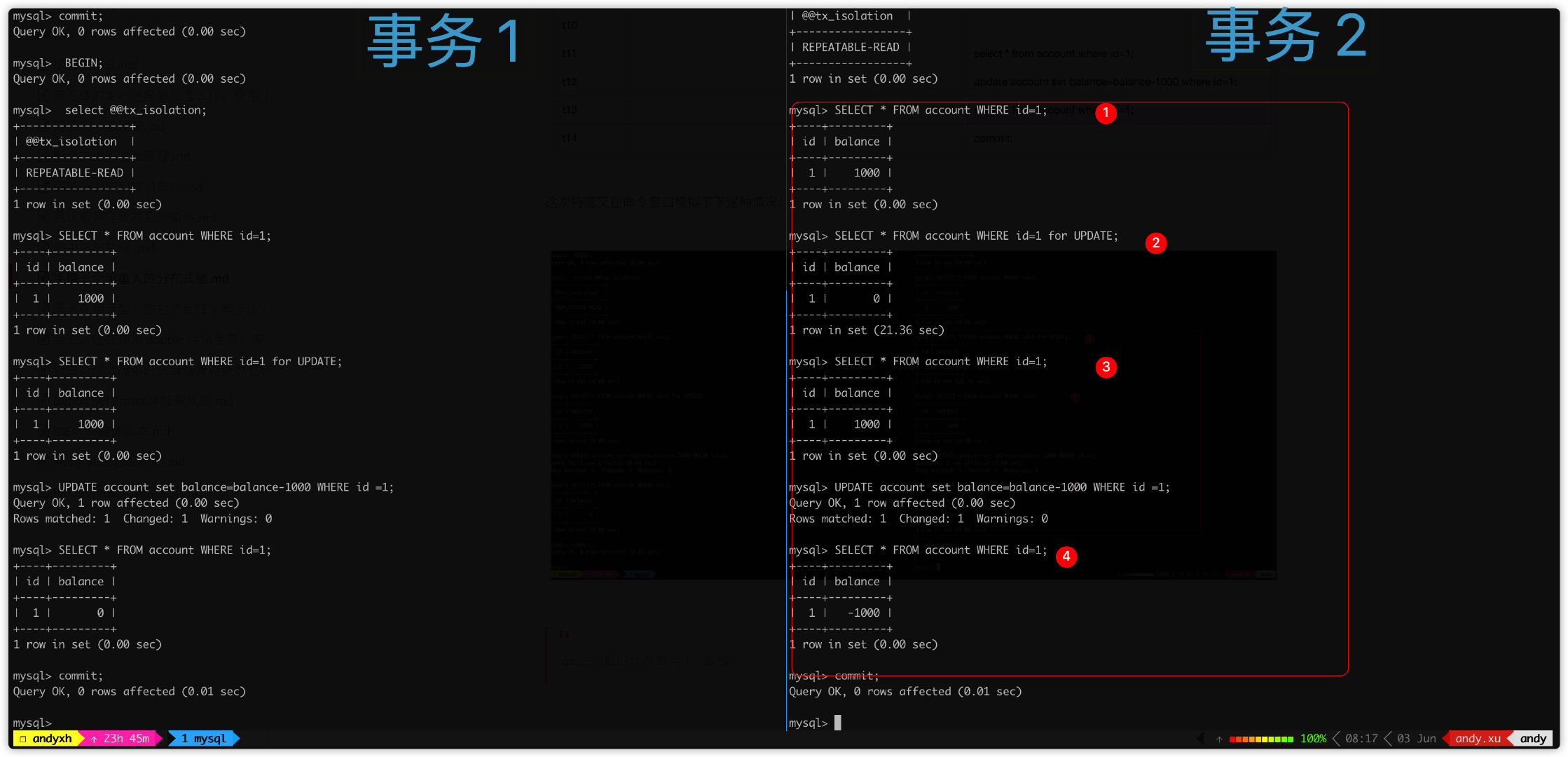
注意事务 2,③处查询到 id=1,balance=1000,但是实际上由于此时事务 1 已经提交,最新结果如②处所示 id=1,balance=900。
本来 Java 代码层会做一层余额判断:
if (balance - amount < 0) {
throw new XXException("余额不足,扣减失败");
}
但是此时由于 ③ 处使用快照读,读到是个旧值,未读到最新值,导致这层校验失效,从而代码继续往下运行,执行了数据更新。
更新语句又采用如下写法:
UPDATE account set balance=balance-1000 WHERE id =1;
这条更新语句又必须是在这条记录的最新值的基础做更新,更新语句执行结束,这条记录就变成了 id=1,balance=-1000。

之前有朋友疑惑 t12 更新之后,再次进行快照读,结果会是多少。
上图执行结果 ④ 可以看到结果为 id=1,balance=-1000,可以看到已经查询最新的结果记录。
这行数据最新版本由于是事务 2 自己更新的,自身事务更新永远对自己可见。
另外这次问题上本质上因为 Java 层与数据库层数据不一致导致,有的朋友留言提出,可以在更新余额时加一层判断:
UPDATE account set balance=balance-1000 WHERE id =1 and balance>0;
然后更新完成,Java 层判断更新有效行数是否大于 0。这种做法确实能规避这个问题。
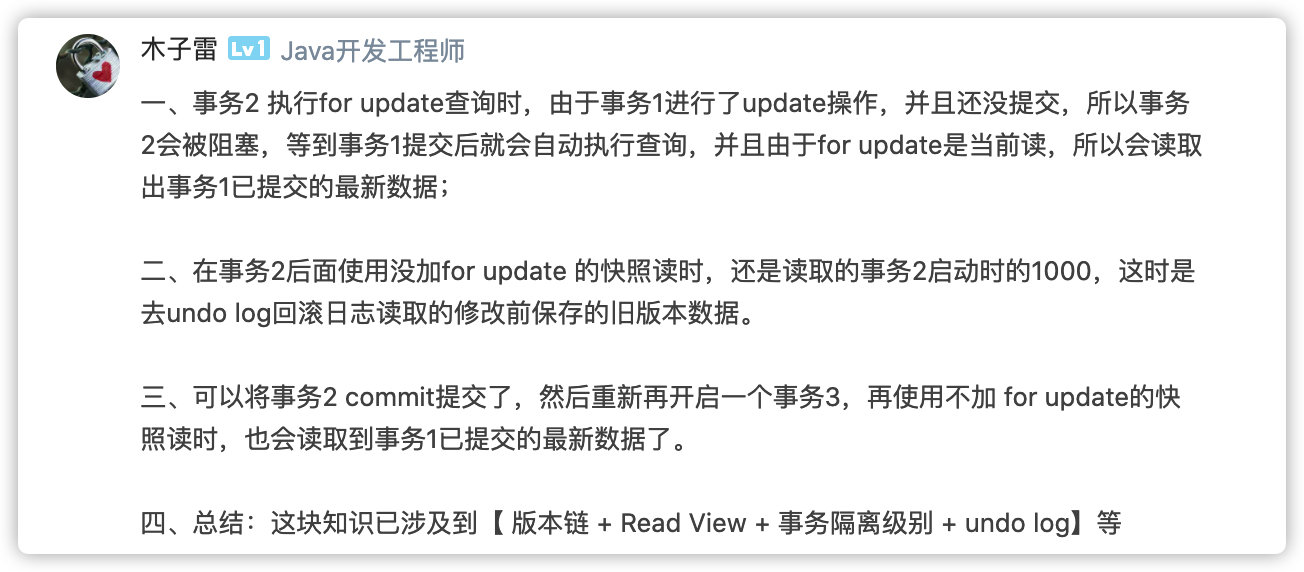
最后这位朋友留言总结的挺好,粘贴一下:
先赞后看,微信搜索「程序通事」,关注就完事了
手撸分布式锁
现在切回正文,这篇文章本来是准备写下 Mysql 查询左匹配的问题,但是还没研究出来。那就先写下最近在鼓捣一个东西,使用 Redis 实现可重入分布锁。
看到这里,有的朋友可能会提出来使用 redisson 不香吗,为什么还要自己实现?
哎,redisson 真的很香,但是现有项目中没办法使用,只好自己手撸一个可重入的分布式锁了。
虽然用不了 redisson,但是我可以研究其源码,最后实现的可重入分布锁参考了 redisson 实现方式。
分布式锁
分布式锁特性就要在于排他性,同一时间内多个调用方加锁竞争,只能有一个调用方加锁成功。
Redis 由于内部单线程的执行,内部按照请求先后顺序执行,没有并发冲突,所以只会有一个调用方才会成功获取锁。
而且 Redis 基于内存操作,加解锁速度性能高,另外我们还可以使用集群部署增强 Redis 可用性。
加锁
使用 Redis 实现一个简单的分布式锁,非常简单,可以直接使用 SETNX 命令。
SETNX 是『SET if Not eXists』,如果不存在,才会设置,使用方法如下:
不过直接使用 SETNX 有一个缺陷,我们没办法对其设置过期时间,如果加锁客户端宕机了,这就导致这把锁获取不了了。
有的同学可能会提出,执行 SETNX 之后,再执行 EXPIRE 命令,主动设置过期时间,伪码如下:
var result = setnx lock "client"
if(result==1){
// 有效期 30 s
expire lock 30
}
不过这样还是存在缺陷,加锁代码并不能原子执行,如果调用加锁语句,还没来得及设置过期时间,应用就宕机了,还是会存在锁过期不了的问题。
不过这个问题在 Redis 2.6.12 版本 就可以被完美解决。这个版本增强了 SET 命令,可以通过带上 NX,EX 命令原子执行加锁操作,解决上述问题。参数含义如下:
- EX second :设置键的过期时间,单位为秒
- NX 当键不存在时,进行设置操作,等同与 SETNX 操作
使用 SET 命令实现分布式锁只需要一行代码:
SET lock_name anystring NX EX lock_time
解锁
解锁相比加锁过程,就显得非常简单,只要调用 DEL 命令删除锁即可:
DEL lock_name
不过这种方式却存在一个缺陷,可能会发生错解锁问题。
假设应用 1 加锁成功,锁超时时间为 30s。由于应用 1 业务逻辑执行时间过长,30 s 之后,锁过期自动释放。
这时应用 2 接着加锁,加锁成功,执行业务逻辑。这个期间,应用 1 终于执行结束,使用 DEL 成功释放锁。
这样就导致了应用 1 错误释放应用 2 的锁,另外锁被释放之后,其他应用可能再次加锁成功,这就可能导致业务重复执行。

为了使锁不被错误释放,我们需要在加锁时设置随机字符串,比如 UUID。
SET lock_name uuid NX EX lock_time
释放锁时,需要提前获取当前锁存储的值,然后与加锁时的 uuid 做比较,伪代码如下:
var value= get lock_name
if value == uuid
// 释放锁成功
else
// 释放锁失败
上述代码我们不能通过 Java 代码运行,因为无法保证上述代码原子化执行。
幸好 Redis 2.6.0 增加执行 Lua 脚本的功能,lua 代码可以运行在 Redis 服务器的上下文中,并且整个操作将会被当成一个整体执行,中间不会被其他命令插入。
这就保证了脚本将会以原子性的方式执行,当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。在其他的别的客户端看来,执行脚本的效果,要么是不可见的,要么就是已完成的。
EVAL 与 EVALSHA
EVAL
Redis 可以使用 EVAL 执行 LUA 脚本,而我们可以在 LUA 脚本中执行判断求值逻辑。EVAL 执行方式如下:
EVAL script numkeys key [key ...] arg [arg ...]
numkeys 参数用于建明参数,即后面 key 数组的个数。
key [key ...] 代表需要在脚本中用到的所有 Redis key,在 Lua 脚本使用使用数组的方式访问 key,类似如下 KEYS[1] , KEYS[2]。注意 Lua 数组起始位置与 Java 不同,Lua 数组是从 1 开始。
命令最后,是一些附加参数,可以用来当做 Redis Key 值存储的 Value 值,使用方式如 KEYS 变量一样,类似如下:ARGV[1] 、 ARGV[2] 。
用一个简单例子运行一下 EVAL 命令:
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2],ARGV[3]}" 2 key1 key2 first second third
运行效果如下:

可以看到 KEYS 与 ARGVS内部数组可以不一致。
在 Lua 脚本可以使用下面两个函数执行 Redis 命令:
- redis.call()
- redis.pcall()
两个函数作用法与作用完全一致,只不过对于错误的处理方式不一致,感兴趣的小伙伴可以具体点击以下链接,查看错误处理一章。
http://doc.redisfans.com/script/eval.html
下面我们统一在 Lua 脚本中使用 redis.call(),执行以下命令:
eval "return redis.call('set',KEYS[1],ARGV[1])" 1 foo 楼下小黑哥
运行效果如下:

EVALSHA
EVAL 命令每次执行时都需要发送 Lua 脚本,但是 Redis 并不会每次都会重新编译脚本。
当 Redis 第一次收到 Lua 脚本时,首先将会对 Lua 脚本进行 sha1 获取签名值,然后内部将会对其缓存起来。后续执行时,直接通过 sha1 计算过后签名值查找已经编译过的脚本,加快执行速度。
虽然 Redis 内部已经优化执行的速度,但是每次都需要发送脚本,还是有网络传输的成本,如果脚本很大,这其中花在网络传输的时间就会相应的增加。
所以 Redis 又实现了 EVALSHA 命令,原理与 EVAL 一致。只不过 EVALSHA 只需要传入脚本经过 sha1计算过后的签名值即可,这样大大的减少了传输的字节大小,减少了网络耗时。
EVALSHA命令如下:
evalsha c686f316aaf1eb01d5a4de1b0b63cd233010e63d 1 foo 楼下小黑哥
运行效果如下:

SCRIPT FLUSH命令用来清除所有 Lua 脚本缓存。
可以看到,如果之前未执行过 EVAL命令,直接执行 EVALSHA 将会报错。
优化执行 EVAL
我们可以结合使用 EVAL 与 EVALSHA,优化程序。下面就不写伪码了,以 Jedis 为例,优化代码如下:
//连接本地的 Redis 服务
Jedis jedis = new Jedis("localhost", 6379);
jedis.auth("1234qwer");
System.out.println("服务正在运行: " + jedis.ping());
String lua_script = "return redis.call('set',KEYS[1],ARGV[1])";
String lua_sha1 = DigestUtils.sha1DigestAsHex(lua_script);
try {
Object evalsha = jedis.evalsha(lua_sha1, Lists.newArrayList("foo"), Lists.newArrayList("楼下小黑哥"));
} catch (Exception e) {
Throwable current = e;
while (current != null) {
String exMessage = current.getMessage();
// 包含 NOSCRIPT,代表该 lua 脚本从未被执行,需要先执行 eval 命令
if (exMessage != null && exMessage.contains("NOSCRIPT")) {
Object eval = jedis.eval(lua_script, Lists.newArrayList("foo"), Lists.newArrayList("楼下小黑哥"));
break;
}
}
}
String foo = jedis.get("foo");
System.out.println(foo);
上面的代码看起来还是很复杂吧,不过这是使用原生 jedis 的情况下。如果我们使用 Spring Boot 的话,那就没这么麻烦了。Spring 组件执行的 Eval 方法内部就包含上述代码的逻辑。
不过需要注意的是,如果 Spring-Boot 使用 Jedis 作为连接客户端,并且使用Redis Cluster 集群模式,需要使用 2.1.9 以上版本的spring-boot-starter-data-redis,不然执行过程中将会抛出:
org.springframework.dao.InvalidDataAccessApiUsageException: EvalSha is not supported in cluster environment.
详细情况可以参考这个修复的 IssueAdd support for scripting commands with Jedis Cluster
优化分布式锁
讲完 Redis 执行 LUA 脚本的相关命令,我们来看下如何优化上面的分布式锁,使其无法释放其他应用加的锁。
以下代码基于 spring-boot 2.2.7.RELEASE 版本,Redis 底层连接使用 Jedis。
加锁的 Redis 命令如下:
SET lock_name uuid NX EX lock_time
加锁代码如下:
/**
* 非阻塞式加锁,若锁存在,直接返回
*
* @param lockName 锁名称
* @param request 唯一标识,防止其他应用/线程解锁,可以使用 UUID 生成
* @param leaseTime 超时时间
* @param unit 时间单位
* @return
*/
public Boolean tryLock(String lockName, String request, long leaseTime, TimeUnit unit) {
// 注意该方法是在 spring-boot-starter-data-redis 2.1 版本新增加的,若是之前版本 可以执行下面的方法
return stringRedisTemplate.opsForValue().setIfAbsent(lockName, request, leaseTime, unit);
}
由于setIfAbsent方法是在 spring-boot-starter-data-redis 2.1 版本新增加,之前版本无法设置超时时间。如果使用之前的版本的,需要如下方法:
/**
* 适用于 spring-boot-starter-data-redis 2.1 之前的版本
*
* @param lockName
* @param request
* @param leaseTime
* @param unit
* @return
*/
public Boolean doOldTryLock(String lockName, String request, long leaseTime, TimeUnit unit) {
Boolean result = stringRedisTemplate.execute((RedisCallback<Boolean>) connection -> {
RedisSerializer valueSerializer = stringRedisTemplate.getValueSerializer();
RedisSerializer keySerializer = stringRedisTemplate.getKeySerializer();
Boolean innerResult = connection.set(keySerializer.serialize(lockName),
valueSerializer.serialize(request),
Expiration.from(leaseTime, unit),
RedisStringCommands.SetOption.SET_IF_ABSENT
);
return innerResult;
});
return result;
}
解锁需要使用 Lua 脚本:
-- 解锁代码
-- 首先判断传入的唯一标识是否与现有标识一致
-- 如果一致,释放这个锁,否则直接返回
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
这段脚本将会判断传入的唯一标识是否与 Redis 存储的标示一致,如果一直,释放该锁,否则立刻返回。
释放锁的方法如下:
/**
* 解锁
* 如果传入应用标识与之前加锁一致,解锁成功
* 否则直接返回
* @param lockName 锁
* @param request 唯一标识
* @return
*/
public Boolean unlock(String lockName, String request) {
DefaultRedisScript<Boolean> unlockScript = new DefaultRedisScript<>();
unlockScript.setLocation(new ClassPathResource("simple_unlock.lua"));
unlockScript.setResultType(Boolean.class);
return stringRedisTemplate.execute(unlockScript, Lists.newArrayList(lockName), request);
}
由于公号外链无法直接跳转,关注『程序通事』,回复分布式锁获取源代码。
Redis 分布式锁的缺陷
无法重入
由于上述加锁命令使用了 SETNX ,一旦键存在就无法再设置成功,这就导致后续同一线程内继续加锁,将会加锁失败。
如果想将 Redis 分布式锁改造成可重入的分布式锁,有两种方案:
- 本地应用使用 ThreadLocal 进行重入次数计数,加锁时加 1,解锁时减 1,当计数变为 0 释放锁
- 第二种,使用 Redis Hash 表存储可重入次数,使用 Lua 脚本加锁/解锁
第一种方案可以参考这篇文章分布式锁的实现之 redis 篇。第二个解决方案,下一篇文章就会具体来聊聊,敬请期待。

锁超时释放
假设线程 A 加锁成功,锁超时时间为 30s。由于线程 A 内部业务逻辑执行时间过长,30s 之后锁过期自动释放。
此时线程 B 成功获取到锁,进入执行内部业务逻辑。此时线程 A 还在执行执行业务,而线程 B 又进入执行这段业务逻辑,这就导致业务逻辑重复被执行。
这个问题我觉得,一般由于锁的超时时间设置不当引起,可以评估下业务逻辑执行时间,在这基础上再延长一下超时时间。
如果超时时间设置合理,但是业务逻辑还有偶发的超时,个人觉得需要排查下业务执行过长的问题。
如果说一定要做到业务执行期间,锁只能被一个线程占有的,那就需要增加一个守护线程,定时为即将的过期的但未释放的锁增加有效时间。
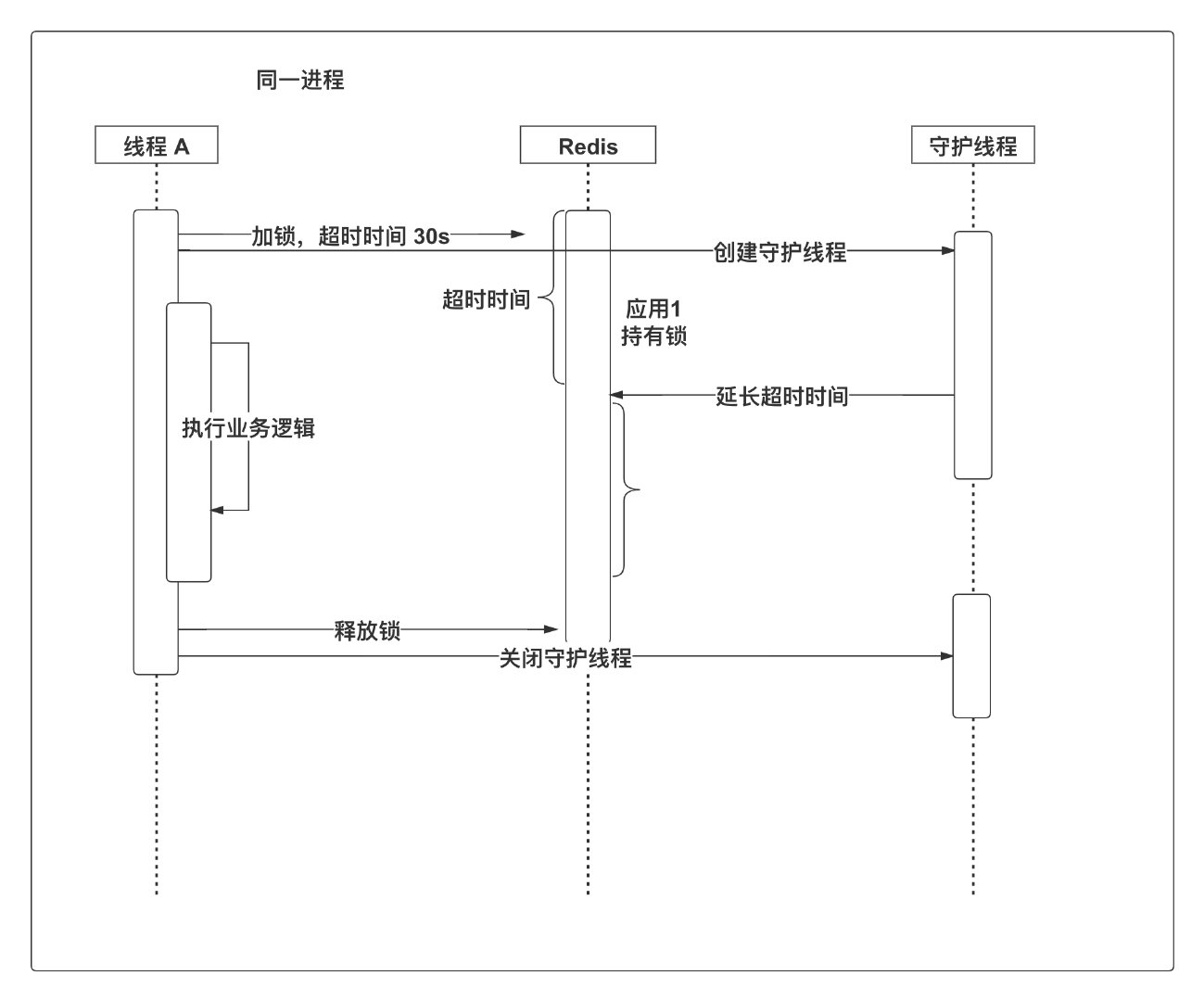
加锁成功后,同时创建一个守护线程。守护线程将会定时查看锁是否即将到期,如果锁即将过期,那就执行 EXPIRE 等命令重新设置过期时间。
说实话,如果要这么做,真的挺复杂的,感兴趣的话可以参考下 redisson watchdog 实现方式。
Redis 分布式锁集群问题
为了保证生产高可用,一般我们会采用主从部署方式。采用这种方式,我们可以将读写分离,主节点提供写服务,从节点提供读服务。
Redis 主从之间数据同步采用异步复制方式,主节点写入成功后,立刻返回给客户端,然后异步复制给从节点。
如果数据写入主节点成功,但是还未复制给从节点。此时主节点挂了,从节点立刻被提升为主节点。
这种情况下,还未同步的数据就丢失了,其他线程又可以被加锁了。
针对这种情况, Redis 官方提出一种 RedLock 的算法,需要有 N 个Redis 主从节点,解决该问题,详情参考:
https://redis.io/topics/distlock。
这个算法自己实现还是很复杂的,幸好 redisson 已经实现的 RedLock,详情参考:redisson redlock
总结
本来这篇文章是想写 Redis 可重入分布式锁的,可是没想到写分布式锁的实现方案就已经写了这么多,再写下去,文章可能就很长,所以拆分成两篇来写。
嘿嘿,这不下星期不用想些什么了,真是个小机灵鬼~

好了,帮大家再次总结一下本文内容。
简单的 Redis 分布式锁的实现方式还是很简单的,我们可以直接用 SETNX/DEL 命令实现加解锁。
不过这种实现方式不够健壮,可能存在应用宕机,锁就无法被释放的问题。
所以我们接着引入以下命令以及 Lua 脚本增强 Redis 分布式锁。
SET lock_name anystring NX EX lock_time
最后 Redis 分布锁还是存在一些缺陷,在这里提出一些解决方案,感兴趣同学可以自己实现一下。
下篇文章再来将将 Redis 可重入分布式锁~
参考资料
欢迎关注我的公众号:程序通事,获得日常干货推送。如果您对我的专题内容感兴趣,也可以关注我的博客:studyidea.cn



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?