

3.Java-字符和字符编码
字符的编码
字符编码有两大类:非Unicode编码 (ASCII、ISO 8859-1、Windows-1252、GB2312、GBK、GB18030和Big5),和Unicode编码。
其中非Unicode编码是每个国家的各种计算机厂商都对自己常用的字符进行编码,Unicode是给世界上所有字符分配了唯一数字编号。它并没有规定这个编号怎么对应到二进制表示,对应到二进制表示,主要有UTF-32、UTF-16和UTF-8几种方案。接下来具体看看。
非Unicode编码
1.ASCII
全称是American Standard Code for InformationInterchange,即美国信息互换标准代码,该编码只考虑了美国需求,大约只有128个字符,使用7位(0 ~ 127)表示刚好,计算机最小单位是byte-8位,所以首位设置为0。其中128字符中32~126为可打印字符,如图
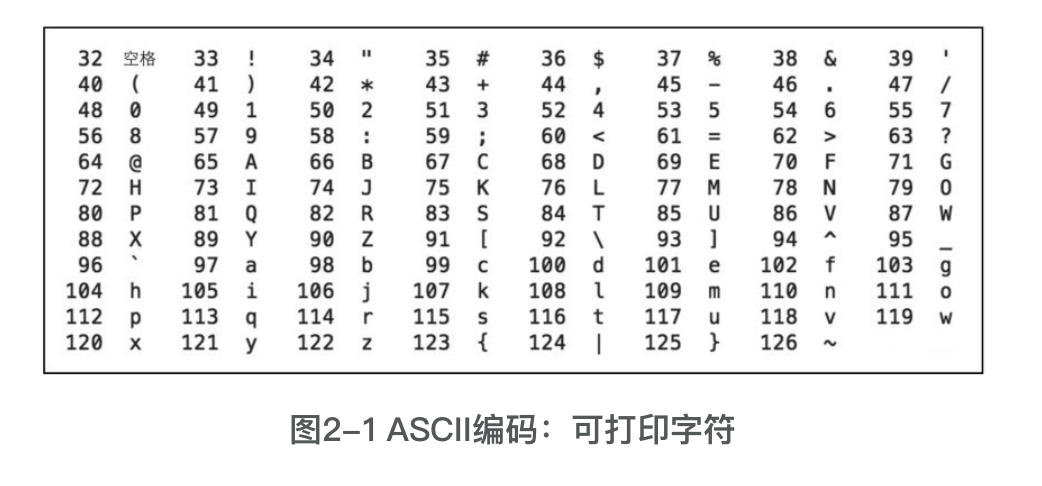
其余0~31和127为不可打印的字符,来进行一些控制操作,常用如图

2.ISO 8859-1、Windows-1252
给西欧国家使用,使用一个字节的无符号整型(0~255)来表示一个字符。目前使用更为广泛的是Windows-1252编码,基本上可以认为,ISO 8859-1已被Windows-1252取代。
ISO 8859-1标准比较早,而欧元比较晚,缺少欧元(€)这个符号,Windows-1252编码中加入了欧元符号以及一些其他常用的字符,在很多应用程序中,即使文件声明它采用的是ISO 8859-1编码,解析的时候依然被当作Windows-1252编码。
3.GB2312、GBK、GB18030
中文的编码从GB2312,发展到GBK,再到GB18030,均能够向下兼容,而能表示的范围从7000个汉字扩展到76 000多个字符,包括了很多少数民族字符,以及中日韩统一字符。
美国和西欧的字符使用一个字节足够,对于中文而言是不够使的,GB2312固定使用两个字节表示汉字,最高位都是1,如果是0,就认为是ASCII字符。GBK同样使用固定的两个字节表示,GB18030使用变长编码,有的字符是两个字节,有的是四个字节,根据第二个字节的范围来判断是两个字节还是四个字节
4.Big5
针对繁体中文
Unicode编码
Unicode主要做了这么一件事,就是给所有字符分配了唯一数字编号。它并没有规定这个编号怎么对应到二进制表示,对应到二进制的方案,主要有UTF-32、UTF-16和UTF-8。
1.UTF-32
每个字符使用4个字节表示,空间浪费,实际很少使用
2.UTF-16
字节变长表示,字符集合使用2个字节,增补字符集使用四个字节,UTF-16常用于系统内部编码,对于美国和西欧国家而言,还是很浪费的。
UTF-16使用两个或4个字节表示一个字符,Unicode编号范围在65536以内的占两个字节,超出范围的占4个字节,BE就是先输出高位字节,再输出低位字节,这与整数的内存表示是一致的
3.UTF-8
字节变长表示,1~4字节个数不等,UTF-8是兼容ASCII的,对大部分中文而言,一个中文字符需要用三个字节表示。
总结Unicode编码
“Unicode给世界上所有字符都规定了一个统一的编号,编号范围达到110多万,但大部分字符都在65 536以内。Unicode本身没有规定怎么把这个编号对应到二进制形式。
UTF-32/UTF-16/UTF-8都在做一件事,就是把Unicode编号对应到二进制形式,其对应方法不同而已。UTF-32使用4个字节,UTF-16大部分是两个字节,少部分是4个字节,它们都不兼容ASCII编码,都有字节顺序的问题。UTF-8使用1~4个字节表示,兼容ASCII编码,英文字符使用1个字节,中文字符大多用3个字节”
乱码的产生
1.编码的转换
Unicode出现后,字符有多种编码方式,不同编码通过Unicode进行转化。具体的过程为,一个字符从A编码转到B编码,先找到字符的A编码格式,通过A的映射表找到其Unicode编号,然后通过Unicode编号再查B的映射表,找到字符的B编码格式,比如“马”从GB18030转到UTF-8,先查GB18030->Unicode编号表,得到其编号是9A 6C,然后查Uncode编号->UTF-8表,得到其UTF-8编码:E9 A9AC。

2.乱码的原因
(1) 解析错误
A编码的字符,被当做B编码的字符来解析。 通过切换编码方式就可以得到纠正。
(2) 解析错误+编码转换
计算机程序为了便于统一处理,经常会将所有编码转换为一种方式,比如UTF-8。在转换时需要通过原始编码来映射Unicode,如果原始编码是A,被当做B进行映射后就会出现乱码。
(3) 从乱码中恢复
基本方法
1)public byte[] getBytes(String charsetName),这个方法可以获取一个字符串的给定编码格式的二进制形式。
2)public String(byte bytes[], String charsetName),这个构造方法以给定的二进制数组bytes按照编码格式charsetName解读为一个字符串。
// 假设原来的编码是GB18030,被错误解析成windows-1252
String str = "ÀÏÂí";
String newStr = new String(str.getBytes("windows-1252"), "GB18030");
System.out.println(newStr);
使用循环实现的方法
// 通过A编码转换,B编码查看,以下共12中组合方式
public static void recover(String str)
throws UnsupportedEncodingException{
String[] charsets = new String[]{
"windows-1252", "GB18030", "Big5", "UTF-8"};
for(int i=0; i<charsets.length; i++){
for(int j=0; j<charsets.length; j++){
if(i! =j){
String s = new String(str.getBytes(charsets[i]), charsets[j]);
System.out.println("---- 原来编码(A)假设是: "
+charsets[j]+", 被错误解读为了(B): "+charsets[i]);
System.out.println(s);
System.out.println();
}
}
}
}
字符的本质
char在java中使用Unicode处理,具体使用UTF-16BE进行编码,是一个固定占用两个字节的无符号正整数,这个正整数对应于Unicode编号,用于表示那个Unicode编号对应的字符。
// 多种赋值
1. char c = 'A' // ASCII码表示的字符
2. char c = '马' // 中文字符,赋值时需要注意中文编码,将其对应的Unicode赋值
3. char c = 39532 // 直接赋值字符的Unicode编码的10进制
4. char c = 0x9a6c // 直接赋值字符Unicode编码的16进制
5. char c = '\u9a6c' // 直接赋值字符Unicode编码的字符形式
因为char本质是unicode编码的正整数,所以能够进行算数运算和比较运算。加减运算的使用场景是针对ASCII码字符,大写A~Z的编号是65~90,小写a~z的编号是97~122,正好相差32,所以大写转小写只需加32,而小写转大写只需减32。
书籍:18年出版/机械工业出版社/马俊昌/《Java编程的逻辑》第一部分第二章


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix