

mysql
1.分库分表基础认知
传统关系型数据库(一般,指 InnoDB MySQL )参考指标:
- 1TB:如果数据库会膨胀到 TB 级别,需要考虑 MySQL 分库分库。
- 1000 万行或 10GB:单表的记录数超过 1000 万行,或单表磁盘空间占用超过 10GB,需要考虑分表
- 每秒 1000 次写入:单节点写入速率超过每秒 1000 次。可以考虑根据业务场景引入 Redis 或消息队列作为写缓冲,实现数据库写操作异步化
来源:刘春辉 《Shopee 是如何进行数据库选型的?》
数据库的单机QPS不过几千,显然满足不了互联网业务场景下对高并发的要求。因此,分库分表 + 读写分离成为常态。
- 分库,即把一个库分成多个库,部署在多个实例之上。
- 读写分析:主库承载写请求,从库承载读请求。由于多数业务场景都是读远多于写,一个主库挂多个从库,可以有效降低对单库的压力。
如果写请求继续增加(或,数据量增加)达到瓶颈,就继续分库分表;反之,如果读的请求上升就挂更多的从库。
2. 设计和查询规范
命名
避免使用 MySQL 关键词 作为 db / table / field / index 名称
- DB
- 使用项目名作为前缀,“_db” 作为后缀;分库添加后缀8位宽度的数字,数字从0开始
- 风格:由下划线分割的小写英文字母组成
- DB 名称总长度小于 42 个字符
- Table
- “_db” 作为后缀;分表添加后缀8位宽度的数字,数字从0开始
- 风格:由下划线分割的小写英文字母组成
- 表名称总长度小于 48 个字符
- Field
- 主键统一定义为:
idBIGINT UNSIGNED NOT NULL - 指向其他表主键的字段以 “_id” 后缀结尾
- 风格:由下划线分割的小写英文字母组成
- 11位数字要用bigint, 默认要带createTime, updateTime, 知道表的创建的时间,和更新时间。保存很短的数字时不要用tinyint(1), 这个被当成布尔值.用tinyInt(4)
- 主键统一定义为:
- Index
- 使用 “idx_” 作为前缀;索引字段名字、顺序组合为名称
- 风格:由下划线分割的小写英文字母组成
- Comment
- 纯英文单词注释所有字段
DB
- 存储引擎
innodb, myism, memeroy.
- 使用 Innodb 存储引擎
Innodb 支持事务,支持行级锁,高并发下性能更好
- 使用 utf8mb4_unicode_ci 编码
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效
Table
-
使用 utf8mb4_unicode_ci 编码
-
每张表必须显式定义主键
- 数据的存储顺序和主键的顺序是相同的
- 不要使用更新频繁的列作为主键,不要使用 UUID、MD5、HASH、字符串等无法保证数据的顺序增长的字段作为主键
-
尽量控制单表数据量的大小,建议控制在 1000万 以内
- 该量级数据量查询性能较好
- 可以用历史数据归档,分库分表等手段来控制单表数据量
-
宽表尽量拆分为索引表和内容表以提高查询性能
- MySQL 限制每个表最多存储 4096 列,并且每一行数据的大小不能超过 65535 字节 减少磁盘 IO,保证热数据的内存缓存命中率
- 表越宽,装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的 IO,更有效的利用缓存,避免读入无用的冷数据
-
谨慎使用 JOIN
- 应用层缓存效率更高,可以在多种查询场景复用缓存
- 在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展
- 查询效率提升。使用 ID 查询,可以让 MySQL 按照主键索引顺序查询,相比关联要更稳定高效
-
谨慎使用 MySQL 分区表
分区表在物理上表现为多个文件,在逻辑上表现为一个表 谨慎选择分区键,跨分区查询效率可能更低 建议采用物理分表的方式管理大数据
-
不要使用外键
- MySQL 外键实现比较简单粗糙,性能不好
- MySQL 作为后端存储,不在 MySQL 上放置任何计算逻辑
- 如果依赖于在 MySQL 服务器上运行的计算逻辑,进行数据库/表分片将非常困难
Field
-
优先选择符合存储需要的最小的数据类型
列的字段越大,索引时所需要的空间越大,磁盘单页存储的索引节点数越少,遍历时 IO 次数就越多, 索引性能也就越差
方法:
1)将字符串转换成数字类型存储,如:将IP地址转换成整形数据(inet_aton / inet_ntoa)
2)对于非负型的数据(如自增ID、整型IP)来说,要优先使用无符号整型来存储 -
存储相同数据的列名和列类型必须一致
如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低
-
尽可能把所有列定义为 NOT NULL
- NULL 占用额外的空间来保存
- NULL 需要特殊处理,可能会导致应用程序异常
- NULL MySQL 索引统计和值比较更复杂
-
避免使用 ENUM 类型
- 修改 ENUM 值需要使用 ALTER 语句
- ENUM 类型的 ORDER BY 操作效率低,需要额外操作
- 禁止使用数值作为 ENUM 的枚举值
-
禁止在数据库中存储长文本、图片,文件等大数据
MySQL 内存临时表不支持 TEXT、BLOB 大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行
而且对于这种数据,MySQL 还是要进行二次查询,会使 SQL 性能变得很差,但是不是说一定不能使用这样的数据类型
-
禁止建立预留字段
- 预留字段的命名很难做到见名识义
- 预留字段无法确认存储的数据类型,所以无法选择合适的类型
- 对预留字段类型的修改,会对表进行锁定
Index
- 限制每张表上的索引数量,建议单张表索引不超过5个
MySQL 优化器优化查询时,会根据统计信息,对候选索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能
Stored Programs
- 禁止使用 mysql 视图,存储过程,触发器,自定义函数
Queries
- 禁止直连生产环境,手工删除和修改生产数据
- 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
可减少表结构变更对应用程序的影响
- 禁止使用不含字段列表的INSERT语句
正确:INSERT INTO tbl(c1,c2,c3) VALUES (a,b,c);
错误:INSERT INTO VALUES (a,b,c); - WHERE从句中禁止对列进行函数转换和计算
对列进行函数转换或计算时会导致无法使用索引。
正确:WHERE create_time >= 20190101 AND create_time < 20190102
错误:WHERE DATE(create_time)=20190101 - 不会有重复值时使用 UNION ALL 而不是 UNION
UNION 将结果集的所有数据放到临时表后再去重
UNION ALL 不会再对结果集进行去重
3.原理
背景
虽然 Nosql 风生水起,关系型数据库在当前的开发中仍然扮演着不可或缺的角色。因此在面试中也会被时常问到,很多问题即使是工作多年的同学仍然会磨棱两可,例如:
- 为什么使用B+树,而不是B树作为底层数据结构?
- 最左前缀匹配原则 为什么跟索引中字段顺序相关,而与查询中字段顺序无关?
- Like 查询能够使用索引吗?
- 主键为什么最好选择递增的字段?
很多人把原因归结于没有认真准备。靠记忆死记硬背终归落了下乘,归根结底还是没有把握住本质。MySQL的本质是什么?当然是其存储引擎。要想对数据库有本质的认识,了解存储引擎底层的数据结构 B+树 是一堂必修课。
B+ 树
定义
如果此B+树的阶数是 m+1,则:
- 每个节点最多有 m 个 Key 及 m+1 个子节点
- 除根节点外,所有节点必须半满(Half-full)
- 如果 m 是 偶数,且 m = 2d
- 叶节点半满:至少有 d 个Key
- 非叶节点半满:至少有 d 个Key
- 如果 m 是奇数,且 m = 2d+1
- 叶节点半满:至少有 d+1 个 Key
- 非叶节点半满:至少有 d 个Key
算法
查找
从根节点开始,检查非叶子节点的索引项,可以使用二分(或线性)搜索进行查找,以找到对应的子节点。沿着树向下遍历,直到到达叶节点
根据以上方法查找 15*,可知它不在该树上
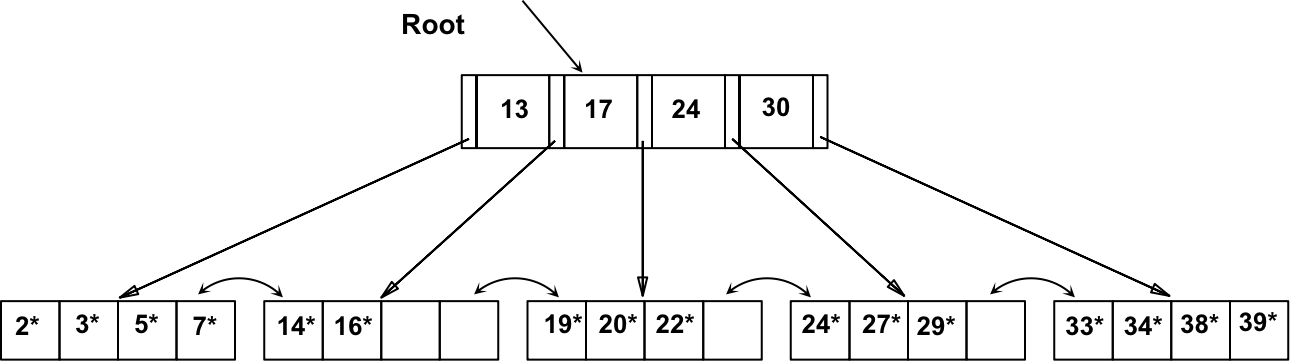
插入
-
首先,查找要插入的
叶节点 L -
接着把数据项插入这个节点中
- 如果没有节点处于违规状态,则处理结束
- 否则,均匀的拆分 L 为两个节点( L和 新节点 L2),使得每个都有最小数目的元素
- 将索引项中间的 key 复制到父节点(Copy up)
- 将指向 L2 的索引项插入到 L 的父节点
-
沿树递归向上,继续这个处理直到到达根节点
-
若要拆分索引节点,需均匀地拆分索引条目,将中间的 key 移动到父节点(Push up)
与叶节点拆分对比操作不同
-
-
如果根节点被分裂,则创建一个新根节点。
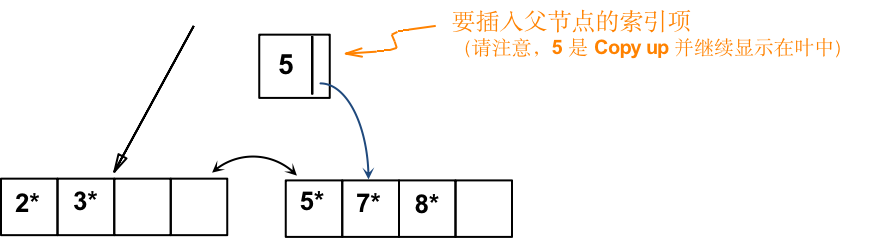
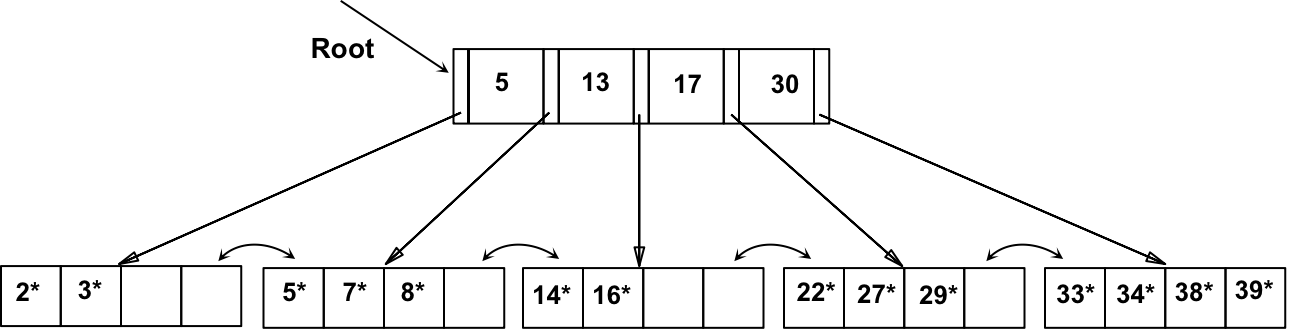
假设,将 8* 插入到上述 B+ 树,观察在叶节点和非叶节点拆分中如何保证半满的。并注意 Copy up 和 Push up 之间的区别,确保理解其中的原因。
a) 首先找到的 叶节点 L,并拆分
- 将 索引项的 key 5 Copy up
- 将 指向 L2 的 索引项指针添加到 L 的 父节点
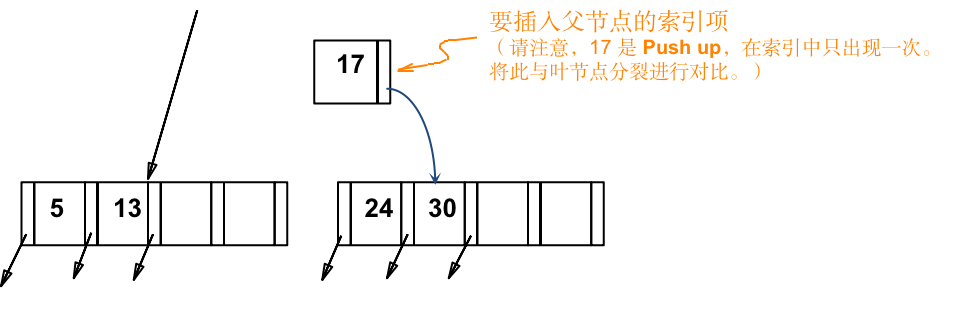
b) key 5 Copy up 到父节点子后,导致非叶节点拆分:
- 17 Push up 到 父节点
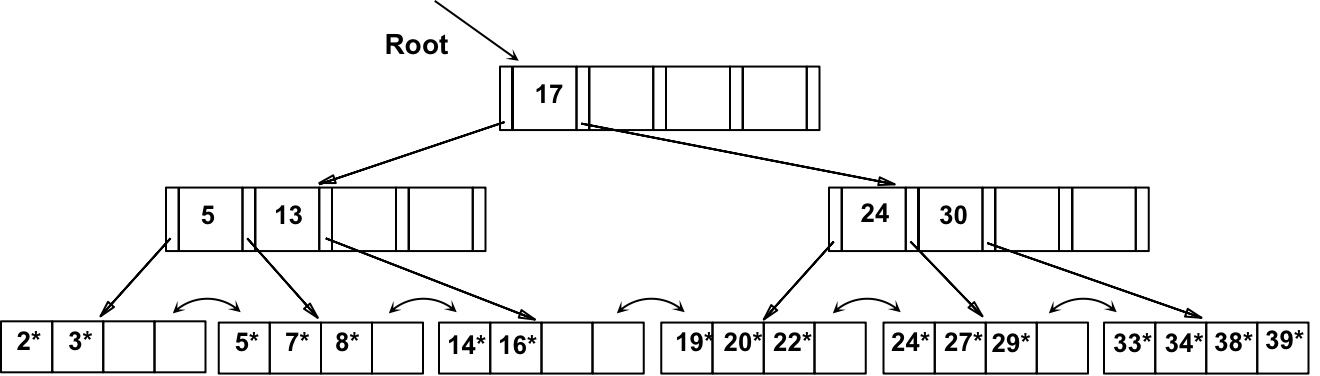
c)最终根节点被拆分,并导致树高度增加,得到以下B+树
删除
- 从根节点开始,查找该项归属的 叶节点 L
- 删除该项
- 如果叶节点L 多于半满,则处理结束
- 如果叶节点L 不足半满的索引项
- 尝试从兄弟节点(与L具有相同父级的相邻节点)借索引项,重新分配。
- 如果重新分配失败,则合并 L 和 兄弟节点
- 如果发生合并,则必须从L的父索引项中删除索引项(指向L或兄弟节点的)
- 递归此处理直到节点是合法状态,或者到达根节点。
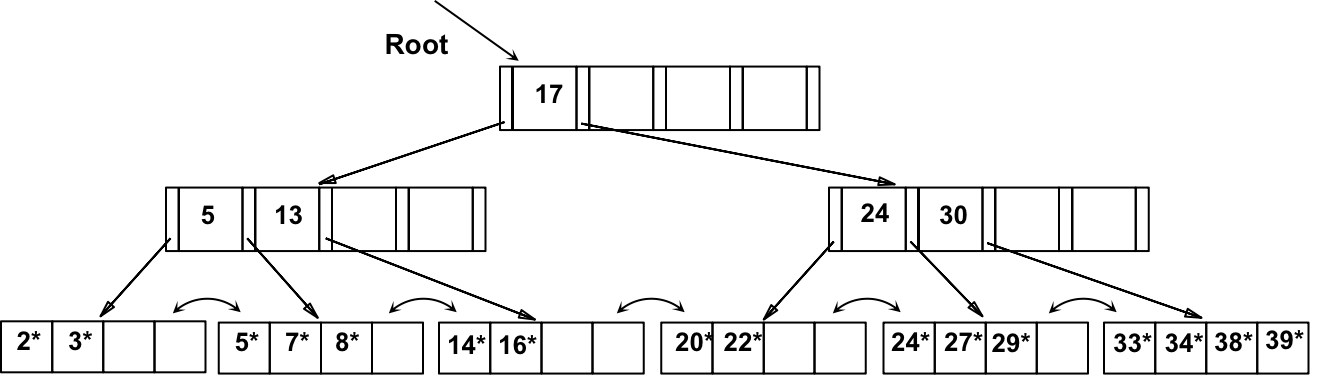
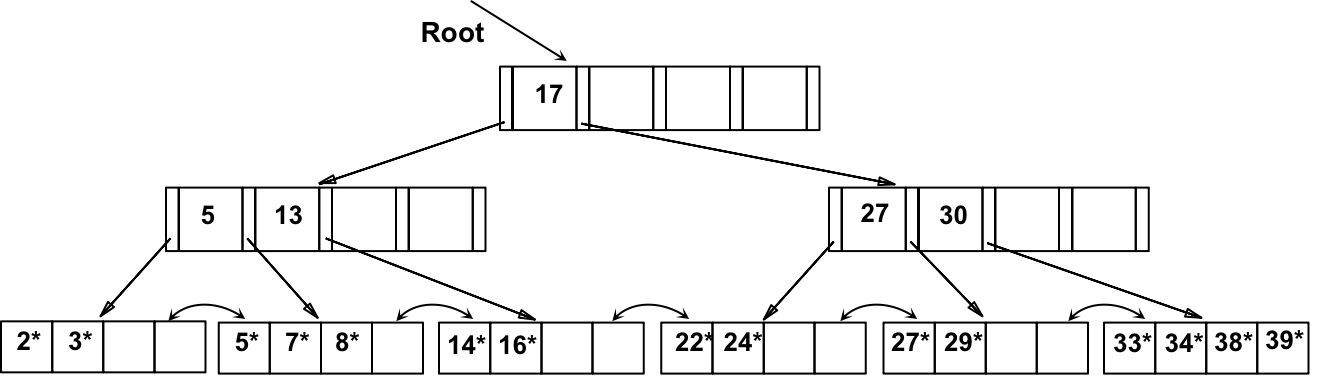
假设,对上述B+树,依次删除 19*、20*、24*
a) 删除 19*,较为简单,得到
b) 删除 20*,是通过重新分配完成的。注意中间的 key 是如何 Copy up 的
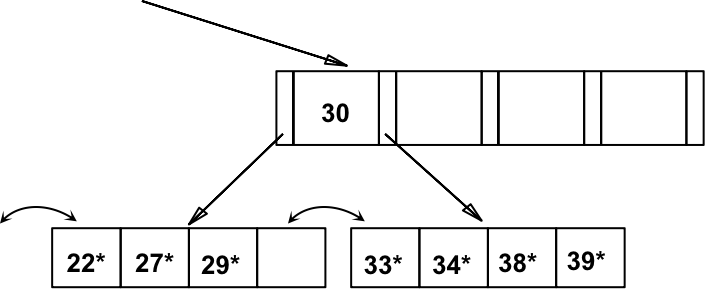
c) 删除 24*,导致与右侧索引项的合并。
然后,沿树向上,父节点同样需要与左侧兄弟节点合并,导致根节点的 “pull down”
复合索引
复合索引的B+树上的键值,就像单key的索引一样。和按字母顺序排列一个句子一样,复合索引中各个字段的顺序很重要。例如,下图为复合索引 (branch_name, balance) 的 B+树
例如,(Bournemouth, 1000) 小于等于 (Bournemouth, 1000) ,因此它出现在第一个叶节点中; (Bournemouth, 7500) 大于 (Bournemouth, 1000) ,因此它出现在第二个叶节上
例如,尽管 (Armagh, 1500) 第二个字段的值大于(Bournemouth, 1000)对应字段的值。字段的顺序意味着 (Bournemouth, 1000) 小于 (Bournemouth, 1000)
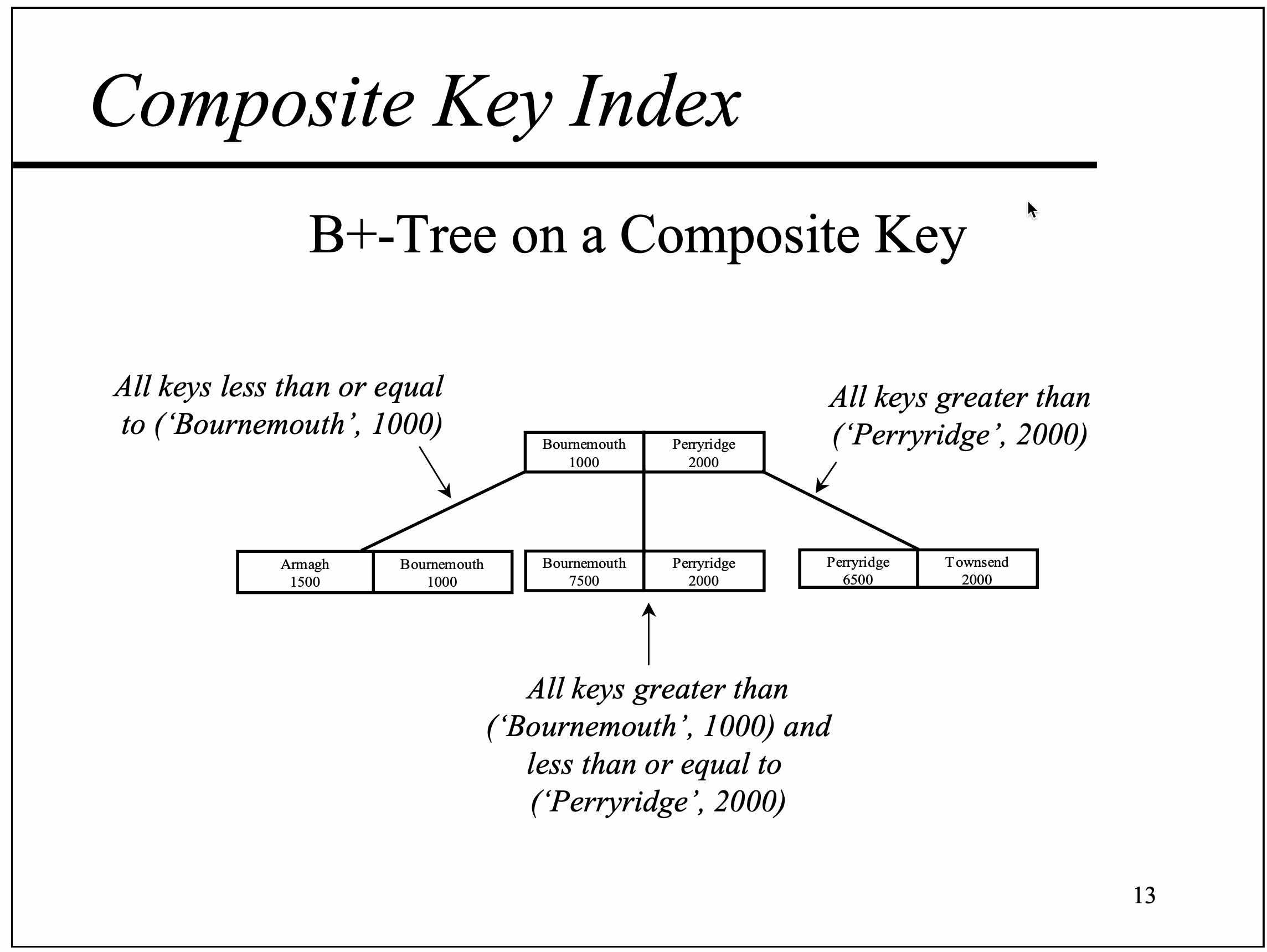
因此,上面的B+树可以用来搜索 (branch_name) 或 (branch_name, balance) ,而不能搜索 (balance)。例如,balance=2000 出现在B+树的两个路径中。
聚簇索引
由B+树的结构可知,数据记录本身被存于叶子节点上。就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,B+树会根据其主键将其插入适当的节点和位置
-
如果使用递增的字段作为主键,新增记录就会添加到当前索引节点的后面。不需要因为插入移动已有数据,因此写入效率很高
-
如果使用随机的字段作为主键,新增记录需要插入到索引的中间位置 。为了将新记录插到合适位置而移动已经存在的数据。同时频繁的移动、分页操作造成了大量的碎片,降低磁盘读写速度
总结
-
为什么使用B+树,而不是B树作为底层数据结构?
- 树高较低,磁盘IO次数少
- 有利于范围、排序、分组等查询
-
最左前缀匹配原则 为什么跟索引中字段顺序相关,而与查询中字段顺序无关?
- 因为索引中字段的顺序决定了建立一颗怎样的索引树
- 能否使用索引的本质在于,查询语句能否沿树游走
-
like 查询能够使用索引吗?
- 见
问题2 %开头的like语句无法沿树游走,因此无法使用索引
- 见
-
主键为什么最好选择递增的字段?
详见:
聚簇索引
很多的知识都是串起来的,摸清了B+树,那么对于MySQL的 Explain工具 也就自然能够做到胸有成竹,基本的索引优化自然也就手到擒来。
我的理解:首先要理解B树,就是多叉平衡树, 多叉:有二叉树, 平衡:
这里补充几个链接:看完应当很熟悉了:二叉平衡树 模拟数据结构动画
二叉平衡树的特点:
总结平衡二叉树特点:
(1)非叶子节点最多拥有两个子节点;
(2)非叶子节值大于左边子节点、小于右边子节点;
(3)树的左右两边的层级数相差不会大于1;
(4)没有值相等重复的节点;
那么自然就容易理解多叉平衡树,就是把2改为3,4,5,等。
B树,多叉平衡树,每个节点都会保存数据和指针。
B+树,只有叶子节点才保存数据。 一页的大小是16K(为什么) 一个bigint是8字节,指针是6字节,一共是14字节,
16*1024/14 就是一层的存储数据个数,假设一行数据的大小是1K,那么3层innodb的存储最大的是:
16*1024/14 * 16*1024/14 * 16*1024/1*1024 = 2千万条数据。
联合索引:
联合索引,最左原则,覆盖索引,innodb主键为什么建议用bigint 20。自增。
- 联合索引就是多个索引连成一个索引,比较的时候也是一个一个比较,
- 最左原则:索引定好了顺序,a_b_c 那么用的时候一定要 先a,再b,再c,
- 覆盖索引:就是查询的时候,select 要查询的字段,这样可以避免先找到主键id,再通过主键id去查找记录,避免回表。
索引失效:
- 复合索引不符合最左匹配原则。a_b_c复合缩影,查询 b, c, b_c, 等都会索引失效。
- 范围查询之后索引失效, a>10 and b=1 and c=2. 中,b,c会索引失效。
- 对索引做任何操作, a+1>1. func(a) > 1等。
- 条件符号, !=, or, like '%', isNull等。
- 隐式类型转换, 字符串索引用数字来查询等。
唯一索引和NULL的问题
https://dev.mysql.com/doc/refman/8.0/en/create-table.html

mysql8.0文档中说明了,innodb是可以插入多个Null值作为唯一索引的列里,Null,代表未定义,Null和Null不相同,索引能行,当然,单列索引不会存储Null值,复合索引不存储全为Null的值。
4. 查询优化
优化---执行计划 explain.
优化查询。至少要用到索引,
5.mysql里的各种锁。
posted on 2021-12-03 11:31 gongzhuiau 阅读(56) 评论(0) 编辑 收藏 举报
