
Torch - scatter、scatter_add和gather
最基础的发散操作Scatter
函数原型:scatter_(dim,index,src)→ Tensor
参数:
- dim (int) – the axis along which to index
- index (LongTensor) – the indices of elements to scatter, can be either empty or the same size of src. When empty, the operation returns identity
- src (Tensor) – the source element(s) to scatter, incase value is not specified
- value (float) – the source element(s) to scatter, incase src is not specified
scatter_(注:scatter_是scatter的就地操作)将所有被index指出的src中的值写入到张量self(即调用scatter_的张量)中。具体来说,对于src中的每个值,其在张量self中的输出索引由其dimension != dim处的索引值和其对应在张量index中dimension= dim处的值所组成(这句话比较绕,看公式和下面的例子可以帮助理解)。
Writes all values from the tensor src into self at the indices specified in the index tensor. For each value in src, its output index is specified by its index in src for dimension != dim and by the corresponding value in index for dimension = dim.
对于一个三维的张量来说,张量self的更新公式如下所示:
| self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0 | |
| self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1 | |
| self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2 |
其中需要注意的是,scatter对张量self,张量index和张量src之间的维度关系有三个约束:
(1)张量self,张量index和张量src的维度数量必须相同(即三者的.dim()必须相等,注意不是维度大小);
(2)对于每一个维度d,有index.size(d)<=src.size(d);
(3)对于每一个维度d,如果d!=dim,有index.size(d)<=self.size(d);
同时,张量index中的数值大小也有2个约束:
(4)张量index中的每一个值大小必须在[0, self.size(dim)-1]之间;
(5)张量index沿dim维的那一行中所有值都必须是唯一的(弱约束,违反不会报错,但是会造成没有意义的操作)。
其实只要记住scatter的目的是将张量src中的值根据index放入到self中,这几个约束就很好理解,为了进一步方便理解,请看下面的例子:
例子1:
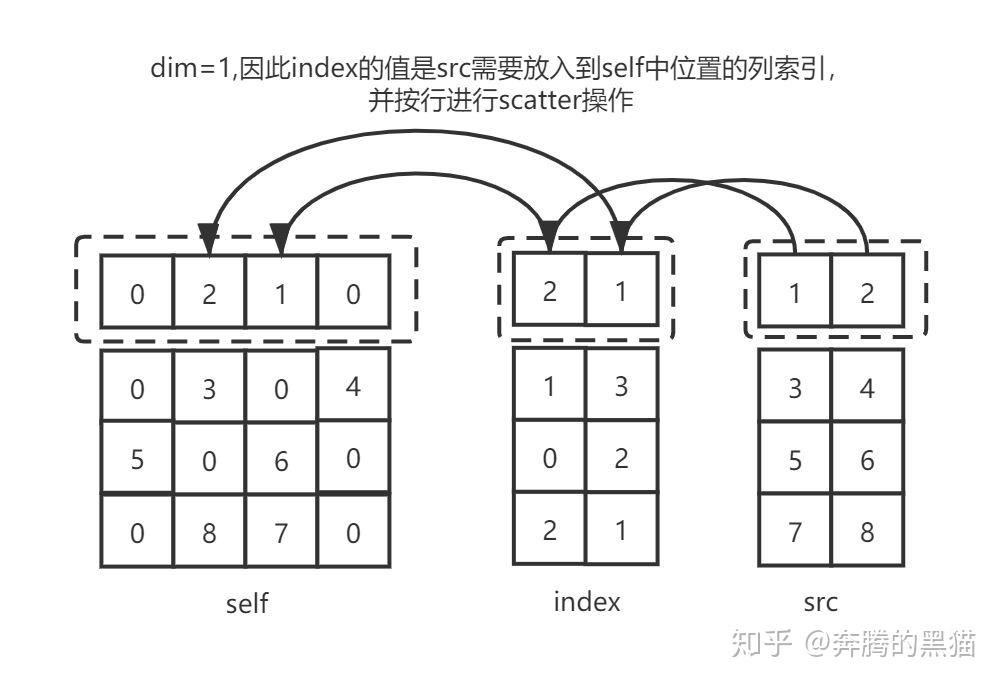
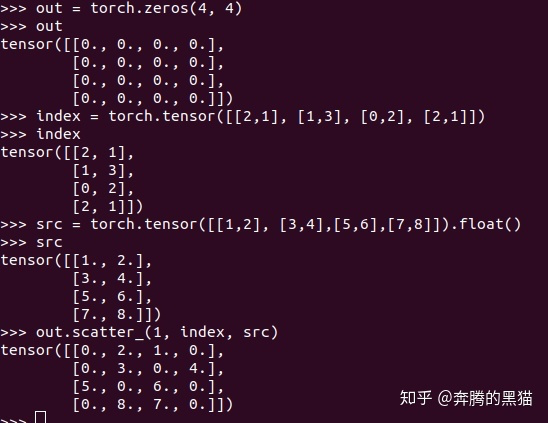
例子2:
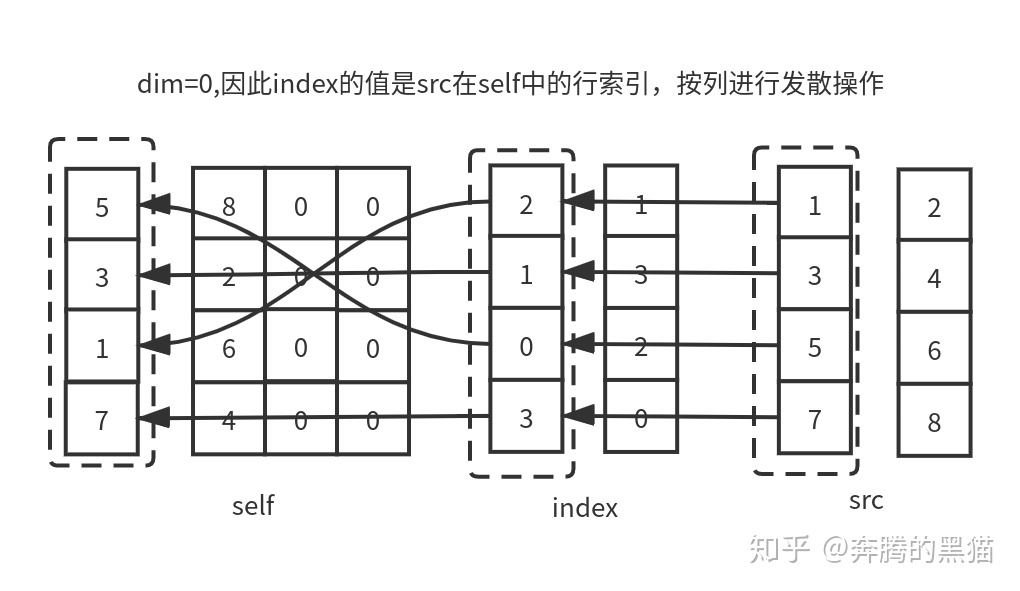
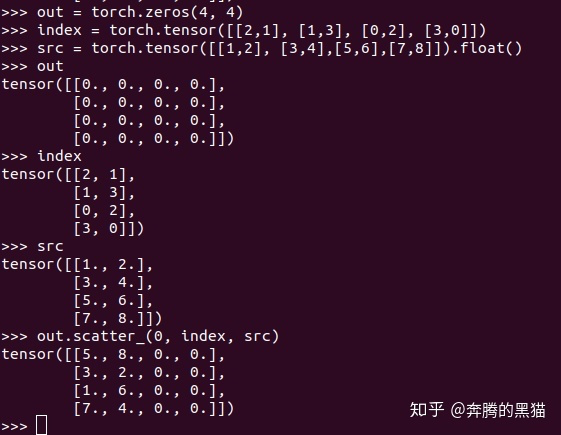
例子3:
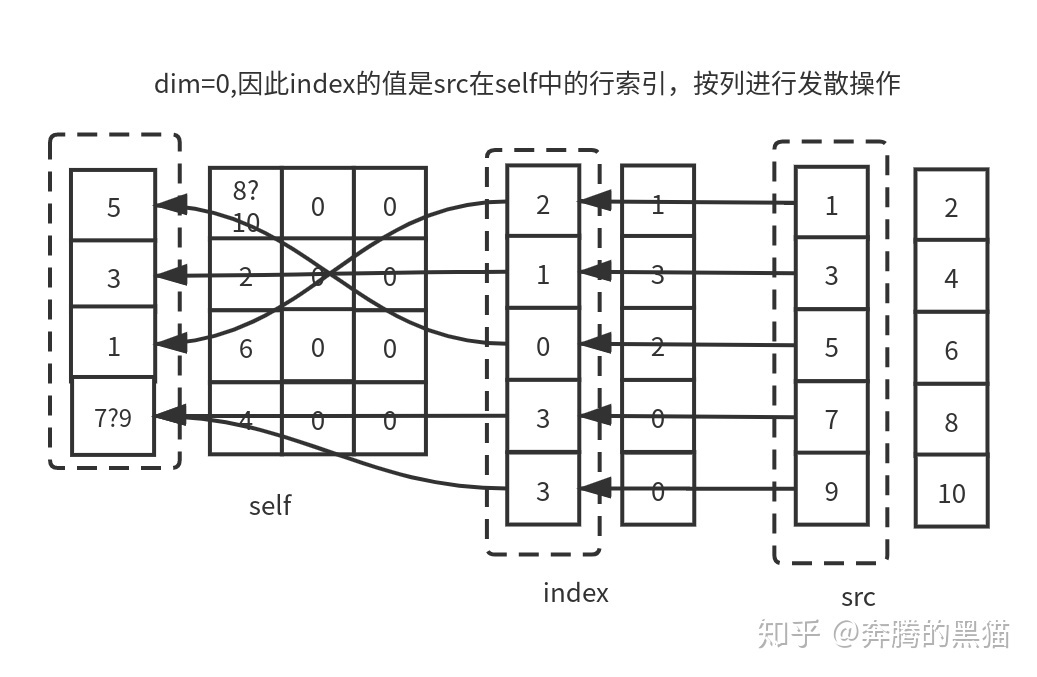
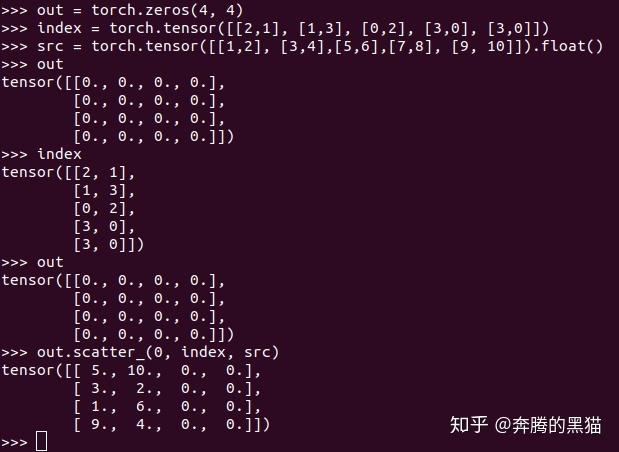
通过例子我们现在可以理解一下scatter的约束条件:
对于约束1:我们不关心张量self和张量src之间的维度大小关系,他们二者的维度大小之间没有任何关系,我们只需要保证他们维度数量相同即可;
对于约束2:因为张量index作为张量src的索引矩阵/向量,其各维度大小必然不可能比src大(因为不可能将一个不存在于src中的值发散到张量self中)
对于约束3和约束4:对于那些d!=dim的维度d来说,其理由和约束2类似(因为不可能将一个src的值发散到一个在张量self中不存在的位置上),而对于那个d==dim的维度来说,index和self之间维度大小没有要求,index.size(dim)可大于self.size(dim)也可小于self.size(dim),如例子3所示。
对于约束5:如果index沿着dim维那一行/列中的值不唯一,如例子3中,index[3][0]和index[4][0]所示,他们都会将与之对应的src[3][0]和src[4][0]中的值发散到self[3][0]的位置,如果在GPU环境下,具体是src[3][0]还是src[4][0]被放入到了位置self[3][0]是不确定的,因为不能确定是哪一个线程覆盖了另一个线程的值,因此对于操作scatter_来说如果不满足约束5会产生无意义的操作(但不会报错)。
带有聚集操作的发散操作scatter_add_
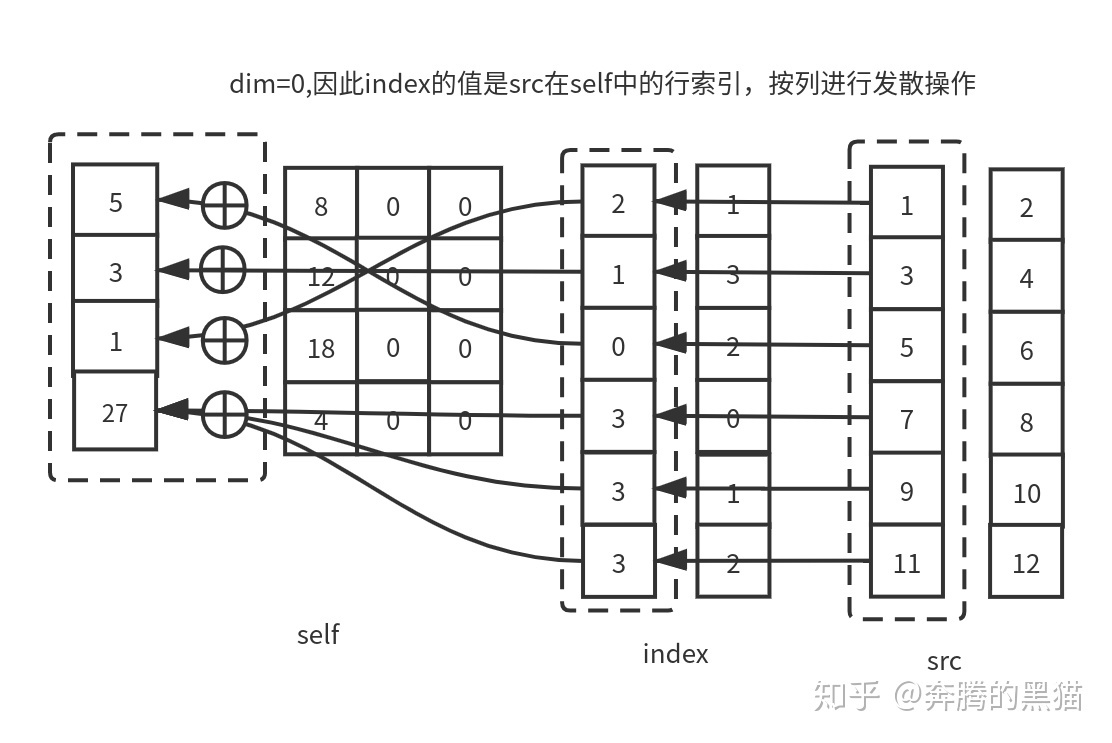
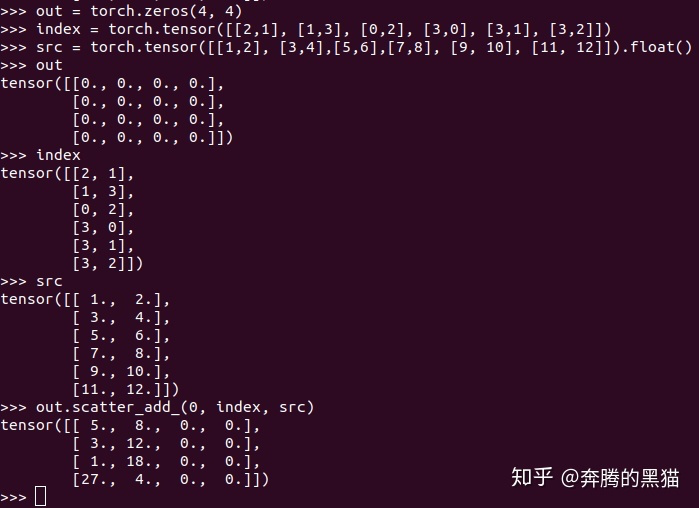
刚才我们介绍了scatter_的含义和5个约束条件,下面要介绍的scatter_add_是scatter_的升级版,其基本操作过程和scatter_一模一样,二者唯一的区别就是在我们之前提到的约束5。
我们之前提到过scatter_操作的约束5保证了保证了最多只会有一个来自src的值被发散到self的某一个位置上,如果有多于1个的src值被发散到self的同一位置那么会产生无意义的操作。而对于scatter_add_来说,scatter_的前四个约束对其仍然有效,但是scatter_add_没有第5个约束,如果有多于1个的src值被发散到self的同一位置,那么这些值将会通过累加的方式放置到self中。具体如下所示:
例子4:
数据聚集操作gather
函数原型:
torch.gather(input,dim,index,out=None,sparse_grad=False)→ Tensor
参数:
- input (Tensor) – the source tensor
- dim (int) – the axis along which to index
- index (LongTensor) – the indices of elements to gather
- out (Tensor,optional) – the destination tensor
- sparse_grad (bool,optional) – If True, gradient w.r.t. input will be a sparse tensor.
gather操作是scatter操作的逆操作,如果说scatter是根据index和src求self(input),那么gather操作是根据self(input)和index求src。具体来说gather操作是根据index指出的索引,沿dim指定的轴收集input的值。
对于一个三维张量来说,gather函数的输出公式为:
| out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0 | |
| out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1 | |
| out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2 |
对于gather操作来说,也有三个约束需要满足:
(1)对于所有的维度d != dim,有input.size(d) == index.size(d),对于维度d==dim来说,有index.size(d) >= 1;
(2)张量out的维度大小必须和index相同;
(3)和scatter一样,index中的索引值必须在input.size(dim)范围内。
例子5(需要和例子1对比的看):
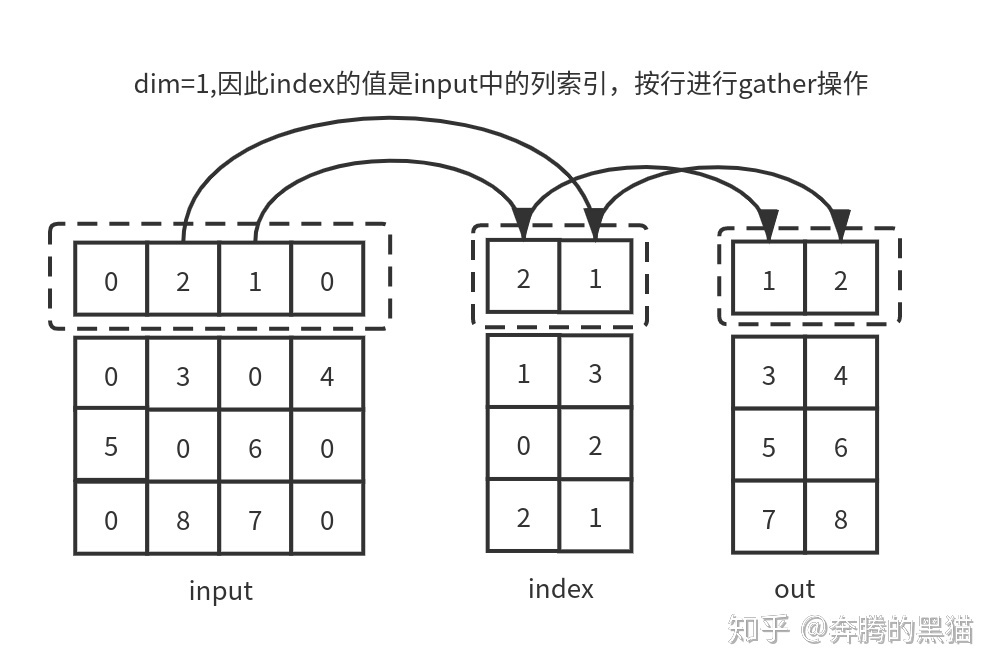
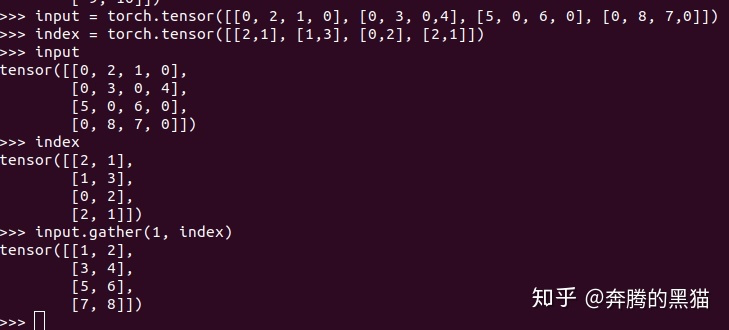
例子6(需要和例子3对比的看):
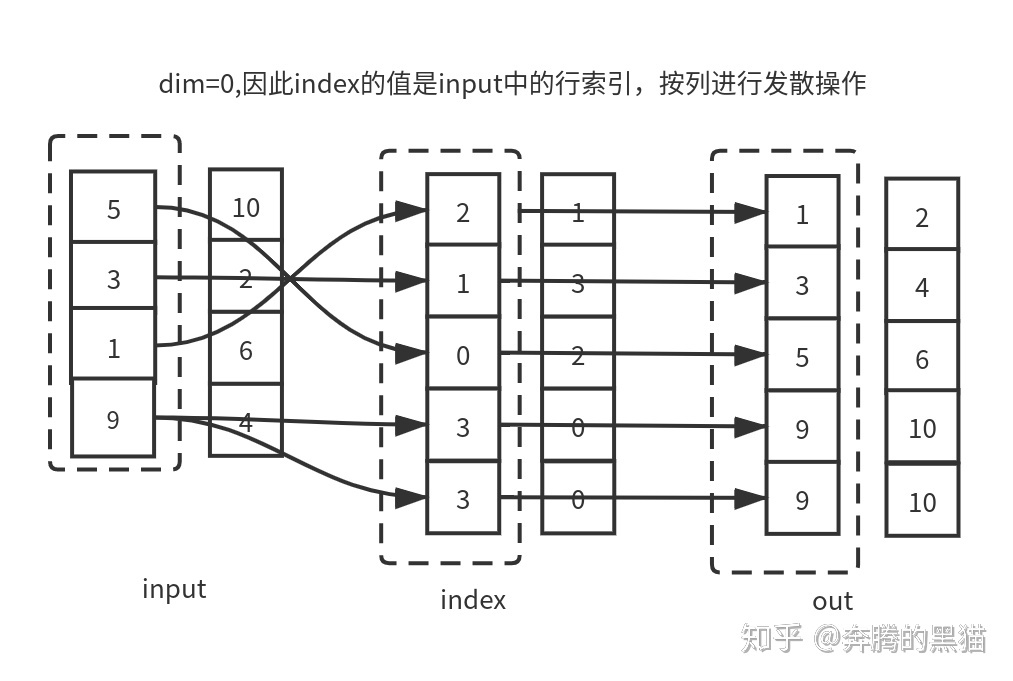
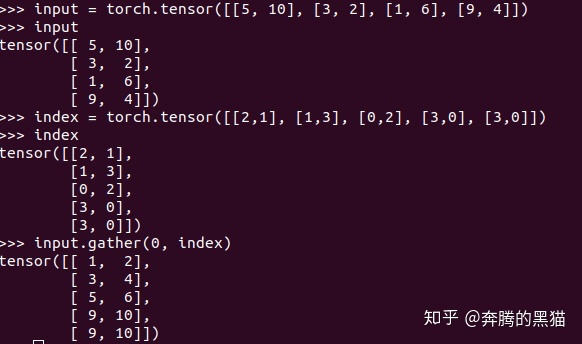
如果我们将例子5和例子1进行对比,将例子6和例子3对比,我们会发现如果不考虑到scatter的覆盖和聚集的问题,gather可以完美复原scatter的操作,即证明了gather是scatter逆过程,二者的数据流动方向正好相反。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理