


Stream.Write 与 StreamWriter.Write 的区别
http://www.cnblogs.com/sorex/archive/2011/11/02/2232056.html
Stream.Write 与 StreamWriter.Write 是我们在向流中写数据时,最常用的方法。
下面就详细讲解这两个方法。
一、测试方法是否结果相同
首先看下面两段代码左侧是StreamWriter.Write 右侧是Stream.Write:
Stream ms = new MemoryStream();
string str = "这是测试字符串";
StreamWriter sw = new StreamWriter(ms, Encoding.UTF8);
sw.Write(str);
sw.Flush();
Stream ms = new MemoryStream();
string str = "这是测试字符串";
byte[] buffer = Encoding.UTF8.GetBytes(str);
ms.Write(buffer, 0, buffer.Length);
ms.Flush();
表面的解读:
(1)把str字符串填写到ms数据流中,都是不能直接写入,要通过中间的过渡。ms是直接的二进制数,相同的二进制数,不同的解码格式会有不同的表现(str),所以有str到二进制的ms,要经过反编码,这种反编码过程就要通过中间的过渡来实现。
Stream.Write:中间是联系str的buffer
StreamReader:中间是联系stream的StreamReader,但是在底层,中间过渡的StreamReader肯定还是联系的str.
上面我们可以看到StreamWriter.Write的可读性更好一些。
但是这两段代码执行后的ms是否是相同的结果呢?
首先我们来看下长度吧,在代码最后分别加上
Console.WriteLine("StreamWriter.Write:{0}", ms.Length);
Console.WriteLine("Stream.Write:{0}", ms.Length);
执行后结果如下: 各位看官,看到这里有何想法?

二、深究原因
下面继续深究一下这个多出来的3个字节
在方法后面都加上如下一段代码将MemoryStream的内容以十六进制的形式打印出来
ms.Position = 0;
byte[] bytes = new byte[ms.Length];
ms.Read(bytes, 0, bytes.Length);
foreach (var item in bytes)
{
Console.Write(item.ToString("X2") + " ");
}
Console.WriteLine(String.Empty);
再次执行结果如下:

这里我们发现用StreamWriter.Write输出多出了EF BB BF这3个字节
Google一下:
多出来的这个玩意是 字节顺序记号(英语:byte-order mark,BOM)
在维基百科中可以查到:

ok,了解了这个东西后我们就需要知道在StreamWriter.Write中能否用代码控制不输出这个BOM吗?
三、查找解决办法
开始反编译StreamWriter.Write这个方法:

大致猜测是红色方框的代码输出了BOM信息,ok再进去看:
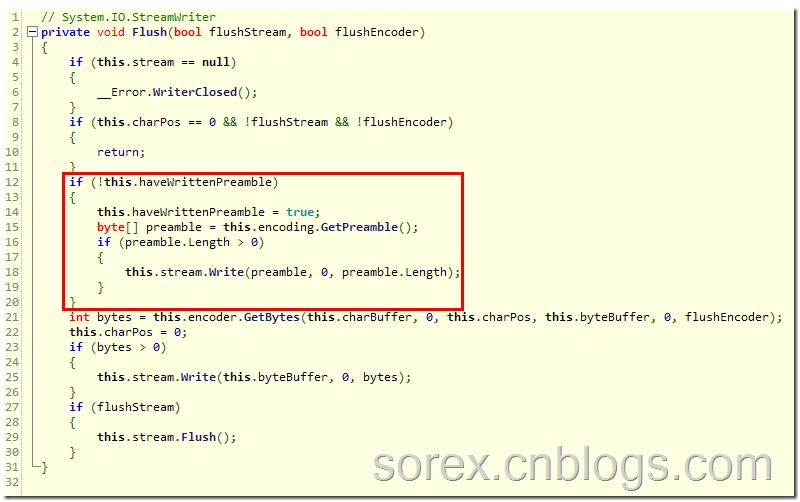
果然在这里,看上图红框处,GetPreamble方法是获取编码的字节序列,和我们之前查到的信息完全一致。 好下面继续找这个haveWrittenPreamble有没设置的可能,在Init方法中找到了它的身影。

杯具了,CanSeed没有set方法,Write之前的Position肯定为0,至此结束。
四、结论 由上面的结论,我们可以确定:
1.如果双方协议无BOM时,可以使用Stream.Write方法来输出,或者使用StreamWriter.Write时加入new UTF8Encoding(false)参数。
2.有BOM时,我们可以通过GetPreamble和Stream.Write来完成StreamWriter.Write的功能。
后期自己的试验:
1、使用streamWriter 将 数据 写入 到流文件中,
StreamWriter sw = new StreamWriter(ms, new UTF8Encoding(true));
StreamWriter sw = new StreamWriter(ms, Encoding.UTF8);
效果一致,都多出3个字节( 字节顺序记号(英语:byte-order mark,BOM))
sw.Write(str); //将str中数据写入sw -->ms
sw.Flush();
(1)使用StreamReader 进行 流文件的读取 显示, 这个BOM自动识别,不予以显示
ms.Position = 0;
StreamReader sr = new StreamReader(ms);
string str2 = sr.ReadToEnd();
Console.WriteLine(str2);
(2)直接把流文件读到 缓存中,通过缓存 的转换为string
ms3.Position = 0;
byte[] bytes4 = new byte[ms3.Length];
ms3.Read(bytes4, 0, bytes4.Length);
for (int i = 0; i < bytes4.Length; i++)
{
Console.Write(bytes4[i].ToString("X2") + " ");
}
如果头部有3个BOM 则显示问好, StreamWriter sw = new StreamWriter(ms, new UTF8Encoding(false)); 可以去掉这3个BOM
2、使用Stream.Write 转化 ,不存在BOM ,直接就是文件的内容,双方的编码方式要一直,这需要双方的协商,而如果都使用StreamReader、StreamWriter,就可以自动识别BOM ,而这也要双方的协商。
3、总结 ,字符串 ---》流 ----》 字符串,前后两个过程都存在着两种转换

字符串----》流 StreamWriter 、Stream.Write( 中间buffer)
要想看这个流的具体内容,都要转换为bytes[] buffer, StreamWriter要转换,Stream.Writer因为中间已经产生了导入到Stream的buffer,所以不用再将Stream转会为buffer,二是直接可以读取前面的buffer。
流--------》字符串 StreamReader、Stream.Read(中间 buffer)
ms3.Position = 0;
StreamReader sr = new StreamReader(ms3);
string str5 = sr.ReadToEnd();
Console.WriteLine(str5);
3、缓冲区 的相关 操作 (这个地方的缓冲区 定义为字节数据,所以里面存储的为字节数据,如果定义为其他类型,则存储其他类型)
(1)、byte[] buffer = Encoding.UTF8.GetBytes(str); :外部string内容 编码 存储到缓存中
(2)、Encoding myEncoding = Encoding.GetEncoding("gb2312");string str2 = myEncoding.GetString(buffer2); 缓存内容到外部string 的转换
(3)、ms.Position = 0;byte[] bytes = new byte[ms.Length]; System.IO.Stream.Read(bytes, 0,bytes.Length); 外部流内容 读取到 缓存中(流中是字节)
(4)、System.IO.Stream.Write(buffer, 0, buffer.Length); 内部缓存区 内容 写入到流中

