

对比学习简记
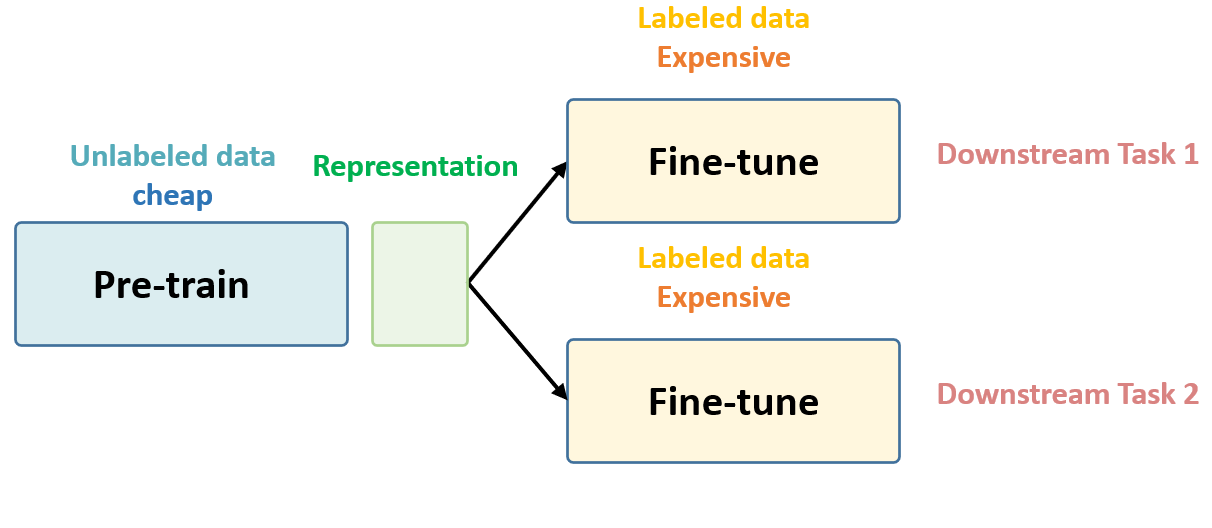
Self-Supervised Learning 的核心思想
Unsupervised Pre-train, Supervised Fine-tune.
两大主流方法
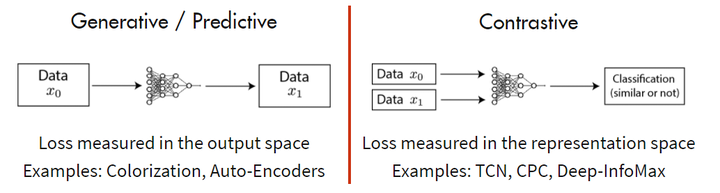
- 基于 Generative 的方法
- 基于 Contrative 的方法
基于 Generative 的方法主要关注的重建误差,还原原始输入;
基于Contrastive 的方法不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨,判断输入是否相似。
实践应用
- BERT系列:nlp
- VIT系列:cv
- data2vec系列:multimodal
- SimCLR系列:对比学习
- MoCo系列
Contrastive Representation Learning
对比学习指导原则
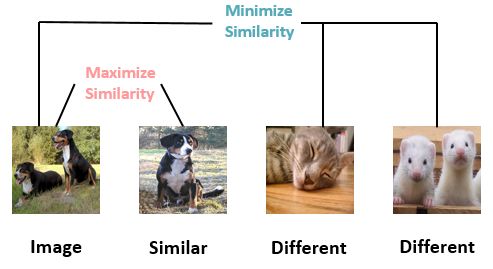
- 构造相似实例和不相似实例
- 习得一个表示学习模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远
对比学习目标函数
Contrastive Loss
最早的Loss是对比Loss,即同类样本间更相似,最小化同类样本的embedding 距离,最大化非同类embedding的距离
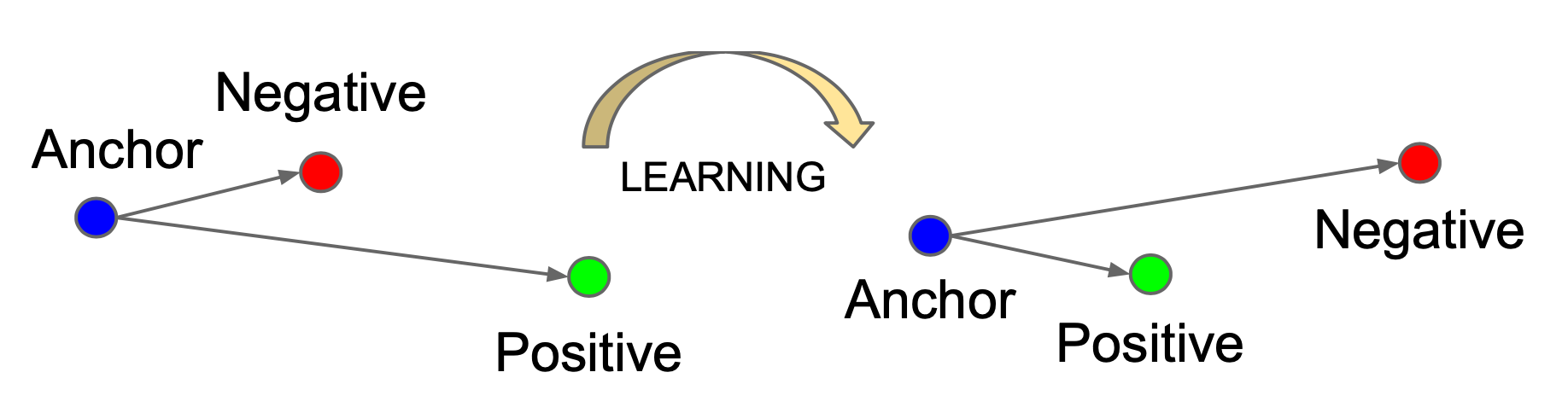
Triplet Loss
Triplet loss最小化anchor和正样本间的距离,最大化anchor和负样本间的距离
关键:选择合适的负样本,提升模型性能
N-pair Loss
Multi-Class N-pair loss generalizes triplet loss to include comparison with multiple negative samples.
Given a tuplet of training samples,, including one positive and negative ones, N-pair loss is defined as:
当负样本数量为1时,等价于多分类softmax。
NCE
把多分类问题转化成二分类,判断正样本和负样本是否为同一类。
其中 target sample , noise sample .
InfoNCE
假设我们忽略,那么infoNCE loss其实就是cross entropy loss。唯一的区别是,在cross entropy loss里,
指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个指的是负样本的数量.
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差.
对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用 - Youngshell的文章 - 知乎 https://zhuanlan.zhihu.com/p/506544456
对比学习关键点
数据增强
对原始数据增加噪音等数据增强,生成正样本。
如SimCLR表明,随机裁剪和随机颜色失真对视觉表示学习非常关键。
大的BatchSize
对依赖In-batchNegative的场景,大的batch size可以提高训练效率,增加模型挑战。
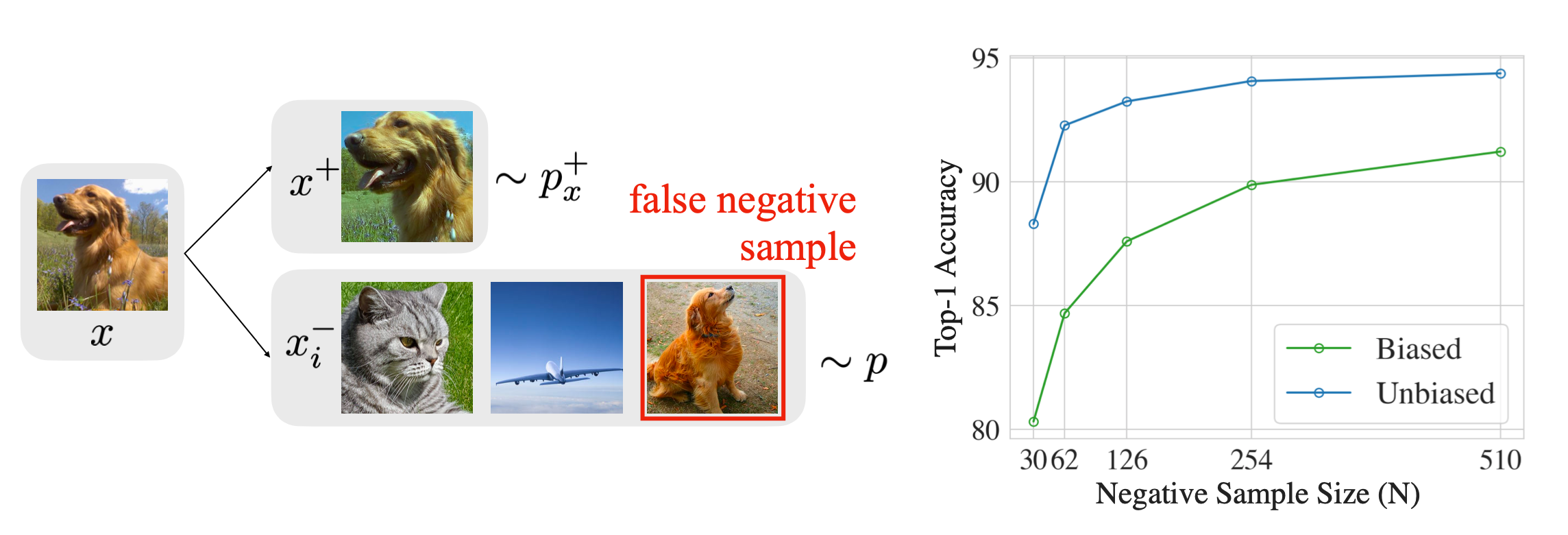
hard Negative Mining
对于有监督情况,可以直接将其它类样本作为负样本;
对于无监督情况,可能会偶然把同类样本作为负样本,导致性能大幅下降。
vision
Image Augmentation
裁剪、缩放、加噪、翻转、转换灰度图
常用框架:AutoAugment、RandAugment、PBA、UDA
图像混合
SimCLR
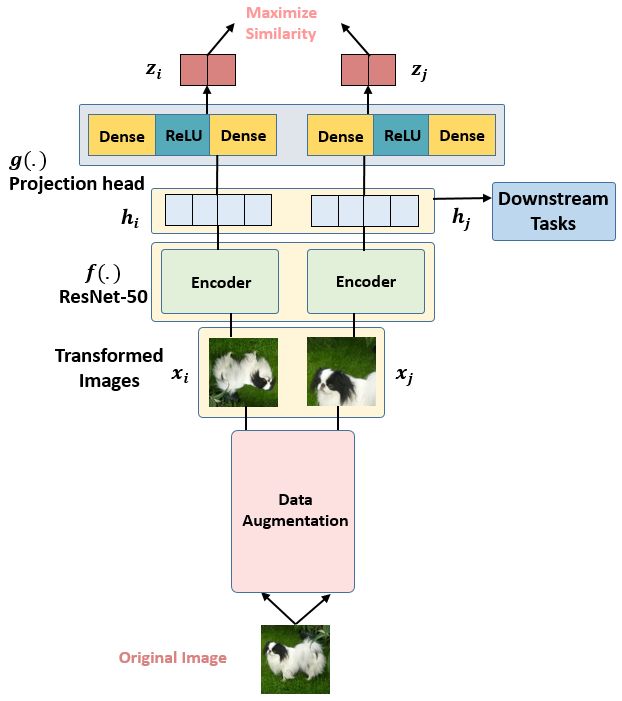
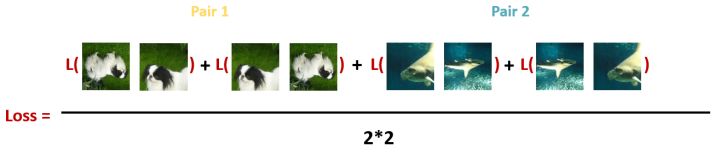
loss, 每个Batch里面的所有Pair的损失之和取平均:
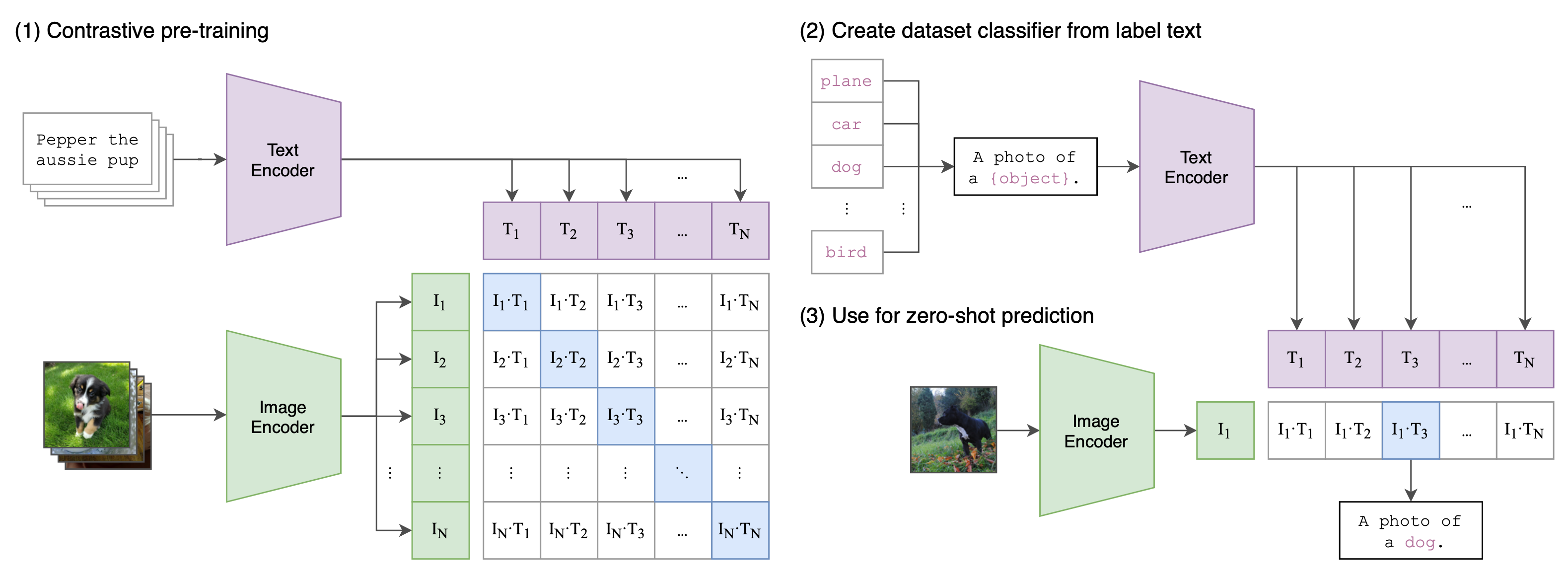
CLIP
nlp
Text Augmentation
编辑距离、随机替换、删除等
SimCSE
Unsupervised SimCSE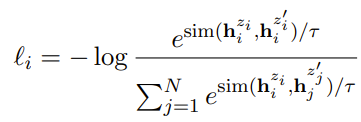
Supervised SimCSE
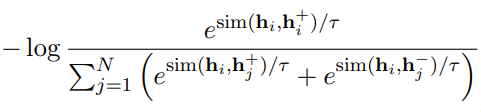
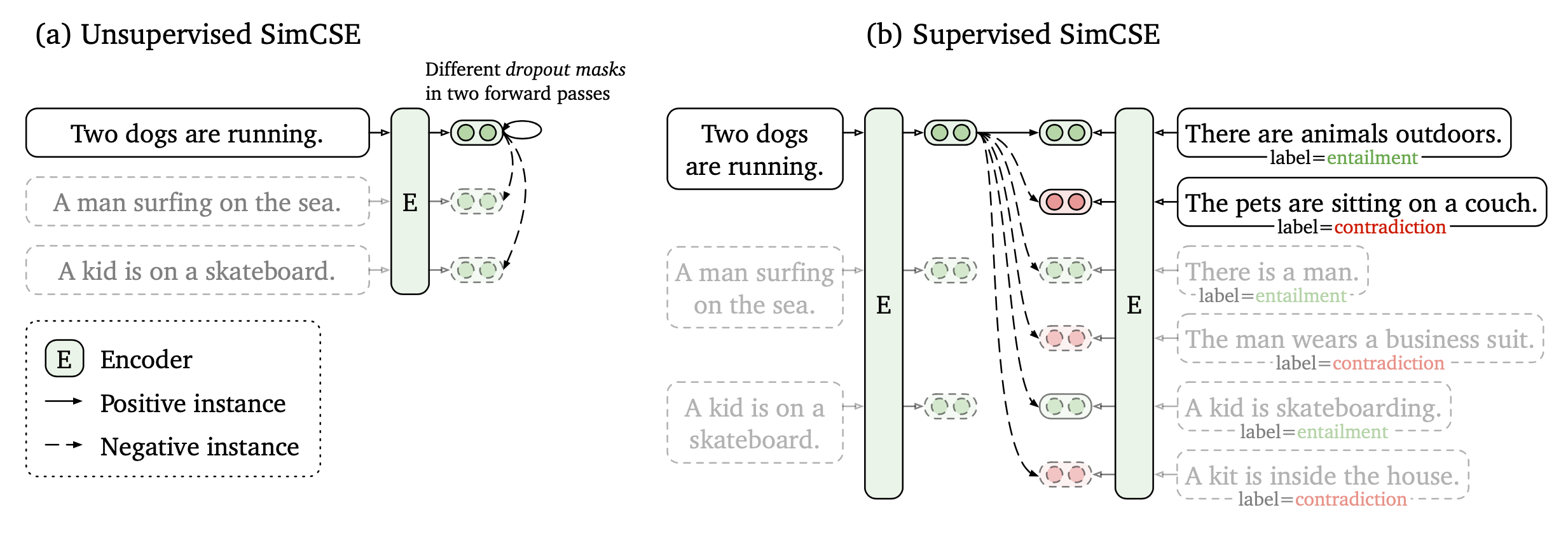
SimCSE2 中改进了两点:
- 负样本质量,原本都是同一句话的embedding dropout,但句子长度相同,会导致模型倾向。
- batchsize过大,引起性能下降,未解之谜
def unsup_loss(y_pred, lamda=0.05, device="cpu"):
idxs = torch.arange(0, y_pred.shape[0], device=device)
y_true = idxs + 1 - idxs % 2 * 2
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
similarities = similarities - torch.eye(y_pred.shape[0], device=device) * 1e12
similarities = similarities / lamda
loss = F.cross_entropy(similarities, y_true)
return torch.mean(loss)
def sup_loss(y_pred, lamda=0.05, device="cpu"):
row = torch.arange(0, y_pred.shape[0], 3, device=device)
col = torch.arange(y_pred.shape[0], device=device)
col = torch.where(col % 3 != 0)[0]
y_true = torch.arange(0, len(col), 2, device=device)
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
similarities = torch.index_select(similarities, 0, row)
similarities = torch.index_select(similarities, 1, col)
similarities = similarities / lamda
loss = F.cross_entropy(similarities, y_true)
return torch.mean(loss)
References
【1】对比学习(Contrastive Learning):研究进展精要. https://zhuanlan.zhihu.com/p/367290573
【2】https://lilianweng.github.io/posts/2021-05-31-contrastive/
【3】Self-Supervised Learning 超详细解读 (目录) - 科技猛兽的文章 - 知乎 https://zhuanlan.zhihu.com/p/381354026
【4】对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用 - Youngshell的文章 - 知乎 https://zhuanlan.zhihu.com/p/506544456


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!