

GPT系列简记
GPT系列
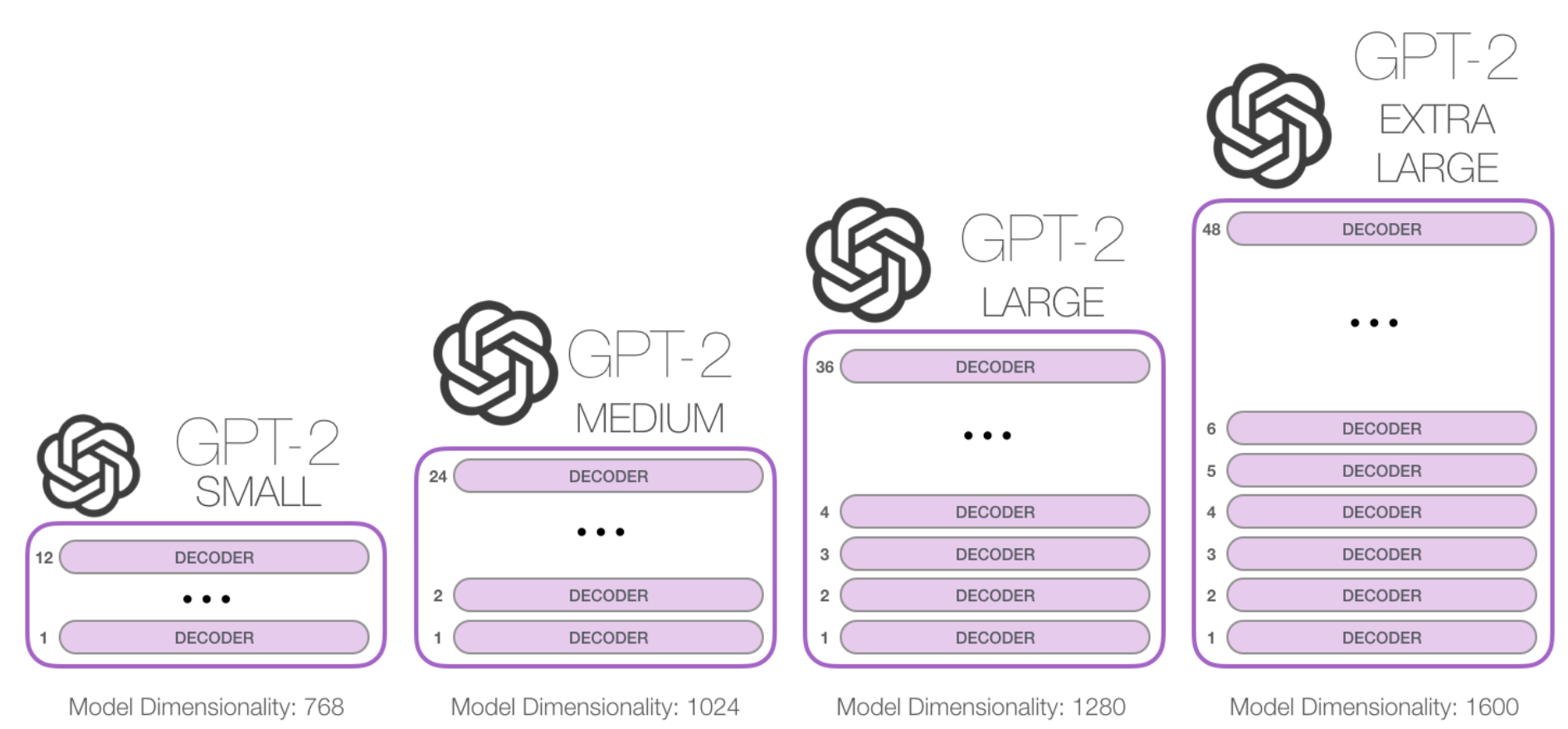
GPT2
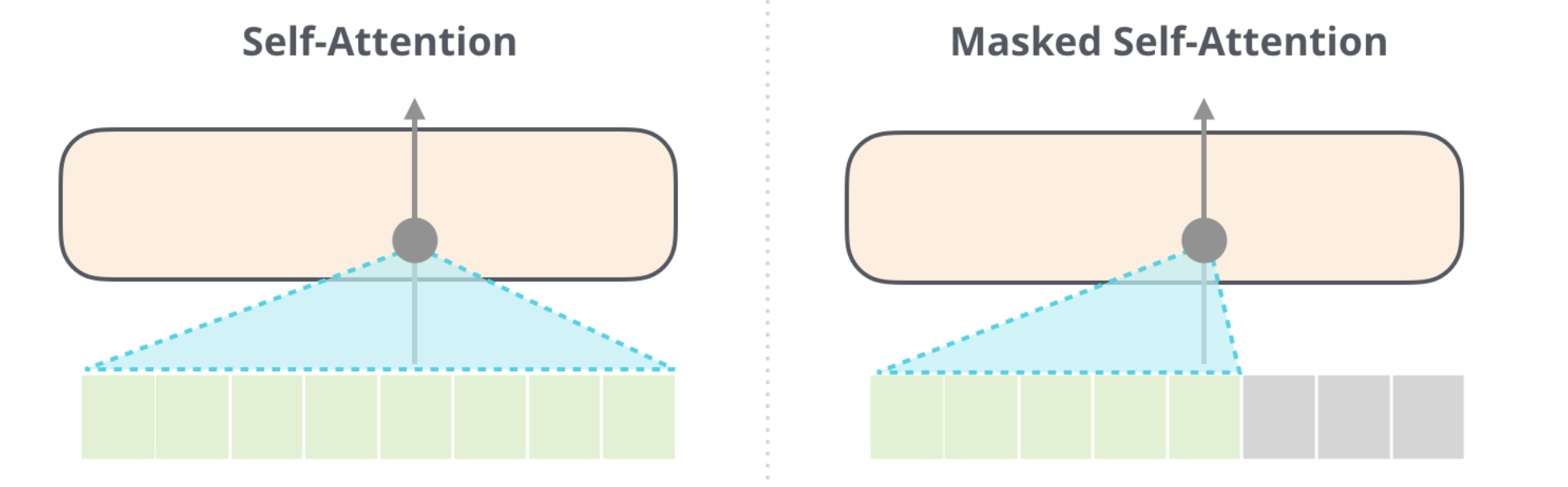
The GPT-2 is built using transformer decoder blocks. BERT, on the other hand, uses transformer encoder blocks.
auto-regressive: outputs one token at a time

GPT3
96 transformer decoder layers. Each of these layers has its own 1.8B parameter
The difference with GPT3 is the alternating dense and sparse self-attention layers.
InstructGPT
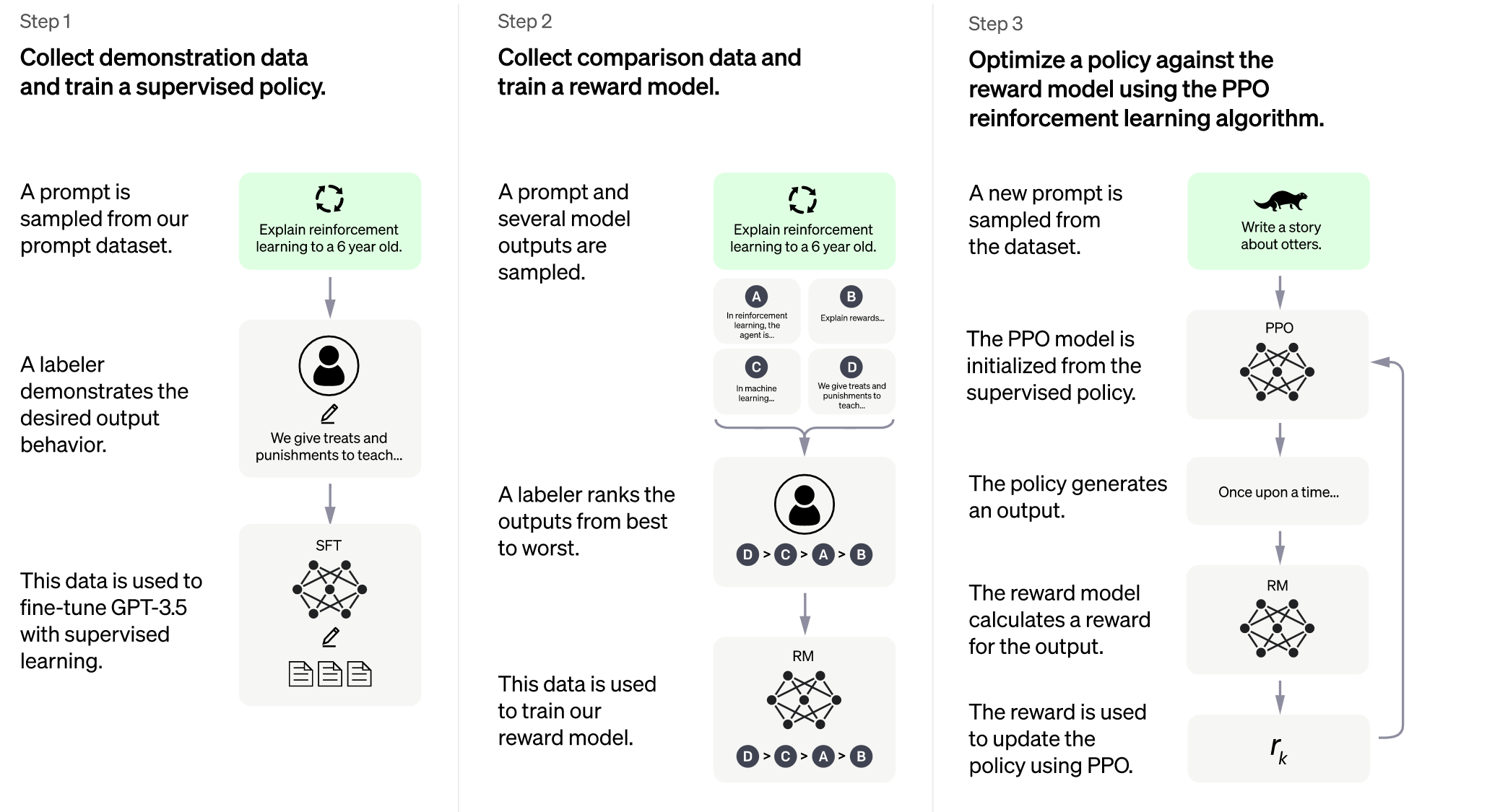
Step 1: Collect demonstration data, and train a supervised policy. Our labelers provide demonstrations of the desired behavior on the input prompt distribution (see Section 3.2 for details on this distribution). We then fine-tune a pretrained GPT-3 model on this data using supervised learning.
Step 2: Collect comparison data, and train a reward model. We collect a dataset of comparisons between model outputs, where labelers indicate which output they prefer for a given input. We then train a reward model to predict the human-preferred output.
Step 3: Optimize a policy against the reward model using PPO. We use the output of the RM as a scalar reward. We fine-tune the supervised policy to optimize this reward using the PPO algorithm (Schulman et al., 2017).
Steps 2 and 3 can be iterated continuously; more comparison data is collected on the current best policy, which is used to train a new RM and then a new policy. In practice, most of our comparison data comes from our supervised policies, with some coming from our PPO policies.
SFT: input prompt,output response
RM:input prompt and response, and output a scalar reward,即指定prompt,给response打分
RL:使用PPO微调SFT,RM作为值函数
chatGPT
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
sparrow[类chatgpt]
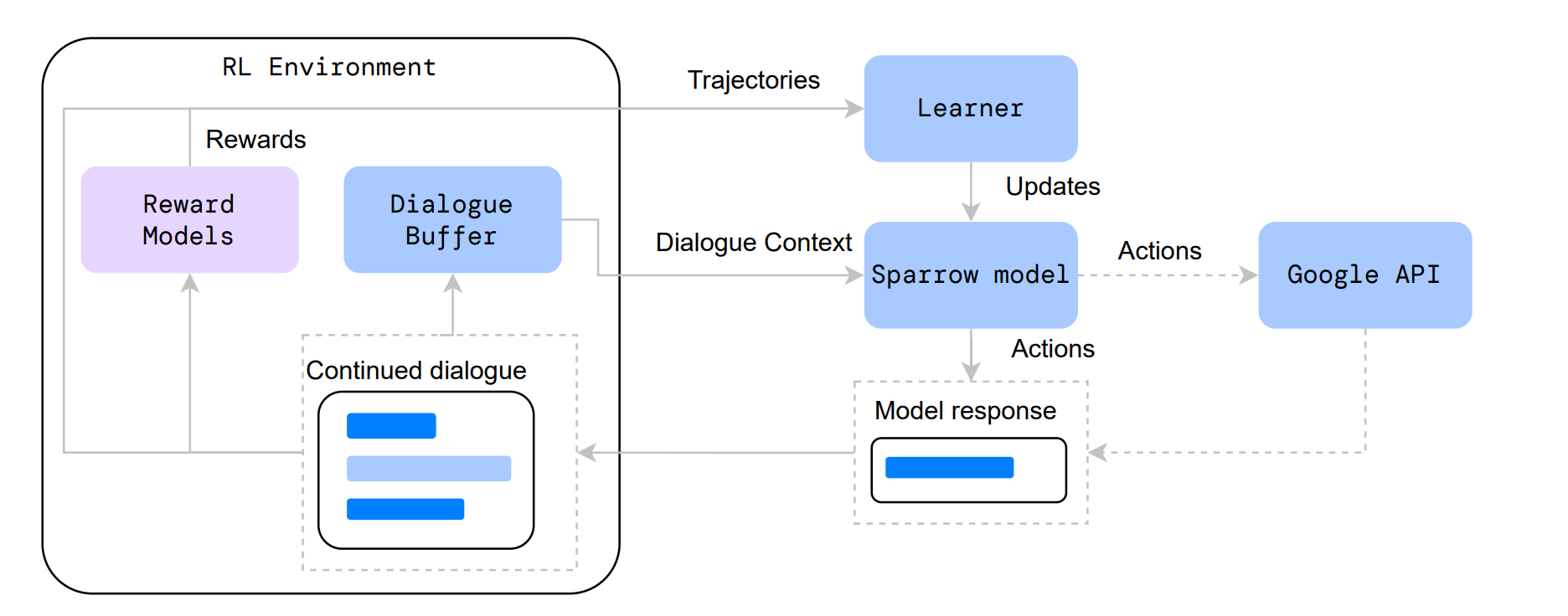
references
https://jalammar.github.io/illustrated-gpt2/
https://openai.com/blog/chatgpt/
Sparrow. https://www.deepmind.com/blog/building-safer-dialogue-agents


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!