
SVM之不一样的视角
在上一篇学习SVM中 从最大间隔角度出发,详细学习了如何用拉格朗日乘数法求解约束问题,一步步构建SVM的目标函数,这次尝试从另一个角度学习SVM。
回顾监督学习要素
-
数据:(xi,yi)
-
模型 ^yi=f(xi)
-
目标函数(损失函数+正则项) l(yi,ˆyi)
-
用优化算法求解
SVM之Hinge Loss
-
模型
svm要寻找一个最优分离超平面,将正样本和负样本划分到超平面两侧
f(x)=w⊤⋅x+b
-
目标函数
minw,bN∑i=1max(0,1−yi(w⊤⋅xi+b))+λ||w||2损失函数+正则化
-
优化算法
梯度下降(求导时需要分段求导,见[1])
为什么是Hinge Loss
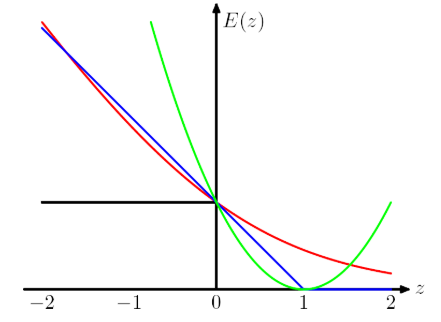
- 保持了支持向量机解的稀疏性
上图横轴 yf(x)>0 表示预测和真实标签一样,纵轴表示损失。可以看处Hinge Loss 和其他loss的区别在于,当 yif(xi)≥1 时,损失函数值为 0,意味着对应的样本点对loss没有贡献,就没有参与权重参数的更新,也就是说不参与最终超平面的决定,这才是支持向量机最大的优势所在,对训练样本数目的依赖大大减少,而且提高了训练效率。
[1] https://blog.csdn.net/oldmao_2001/article/details/95719629
[2] https://www.cnblogs.com/guoyaohua/p/9436237.html
[3] https://blog.csdn.net/qq_32742009/article/details/81432640


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架