
学习SVM
SVM家族简史
故事要从20世纪50年代说起,1957年,一个叫做感知器的模型被提出,
1963年, Vapnik and Chervonenkis, 提出了最大间隔分类器,SVM诞生了。
1992年,Vapnik 将核方法用于SVM,使SVM可以处理线性不可分数据
1995年,Corts和Vapnik引入了软间隔,允许SVM犯一些错
最强版SVM出现了,它将各式武学集于一身,软间隔、核方法、……,
1996年,SVR(support vector regression)诞生,svm家族又添一员,回归任务也不在话下。至此,SVM家族成为机器学习界顶级家族之一。关于SVM家族其他成员,可以参阅这里。
SVM是什么?
- 是一种监督学习分类算法,可以用于分类/回归任务
- SVM目标:寻找最优分割超平面以最大化训练数据的间隔
什么是超平面?
- 在一维空间,超平面是一个点
- 二维空间,超平面是一条线
- 三维空间,超平面是一个平面
- 更多维空间,称为超平面
什么是最优分割超平面?
- 尽可能远离每一个类别的样本点的超平面
- 首先,可以正确的将训练数据分类
- 其次,拥有更好的泛化能力
那么如何找到这个最优超平面呢?根据间隔

什么是间隔?
给定一个超平面,超平面到最近的样本点之间的距离的2倍称为间隔。
在最初的SVM中,间隔是一个强定义,即硬间隔,间隔之间不允许存在任何样本。(当数据中存在噪音时,会产生一些问题,所以后来软间隔被引入)
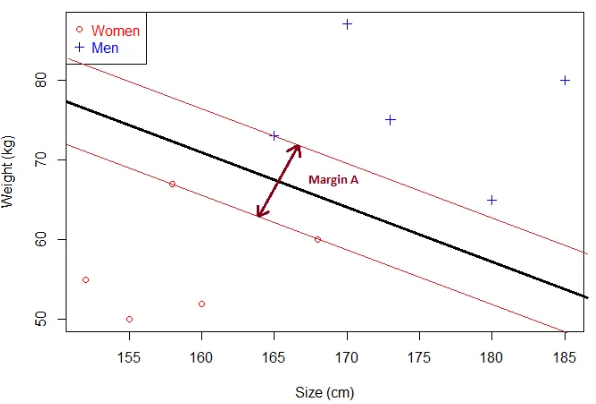
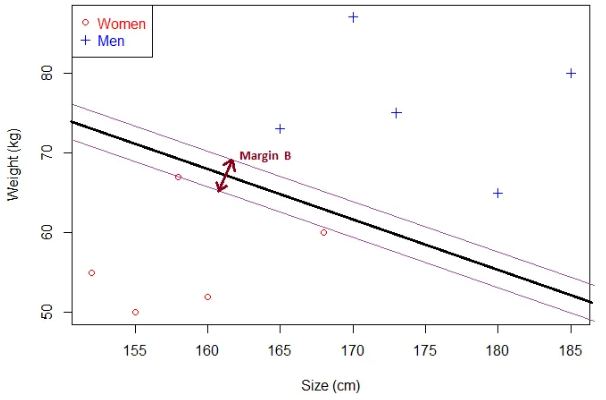
显然,间隔B小于间隔A。可知:
- 如果超平面越接近样本点,对应的间隔越小
- 超平面离样本点越远,间隔越大
所以最优超平面对应最大间隔,SVM就是围绕着这个间隔展开,如何计算这个间隔?👇👇👇
感知机模型
感知机是什么?
- 是一种二元线性分类器
- 利用梯度下降法对损失函数进行极小化,求出可将训练数据进行线性划分的分离超平面
感知机如何找到分离超平面?
-
定义目标函数,优化求解
对分类超平面 f(xi)=w⊤x+b
- 初始化 w
- 循环对每个样本执行
- w←w+αsign(f(xi))xi 如果xi 被误分类
- 直到所有数据被正确分类
最大间隔
对感知机来说,后三个超平面都是对应的解。显然最后一个是更优的解,但是感知机并不知道,SVM登场了。SVM说,既然间隔更大的超平面对应更优解,那我就计算间隔。
怎么计算间隔?
可以用点到直线距离,对超平面
如何找到最优超平面?
超平面和间隔是直接相关的。
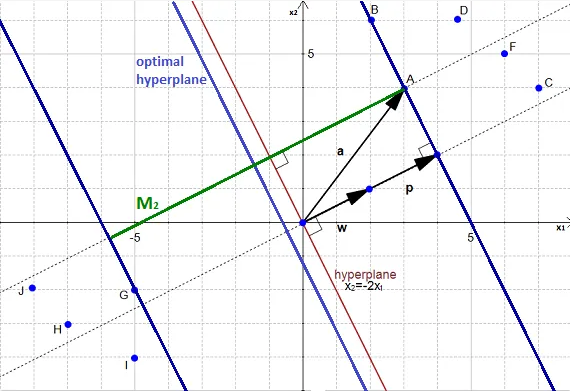
- 如果有一个超平面,可以根据样本计算间隔
- 如果有两个超平面界定了一个间隔,我们可以找到第三个超平面
所以 寻找最大间隔 = 寻找最优超平面
如何找到最大间隔?
step1: 需要有label的数据集
step2: 选择两个超平面划分数据,并且超平面之间没有数据
step3: 最大化两个超平面之间的距离(即为间隔)
说起来很简单,下面我们从数学角度看如何求解这一问题。
-
step1:数据集
样本 xi,对应的label yi∈{−1,1},含有 n 个样本的数据集表示为 D
D=(xi,yi)∣xi∈Rp,yi∈−1,1
-
step2:选择两个超平面
假设数据 D是线性可分的
对于分类超平面 w⋅x+b=0 , 记为H0,选择另外两个超平面H1,H2 ,满足H0到H1 和 H2等距,分别定义如下:
w⋅x+b=δw⋅x+b=−δ但是 δ 是多少?不确定。为了简化问题,我们假设 δ=1 ,为了确保两个超平面之间没有数据,必须满足以下约束:
w⋅xi+b≥1,if yi=1w⋅xi+b≤−1,if yi=−1将式(1) 两边同时乘以 yi:
yi(w⋅xi+b)≥1,for 1≤i≤n -
step3: 最大化两个超平面之间的距离
最大化两个超平面之间距离,怎么计算距离?怎么最大化距离?
如何计算两个超平面之间距离?

记 H0,H1 分别为 w⋅x+b=1,w⋅x+b=−1
假如 x0 为线上的点,m 记为两线间距离。我们的目标:求 m
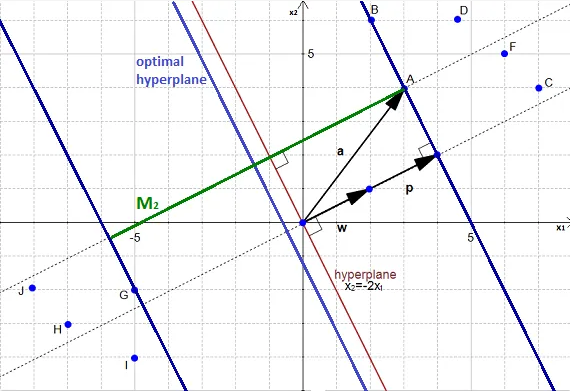
如果存在一个向量 k , 满足 ||k||=m ,同时垂直于 H1,我们就能在 H1 找到对应的点 z0。现在我们看看怎么找这个点?
首先定义 u=w||w|| 为 w 的单位向量,单位向量模长等于1,即||u||=1。对一个标量乘以一个向量得到的结果是向量,所以我们将 m 和单位向量 ||u|| 的乘积记为k。
k=mu=mw||w||根据向量加法 z0=x0+k,如上图。我们找到了x0 对应的 z0。现在
w⋅z0+b=1w⋅(x0+k)+b=1w⋅(x0+mw||w||)+b=1w⋅x0+mw⋅w||w||+b=1w⋅x0+m||w||2||w||+b=1w⋅x0+m||w||+b=1w⋅x0+b=1−m||w||因为 w⋅x0+b=−1,所以
−1=1−m||w||m||w||=2m=2||w||我们计算出了 m !!!两个超平面之间的距离。
最大化间隔
上面我们只做了一件事,计算间隔。现在我们看看怎么最大化它
显然上述问题等价于:
minmize ||w||s.t.yi(w⋅xi+b)≥1for i=1,2,⋯,n求解上述问题,得到最优解,我们就找到了最优超平面。
最大间隔的数学解
再探问题(4),这是一个带不等式约束的最优化问题,而且是 n 个约束(n 个点都需要满足)。这个问题很头疼,好吧。我们先偷个懒,如果是无约束问题怎么求。
-
无约束问题最小化
对无约束问题,表示为 f(w)=||w||,我们如何求函数 f 的局部极小值?求导。
如果f 二阶可导,在点 x∗ 满足 ∂f(x∗)=0,∂2f(x∗)>0,则在 x∗ 处函数取极小值。注意:x 是一个向量,导数为0,对应每个维度皆为0。
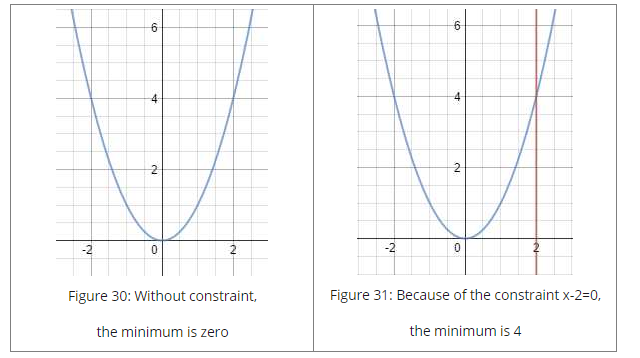
对于无约束最小值为0,等式约束下最小值为4。
-
等式约束
-
单个约束
假如有等式约束问题如下
minimizexf(x) subject to g(x)=0上面的问题相当于定义了一个可行域,使得解只能在可行域内。上图中表示可行域只有一个点,因此问题很简单。
-
多个约束
对于带有多个等式约束的问题,所有的约束必须都满足
minimizexf(x) subject to g(x)=0h(x)=0上述等式约束问题怎么解?猜猜这是谁🙃

拉格朗日乘法
In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints. (Wikipedia)
三步法:
- 对每个约束乘以拉格朗日乘子,构建拉格朗日函数 L
- 求拉格朗日函数梯度
- 令梯度 ∇L(x,α)=0
为什么拉格朗日乘法可以解等式约束问题?我们来看看
minimizex,yf(x,y)=x2+y2 subject to gi(x,y)=x+y−1=0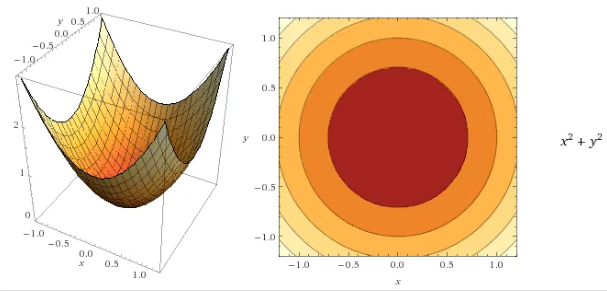
根据目标函数和约束函数,我们可以画出等高线
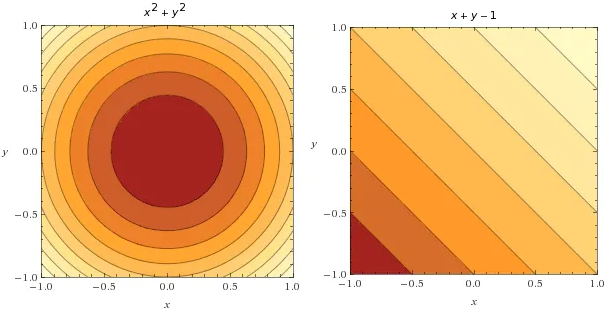
将两张图合并到一起会发生什么(黑色箭头表示目标函数梯度方向,白色箭头表示约束函数梯度方向)
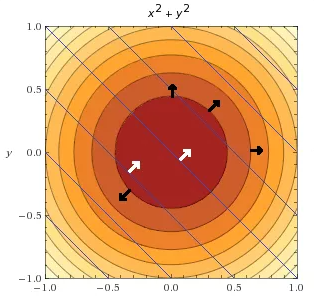
回到约束函数 g(x,y)=x+y−1=0,我们找一找它在哪,当x=0 时 y=1,当 y=0 时x=1,找到了,在这里
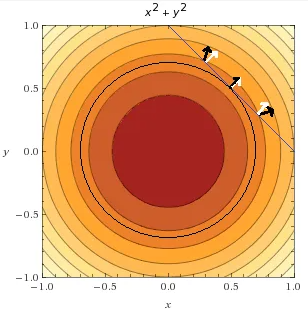
发现什么了?目标函数在约束函数处的梯度方向相同!它们相切了,而且只有一个点处的梯度方向完全相同,这个点就是目标函数在约束下的的极小值。
why?假如你处在上图最上面的箭头位置(值为 v),在约束条件下,只能在蓝线上移动,你只能尝试向左或者向右找到更小的值。ok,先尝试向左走,发现值变大了(梯度方向也是左,梯度指向函数上升最快的方向),所以应该向右走,直到走到切点处。此时,发现无论向那个方向走,值都会变大,因此,你找到了极小值。
-
数学表示
如何表达在极小值处,目标函数和约束函数梯度方向相同
∇f(x,y)=λ∇g(x,y)乘 λ 干啥?因为他们只是梯度方向相同,大小不一定相等。 λ 称为拉格朗日乘子。
(注意 λ 如果是负数,两个梯度方向变为平行,可以同时求极大极小值,见例1.)
现在我们知道拉格朗日乘法为什么可以求等式约束问题,那怎么求?
-
找到满足∇f(x,y)=λ∇g(x,y) 的 (x,y)
显然,∇f(x,y)−λ∇g(x,y)=0,定义函数 L 有:
L(x,y,λ)=f(x,y)−λg(x,y)求导:
∇L(x,y,λ)=∇f(x,y)−λ∇g(x,y)当导数为0时就找到了对应 f 和 g 梯度方向平行的点。
回到定义,拉格朗日乘法只能解决等式约束问题,那对下面的不等式约束问题怎么办?
-
-
不等式约束
minimizexf(x) subject to g(x)≥0Don't worry! 总有办法🙃
对不等式约束问题,同样可以使用拉格朗日乘数,满足如下条件:
g(x)≥0⇒λ≥0g(x)≤0⇒λ≤0g(x)=0⇒λ is unconstrained为什么呢?因为可行域。看图就知道了,在等式约束部分x+y−1=0 时,可行域在直线上;当x+y−1≥0 时,可行域在右上角,λ 大于0表示梯度方向指向可行域;同理可知小于等于的情况。然后和等式约束求解过程一样就可以了。关于拉格朗日对约束问题例子,推荐阅读[3].
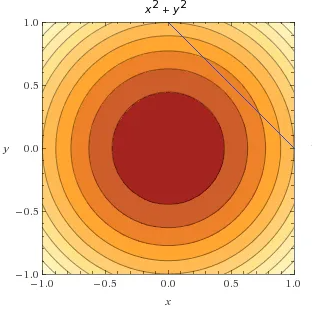
我们在来看看对偶问题。
-
对偶问题
In mathematical optimization theory, duality means that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem (the duality principle). The solution to the dual problem provides a lower bound to the solution of the primal (minimization) problem. (Wikipedia)
“对偶问题是原问题的下界”,下界是啥?😖
给定一个部分有序集合 R ,如果存在一个元素小于或等于 R 的子集的每个元素,该元素就可以称为下界。百度百科
举个栗子:
给定 R 的一个子集:S={2,4,8,12}
1. 1 小于 $S$ 中每个元素, 1 可以是一个下界 2. 2 小于等于$S$ 中每个元素, 2 也可以是一个下界由于 2 大于其他的下界,被称为 下确界 (最大下界)。下界有无穷个,但最大下界是唯一的。
回到对偶问题
如果原问题是一个极小问题,对偶问题可以将其转化为求极大问题。极大问题的解就对应原极小问题的下界。有点不解其意,继续看👇
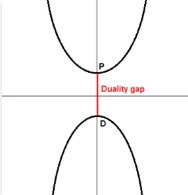
上图原问题是一个极小问题, P 是极小点。对偶问题是一个极大问题, D 是极大点。很明显, D 是一个下界。 P−D 被称为对偶间隔,如果 P−D>0 对应弱对偶性。如果 P−D=0 对应强对偶性。
-
回到SVM最优化问题
为了求解方便,将等式(4)改写为凸二次型优化问题(convex quadratic optimization problem),
根据拉格朗日乘数法:
可以转化为:
为什么原问题变成极大极小问题了?这里有多个解释,直观来看,我们要 min \ \mathcal{L}(\mathbf{w}, b, \alpha) ,由于后一项 \alpha >0,y_{i}\left(\mathbf{w} \cdot \mathbf{x}_{i}+b\right)-1 \geq0,正数减正数,后一项越大对应整体值越小。
求解上述极大极小问题,求导:
将(7)带回到(6)
只剩下 \alpha 了, 根据Wolfe dual problem:
- KKT 条件
The KKT conditions are first-order necessary conditions for a solution of an optimization problem to be optimal
回到式(8),同乘 -1 转化为极小问题
软间隔SVM
由于原始SVM只能处理线性可分数据,那如果存在异常点会怎么样?我们来看看

图中出现了一个蓝色的异常点,使得原本线性可分问题变得难以解决。软间隔出场了,1995年,Vapnik and Cortes 在原始SVM的基础上引入了松弛变量,允许模型“犯错”。在原约束的基础上增加一个变量 \xi
我们来看看不同的 \xi 对应的情况
- 0\leq \xi \leq 1 ,样本在间隔之间,依然处于正确侧,称为间隔冲突
- 1 \leq \xi ,样本被误分类
- \xi 必须大于0,否则就没有存在的意义了;如果每个样本的 \xi 非常大,约束条件必然满足,这显然不是我们希望的。加入正则化 C
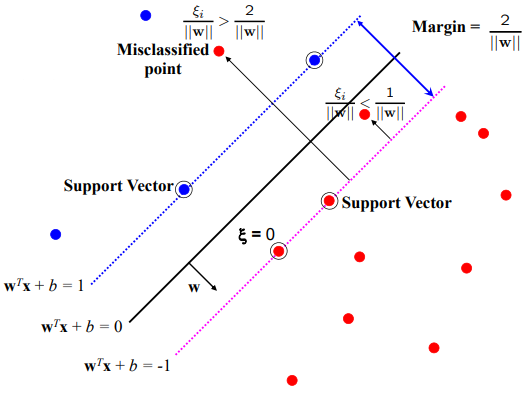
软间隔形式如下:
套用拉格朗日乘数法:
对 \bold w,b,\xi 分别求导后带入上式,见式(8)\frac{\partial L }{\partial \xi} = C-\sum^m_i\alpha_i-\sum^m_i\beta_i=0,由于\beta\geq0,C-\alpha_i\geq0 故 0\leq \alpha_i \leq C。
得到
发现了什么,式(11)和式(9)的目标函数没有变化。
核方法
如何处理线性不可分数据?核方法告诉我们,在低维空间不可分的数据映射到高维空间就可分了。
举个栗子:对二维向量(x_1,x_2),使用多项式核 \phi:R^2 \rightarrow R^3 映射得到
核函数就是在另一个空间进行运算返回点积。引入SVM目标函数
下面就可以用SMO算法求解得到了。
欢迎留言🙃
references:
[1] http://www.robots.ox.ac.uk/~az/lectures/ml/lect2.pdf
[2] https://www.svm-tutorial.com/
[3] http://www.engr.mun.ca/~baxter/Publications/LagrangeForSVMs.pdf
[4] https://blog.csdn.net/v_JULY_v/article/details/7624837。
[5] https://www.cnblogs.com/hello-ai/p/11332654.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架