
初始分词算法
讲个段子
日/ 照香炉/ 生/ 紫烟
日照/ 香炉/ 生/ 紫烟

下面我们一起来学习分词算法吧
中文分词简介
什么是分词
借用百度百科定义:分词就是将连续的字序列按照一定的规范重新组合成词序列的过程
分词算法有哪些
这里按照分词的方法大致分为两类:基于规则的分词和基于统计的分词
- 基于规则的分词
- 前向最大匹配
- 后向最大匹配
- 最少切分(使每一句中切出的词数最小)
- 双向最大匹配
- 基于统计
- 语言模型
- HMM
- CRF
- 深度学习
什么是一个好的分词算法
这就涉及到分词算法的设计原则:
-
颗粒度越大越好
-
切分结果中非词典词越少越好,单字字典词数越少越好
-
总体词数越少越好
基于匹配规则方法
前向最大匹配(forward-max matching)
例子:[日照香炉生紫烟]
词典:["日","日照","香炉","照香炉","生","紫烟"]
假设我们设定词的最大长度为5,下面我们看看怎么进行前向最大匹配
第一轮:
“日照香炉生” ,词典中没有匹配该词的
“日照香炉” ,未匹配
“日照香” ,未匹配
“日照” ,匹配
第二轮:
“香炉生紫烟” ,未匹配
“香炉生紫” ,未匹配
“香炉生” ,未匹配
“香炉” ,匹配
第三轮:
“生紫烟” ,未匹配
“生紫” ,未匹配
“生” ,匹配
第四轮:
“紫烟” ,匹配
最终的分词结果为:日照/ 香炉/ 生紫烟
代码实现:
#前向最大匹配
def forward_max_matching(text,maxlen,vocab):
results = []
while text:
#取最大长度的子串进行匹配
if len(text)<maxlen:
subtext = text
else:
subtext = text[0:maxlen]
while subtext:
if subtext in vocab:
results.append(subtext)
text = text[len(subtext):]
break
else:
subtext = subtext[0:len(subtext)-1]
return results
后向最大匹配(backward-max matching)
例子:[日照香炉生紫烟]
词典:["日","日照","香炉","照香炉","生","紫烟"]
假设我们同样设定词的最大长度为5,下面我们看看怎么进行后向最大匹配
第一轮:
“香炉生紫烟” ,未匹配
“炉生紫烟” ,未匹配
“生紫烟” ,未匹配
“紫烟” ,匹配
第二轮:
“日照香炉生” ,未匹配
“照香炉生” ,未匹配
“香炉生” ,未匹配
“炉生” ,未匹配
“生” ,匹配
第三轮:
“日照香炉” ,未匹配
“照香炉” ,匹配
第四轮:
“日” ,匹配
最终的分词结果为:日/ 照香炉/ 生/ 紫烟
发现两种分词结果不一样!!
代码实现:
#后向最大匹配
def backward_max_matching(text,maxlen,vocab):
results = []
while text:
#取最大长度的子串进行匹配
if len(text)<maxlen:
subtext = text
else:
subtext = text[-maxlen:]
while subtext:
if subtext in vocab:
results.append(subtext)
text = text[:-len(subtext)]
break
else:
subtext = subtext[-(len(subtext)-1):]
return results[::-1]
双向匹配(Bi-direction Matching)
将前向最大匹配算法和后向最大匹配算法进行比较,从而确定正确的分词方法
算法流程:
- 比较正向最大匹配和逆向最大匹配结果
- 如果分词数量结果不同,那么取分词数量较少的那个
- 如果分词数量结果相同
- 分词结果相同,可以返回任何一个
- 分词结果不同,返回单字数比较少的那个
def bidirection_matching(text,maxlen,vocab):
results = []
forward = forward_max_matching(text,maxlen,vocab)
backward = backward_max_matching(text,maxlen,vocab)[::-1]
# 前后向结果词数不同,返回词数小的
if len(forward)!=len(backward):
return forward if len(forward)<len(backward) else backword
else:
#分词词数相同,分词结果相同
if forward == backward:
return forward
else:#分词结果不同,返回单字少的
for_single = [word for word in forward if len(word)==1]
back_single = [word for word in backward if len(word)==1]
if len(for_single) < len(back_single):
return forward
else:
return backward
直观上来看,如何得到一个好的分词结果呢?
输入文本 --> 找到所有可能的分割 --> 选择最好的结果
可以看到在基于规则匹配的方法中,分词的结果都是局部最优解,更重要的是这种分词方法没有考虑句子的语义信息。如何从所有可能的分词结果中选择最好的,这就需要语言模型出场了
基于概率统计
语言模型
语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?
给定句子
概率可以表示为
这里根据马尔可夫假设,可以指定一个词依赖于前面的几个词,这里我们假设每个词的出现都是互相独立的,也就是一元语言模型,所以概率表示为
我们知道一个词相对整个语料库,出现的概率是非常低的,多个小数相乘可能会出现-inf,所以取对数变为相加,将结果最大的作为最好的分词结果。
这里还有一个问题,根据前面说的,生成输入所有的分词结果,这个过程太低效了,我们需要一种方法融合生成分词和计算概率的过程,使用概率图!!
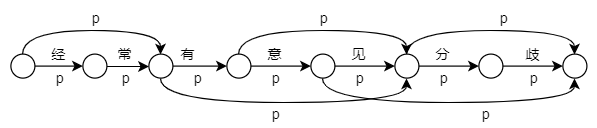
上图是一个简单的示意,每一个线段表示一个字或者词,p表示对应的词在词典库出现的概率。如果使用一元语言模型,我么需要做的就是找到概率乘积最小的那条路径,使用动态规划实现最短路径。
HMM/CRF
使用序列标注方法解决分词,对每一个字标注:
B(开头),M(中间),E(结尾),S(独立成词)四种状态
就学到这里了,实际用的时候需要根据场景做出选择,比如在搜索引擎对大规模网页进行内容解析时,对分词对速度要求大于精度,而在智能问答中由于句子较短,对分词的精度要求大于速度。
references
匹配法. https://blog.csdn.net/selinda001/article/details/79345072

 浙公网安备 33010602011771号
浙公网安备 33010602011771号