
常用模块
匿名函数lambda
for i in map(lambda x:x*2 if x>5 else x-1,[1,2,3,4,5,6,7,8,9]): print(i)
匿名就是没有名字 def func(x,y,z=1): return x+y+z 匿名 lambda x,y,z=1:x+y+z #与函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,除非让其有名字 func=lambda x,y,z=1:x+y+z func(1,2,3) #让其有名字就没有意义 有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能 匿名函数:一次性使用,随时随时定义 应用:max,min,sorted,map,reduce,filter
高阶函数
def add(x,y,z): return y(x) +y(z) print(add(3,-5,abs))
内置函数
内置函数id()可以返回一个对象的身份,返回值为整数。这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以内存地址为准。is运算符用于比较两个对象的身份,等号比较两个对象的值,内置函数type()则返回一个对象的类型


salaries={ 'gx':3000, 'gxx':100000000, 'gxgx':10000, 'gg':2000 } 迭代字典,取得是key,因而比较的是key的最大和最小值 >>> max(salaries) 'yuanhao' >>> min(salaries) 'alex' 可以取values,来比较 >>> max(salaries.values()) >>> min(salaries.values()) 但通常我们都是想取出,工资最高的那个人名,即比较的是salaries的值,得到的是键 >>> max(salaries,key=lambda k:salary[k]) 'gxx' >>> min(salaries,key=lambda k:salary[k]) 'gg' 也可以通过zip的方式实现 salaries_and_names=zip(salaries.values(),salaries.keys()) 先比较值,值相同则比较键 >>> max(salaries_and_names) (100000000, 'gxx') salaries_and_names是迭代器,因而只能访问一次 >>> min(salaries_and_names) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: min() arg is an empty sequence sorted(iterable,key=None,reverse=False)
>>> format('some string','s') 'some string' >>> format('some string') 'some string' #整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None >>> format(3,'b') #转换成二进制 '11' >>> format(97,'c') #转换unicode成字符 'a' >>> format(11,'d') #转换成10进制 '11' >>> format(11,'o') #转换成8进制 '13' >>> format(11,'x') #转换成16进制 小写字母表示 'b' >>> format(11,'X') #转换成16进制 大写字母表示 'B' >>> format(11,'n') #和d一样 '11' >>> format(11) #默认和d一样 '11' #浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None >>> format(314159267,'e') #科学计数法,默认保留6位小数 '3.141593e+08' >>> format(314159267,'0.2e') #科学计数法,指定保留2位小数 '3.14e+08' >>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示 '3.14E+08' >>> format(314159267,'f') #小数点计数法,默认保留6位小数 '314159267.000000' >>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数 '3.141593' >>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数 '3.14159267' >>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数 '3.1415926700' >>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母 'INF' #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数 >>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点 '3e-05' >>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点 '3.1e-05' >>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点 '3.14e-05' >>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写 '3.14E-05' >>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点 '3' >>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点 '3.1' >>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点 '3.14' >>> format(0.00003141566,'.1n') #和g相同 '3e-05' >>> format(0.00003141566,'.3n') #和g相同 '3.14e-05' >>> format(0.00003141566) #和g相同 '3.141566e-05'
time模块
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2017-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
print time.time() print time.mktime(time.localtime()) print time.gmtime() #可加时间戳参数 print time.localtime() #可加时间戳参数 print time.strptime('2017-11-11', '%Y-%m-%d') print time.strftime('%Y-%m-%d') #默认当前时间 print time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间 print time.asctime() #Mon Aug 7 11:17:03 2017 print time.asctime(time.localtime()) print time.ctime(time.time()) import datetime ''' datetime.date:表示日期的类。常用的属性有year, month, day datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond datetime.datetime:表示日期时间 datetime.timedelta:表示时间间隔,即两个时间点之间的长度 timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]]) strftime("%Y-%m-%d") ''' import datetime print datetime.datetime.now() print datetime.datetime.now() - datetime.timedelta(days=5)
random模块
import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
随机验证码 import random checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print checkcode
shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutill 压缩模块(高级的文件,文件夹,压缩包,处理模块)
shutill.copyfileobj (将文件内容拷贝至另一个文件)
shutill.copyfile (拷贝文件)
shutill.copymode (仅拷贝权限,内容。组,用户均不变)
shutill.copystat (仅拷贝状态的信息)
shutill.copy(拷贝文件和权限)
shutill.copy2(拷贝文件和状态信息)
shutill.ignore_patterns
shutill.copytree
(递归的去拷贝文件夹)
shutill.rmtree(递归的去删除文件)
shuitll.move(递归的去移动文件,它类似mv命令,其实就是重命名)
shutill.make_archive(创建解压缩,并返回文件路径)
shutil.copyfileobj(fsrc, fdst[, length])(将文件内容拷贝到另一个文件中)
import shutil shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)(拷贝文件)
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)(仅拷贝权限。内容、组、用户均不变)
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)(仅拷贝状态的信息,包括:mode bits, atime, mtime, flags)
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)(拷贝文件和权限)
import shutil shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)(拷贝文件和状态信息)
import shutil shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None) (递归的去拷贝文件夹)
import shutil shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,
ignore的意思是排除
拷贝软链接 import shutil shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) ''' 通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件 '''
shutil.rmtree(path[, ignore_errors[, onerror]])(递归的去删除文件)
import shutil shutil.rmtree('folder1')
shutil.move(src, dst)(递归的去移动文件,它类似mv命令,其实就是重命名。)
import shutil shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录 import shutil ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') #将 /data下的文件打包放置 /tmp/目录 import shutil ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩解压缩
import zipfile # 压缩 z = zipfile.ZipFile('haha.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('haha.zip', 'r') z.extractall(path='.') z.close()
tarfile压缩解压缩 import tarfile # 压缩 >>> t=tarfile.open('/tmp/egon.tar','w') >>> t.add('/test1/a.py',arcname='a.bak') >>> t.add('/test1/b.py',arcname='b.bak') >>> t.close() # 解压 >>> t=tarfile.open('/tmp/egon.tar','r') >>> t.extractall('/egon') >>> t.close()
json&pickle模块(序列化)
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换
- pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
序列化和反序列化主要用于动态数据存储
pickle.dumps 序列化 内存-->硬盘
pickle.loads 反序列化 硬盘-->内存
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,
在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态 2:跨平台数据交互
如何序列化之json和pickle:
json
json: 用于字符串和python数据类型间进行转换(更适合跨语言,字符串,基本数据类型),
json 的写入是字符串形式用w模式,只支持序列化python的str,int,float,set,list,dict,tuple数据类型,但json可和其他语言序列化
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
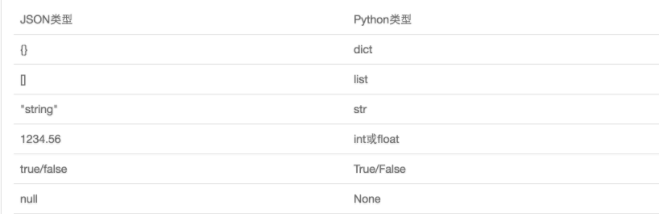
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic) print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes' f.write(j) #-------------------等价于pickle.dump(dic,f) f.close() #-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f)通过loads反序列化时,一定要使用双引号,否则有可能会报错
print(data['age'])
注意:
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))
#conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle
pickle: 用于python特有的类型和python的数据类型间进行转换(更适合所有类型的序列化,仅适用于python)
pickle的写入是二进制形式用wb模式,可以序列化python任何数据类型

import pickle dic={'name':'gongxu','age':23,'sex':'girl'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic) print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes' f.write(j) #-------------------等价于pickle.dump(dic,f) f.close() #-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
如下2个py文件功能是实现数据的动态存档
这个文件的作用,读取内存数据写入到db文件
import pickle #import json as pickle 这是用json执行 注意把wb改成w account={ "id":63232223, "credit":15000, "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf" } f=open("account1.db","wb") f.write(pickle.dumps(account)) #相当于pickle.dump(account,f) f.close()
这个文件的作用,读取db文件写入到内存
import pickle #import json as pickle 这是用json执行 注意把rb改成r f=open("account1.db","rb") account=pickle.loads(f.read())#相当于account=pickle.load(f) print(account) print(account["id"]) #可以加如下,执行后注释 在执行看值是否改变 account["balance"]-=3400 f=open("account1.db","wb") f.write(pickle.dumps(account)) f.close()
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve #内存写入db文件, 字典形式, f=shelve.open(r'sheve.txt') f["student1"]={"name":"egon","age":18,"height":"180cm"} print(f['student1']) f.close() #读取db文件的数据 f=shelve.open(r'sheve.txt') print(f['student1']) print(f['student1']["name"]) f.close()
configparser(configparser用于处理特定格式的文件,其本质上是利用open来操作文件。((把所有类型都当做字符串处理))
getint 转换成整数
getfloat 转换成浮点数
getboolean 转换成布尔值
指定格式 # 注释1 ; 注释2
[section1] # 节点 k1 = v1 # 值 k2:v2 # 值 [section2] # 节点 k1 = v1 # 值
获取所有节点 import configparser
config = configparser.ConfigParser()
config.read('hahaha', encoding='utf-8')
ret = config.sections()
print(ret)
获取指定节点下所有的键值对 import configparser config = configparser.ConfigParser() config.read('hahaha', encoding='utf-8') ret = config.items('section1') print(ret)
获取指定节点下所有的建 import configparser config = configparser.ConfigParser() config.read('hahaha', encoding='utf-8') ret = config.options('section1') print(ret)
获取指定节点下指定key的值 import configparser config = configparser.ConfigParser() config.read('hahaha', encoding='utf-8') v = config.get('section1', 'k1') # v = config.getint('section1', 'k1') # v = config.getfloat('section1', 'k1') # v = config.getboolean('section1', 'k1')(v)
检查、删除、添加节点 import configparser config = configparser.ConfigParser() config.read('hahaha', encoding='utf-8') # 检查 has_sec = config.has_section('section1') print(has_sec) # 添加节点 config.add_section("SEC_1") config.write(open('xxxooo', 'w')) # 删除节点 config.remove_section("SEC_1") config.write(open('xxxooo', 'w'))
检查、删除、设置指定组内的键值对 import configparser config = configparser.ConfigParser() config.read('hahaha', encoding='utf-8') # 检查 has_opt = config.has_option('section1', 'k1') print(has_opt) # 删除 config.remove_option('section1', 'k1') config.write(open('xxxooo', 'w')) # 设置 config.set('section1', 'k10', "123") config.write(open('xxxooo', 'w'))
re模块
python中re模块提供了正则表达式相关操作
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
一:什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式:
最常用的匹配语法
1,re.match 从头开始匹配
(注: re 的 match 与 search 函数同 compile 过的 Pattern 对象的 match 与 search 函数的参数是不一样的。 Pattern 对象的 match 与 search 函数更为强大,是真正最常用的函数)
按照规则在目标字符串中进行匹配。
re.match(pattern, string, flags)
第一个参数是正则表达式,如果匹配成功,则返回一个Match,否则返回一个None;
第二个参数表示要匹配的字符串;
第三个参数是标致位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
函数的返回值为真或者假。
例如:match(‘p’,’Python’)返回值为真;match(‘p’,’www.python.org’)返回值为假。
定义:re.search会在给定字符串中寻找第一个匹配给定正则表达式的子字符串。
函数的返回值:如果查找到则返回查找到的值,否则返回为None。
findall 虽然很直观,但是在进行更复杂的操作时,就有些力不从心了。此时更多的使用的是 match 和 search 函数。他们的参数和 findall 是一样的,都是:
match( rule , targetString [,flag] )
search( rule , targetString [,flag] )
定义:re.search会在给定字符串中寻找第一个匹配给定正则表达式的子字符串。
函数的返回值:如果查找到则返回查找到的值,否则返回为None。
不过它们的返回不是一个简单的字符串列表,而是一个 MatchObject (如果匹配成功的话) . 。通过操作这个 matchObject ,我们可以得到更多的信息。
需要注意的是,如果匹配不成功,它们则返回一个 NoneType 。所以在对匹配完的结果进行操作之前,你必需先判断一下是否匹配成功了,比如:
>>> m=re.match( rule , target ) >>> if m: # 必需先判断是否成功 doSomethin
这两个函数唯一的区别是: match 从字符串的开头开始匹配,如果开头位置没有匹配成功,就算失败了;而 search 会跳过开头,继续向后寻找是否有匹配的字符串。针对不同的需要,可以灵活使用这两个函数。
关于 match 返回的 MatchObject 如果使用的问题,是 Python 正则式的精髓所在,它与组的使用密切相关。我将在下一部分详细讲解,这里只举个最简单的例子:
>>> s= 'Tom:9527 , Sharry:0003' >>> m=re.match( r'(?P<name>/w+):(?P<num>/d+)' , s ) >>> m.group() 'Tom:9527' >>> m.groups() ('Tom', '9527') >>> m.group(‘name’) 'Tom' >>> m.group(‘num’) '9527'
2,re.search 匹配包含
import re print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) #['h1'] print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) #<h1>hello</h1> print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").groupdict()) #<h1>hello</h1> print(re.search(r"<(\w+)>\w+</(\w+)>","<h1>hello</h1>").group()) print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group())
3,re.findall 把所有匹配到的字符放到以列表中的元素返回
import re print(re.findall(r'-?\d+\.?\d*',"1-12*(60+(-40.35/5)-(-4*3))")) #找出所有数字['1', '-12', '60', '-40.35', '5', '-4', '3'] #使用|,先匹配的先生效,|左边是匹配小数,而findall最终结果是查看分组,所有即使匹配成功小数也不会存入结果 #而不是小数时,就去匹配(-?\d+),匹配到的自然就是,非小数的数,在此处即整数 print(re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")) #找出所有整数['1', '-2', '60', '', '5', '-4', '3']
#为何同样的表达式search与findall却有不同结果:
print(re.search('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))").group()) #(-40.35/5) print(re.findall('\(([\+\-\*\/]*\d+\.?\d*)+\)',"1-12*(60+(-40.35/5)-(-4*3))")) #['/5', '*3'] #看这个例子:(\d)+相当于(\d)(\d)(\d)(\d)...,是一系列分组 print(re.search('(\d)+','123').group()) #group的作用是将所有组拼接到一起显示出来 print(re.findall('(\d)+','123')) #findall结果是组内的结果,且是最后一个组的结果
4,re.split 以匹配到的字符当做列表分隔符
切片函数。使用指定的正则规则在目标字符串中查找匹配的字符串,用它们作为分界,把字符串切片。
第一个参数是正则规则,第二个参数是目标字符串,第三个参数是最多切片次数
返回一个被切完的子字符串的列表
这个函数和 str 对象提供的 split 函数很相似。举个例子,我们想把上例中的字符串被 ’,’ 分割开,同时要去掉逗号前后的空格
>>> s=’ I have a dog , you have a dog , he have a dog ‘ >>> re.split( ‘/s*,/s*’ , s ) [' I have a dog', 'you have a dog', 'he have a dog '] 结果很好。如果使用 str 对象的 split 函数,则由于我们不知道 ’,’ 两边会有多少个空格,而不得不对结果再进行一次处理。
5,re.sub 匹配字符并替换
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为 S(DOTALL): 点任意匹配模式,改变'.'的行为
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
字符串的替换和修改
re 模块还提供了对字符串的替换和修改函数,他们比字符串对象提供的函数功能要强大一些。这几个函数是
sub ( rule , replace , target [,count] )
subn(rule , replace , target [,count] )
在目标字符串中规格规则查找匹配的字符串,再把它们替换成指定的字符串。你可以指定一个最多替换次数,否则将替换所有的匹配到的字符串。
第一个参数是正则规则,第二个参数是指定的用来替换的字符串,第三个参数是目标字符串,第四个参数是最多替换次数。
这两个函数的唯一区别是返回值。
sub 返回一个被替换的字符串
sub 返回一个元组,第一个元素是被替换的字符串,第二个元素是一个数字,表明产生了多少次替换。
例,将下面字符串中的 ’dog’ 全部替换成 ’cat’
>>> s=’ I have a dog , you have a dog , he have a dog ‘ >>> re.sub( r’dog’ , ‘cat’ , s ) ' I have a cat , you have a cat , he have a cat ' 如果我们只想替换前面两个,则 >>> re.sub( r’dog’ , ‘cat’ , s , 2 ) ' I have a cat , you have a cat , he have a dog ' 或者我们想知道发生了多少次替换,则可以使用 subn >>> re.subn( r’dog’ , ‘cat’ , s ) (' I have a cat , you have a cat , he have a cat ', 3)
二:常用匹配模式(元字符)
http://blog.csdn.net/yufenghyc/article/details/51078107
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字 |
| \W | 匹配非字母数字 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
# =================================匹配模式================================= #一对一的匹配 # 'hello'.replace(old,new) # 'hello'.find('pattern') #正则匹配 import re #\w与\W print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] print(re.findall('\W','hello egon 123')) #[' ', ' '] #\s与\S print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' '] print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] #\n \t都是空,都可以被\s匹配 print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' '] #\n与\t print(re.findall(r'\n','hello egon \n123')) #['\n'] print(re.findall(r'\t','hello egon\t123')) #['\n'] #\d与\D print(re.findall('\d','hello egon 123')) #['1', '2', '3'] print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' '] #\A与\Z print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^ print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$ #^与$ print(re.findall('^h','hello egon 123')) #['h'] print(re.findall('3$','hello egon 123')) #['3'] # 重复匹配:| . | * | ? | .* | .*? | + | {n,m} | #. print(re.findall('a.b','a1b')) #['a1b'] print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab'] print(re.findall('a.b','a\nb')) #[] print(re.findall('a.b','a\nb',re.S)) #['a\nb'] print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一条意思一样 #* print(re.findall('ab*','bbbbbbb')) #[] print(re.findall('ab*','a')) #['a'] print(re.findall('ab*','abbbb')) #['abbbb'] #? print(re.findall('ab?','a')) #['a'] print(re.findall('ab?','abbb')) #['ab'] #匹配所有包含小数在内的数字 print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3'] #.*默认为贪婪匹配 print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b'] #.*?为非贪婪匹配:推荐使用 print(re.findall('a.*?b','a1b22222222b')) #['a1b'] #+ print(re.findall('ab+','a')) #[] print(re.findall('ab+','abbb')) #['abbb'] #{n,m} print(re.findall('ab{2}','abbb')) #['abb'] print(re.findall('ab{2,4}','abbb')) #['abb'] print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+' print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*' #[] print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b'] print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b'] print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #[]内的^代表的意思是取反,所以结果为['a=b'] print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #[]内的^代表的意思是取反,所以结果为['a=b'] #\# print(re.findall('a\\c','a\c')) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义 print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c'] #():分组 print(re.findall('ab+','ababab123')) #['ab', 'ab', 'ab'] print(re.findall('(ab)+123','ababab123')) #['ab'],匹配到末尾的ab123中的ab print(re.findall('(?:ab)+123','ababab123')) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容 #| print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
# ===========================re模块提供的方法介绍=========================== import re #1 print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里 #2 print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match #4 print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 #5 print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有 print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数 #6 obj=re.compile('\d{2}') print(obj.search('abc123eeee').group()) #12 print(obj.findall('abc123eeee')) #['12'],重用了obj
#在线调试工具:tool.oschina.net/regex/# import re s=''' http://www.baidu.com 1011010101 egon@oldboyedu.com 你好 21213 010-3141 ''' #最常规匹配 # content='Hello 123 456 World_This is a Regex Demo' # res=re.match('Hello\s\d\d\d\s\d{3}\s\w{10}.*Demo',content) # print(res) # print(res.group()) # print(res.span()) #泛匹配 # content='Hello 123 456 World_This is a Regex Demo' # res=re.match('^Hello.*Demo',content) # print(res.group()) #匹配目标,获得指定数据 # content='Hello 123 456 World_This is a Regex Demo' # res=re.match('^Hello\s(\d+)\s(\d+)\s.*Demo',content) # print(res.group()) #取所有匹配的内容 # print(res.group(1)) #取匹配的第一个括号内的内容 # print(res.group(2)) #去陪陪的第二个括号内的内容 #贪婪匹配:.*代表匹配尽可能多的字符 # import re # content='Hello 123 456 World_This is a Regex Demo' # # res=re.match('^He.*(\d+).*Demo$',content) # print(res.group(1)) #只打印6,因为.*会尽可能多的匹配,然后后面跟至少一个数字 #非贪婪匹配:?匹配尽可能少的字符 # import re # content='Hello 123 456 World_This is a Regex Demo' # # res=re.match('^He.*?(\d+).*Demo$',content) # print(res.group(1)) #只打印6,因为.*会尽可能多的匹配,然后后面跟至少一个数字 #匹配模式:.不能匹配换行符 content='''Hello 123456 World_This is a Regex Demo ''' # res=re.match('He.*?(\d+).*?Demo$',content) # print(res) #输出None # res=re.match('He.*?(\d+).*?Demo$',content,re.S) #re.S让.可以匹配换行符 # print(res) # print(res.group(1)) #转义:\ # content='price is $5.00' # res=re.match('price is $5.00',content) # print(res) # # res=re.match('price is \$5\.00',content) # print(res) #总结:尽量精简,详细的如下 # 尽量使用泛匹配模式.* # 尽量使用非贪婪模式:.*? # 使用括号得到匹配目标:用group(n)去取得结果 # 有换行符就用re.S:修改模式 #re.search:会扫描整个字符串,不会从头开始,找到第一个匹配的结果就会返回 # import re # content='Extra strings Hello 123 456 World_This is a Regex Demo Extra strings' # # res=re.match('Hello.*?(\d+).*?Demo',content) # print(res) #输出结果为None # # import re # content='Extra strings Hello 123 456 World_This is a Regex Demo Extra strings' # # res=re.search('Hello.*?(\d+).*?Demo',content) # # print(res.group(1)) #输出结果为 #re.search:只要一个结果,匹配演练, import re content=''' <tbody> <tr id="4766303201494371851675" class="even "><td><div class="hd"><span class="num">1</span><div class="rk "><span class="u-icn u-icn-75"></span></div></div></td><td class="rank"><div class="f-cb"><div class="tt"><a href="/song?id=476630320"><img class="rpic" src="http://p1.music.126.net/Wl7T1LBRhZFg0O26nnR2iQ==/19217264230385030.jpg?param=50y50&quality=100"></a><span data-res-id="476630320" " # res=re.search('<a\shref=.*?<b\stitle="(.*?)".*?b>',content) # print(res.group(1)) #re.findall:找到符合条件的所有结果 # res=re.findall('<a\shref=.*?<b\stitle="(.*?)".*?b>',content) # for i in res: # print(i) #re.sub:字符串替换 import re content='Extra strings Hello 123 456 World_This is a Regex Demo Extra strings' # content=re.sub('\d+','',content) # print(content) #用\1取得第一个括号的内容 #用法:将123与456换位置 # import re # content='Extra strings Hello 123 456 World_This is a Regex Demo Extra strings' # # # content=re.sub('(Extra.*?)(\d+)(\s)(\d+)(.*?strings)',r'\1\4\3\2\5',content) # content=re.sub('(\d+)(\s)(\d+)',r'\3\2\1',content) # print(content) # import re # content='Extra strings Hello 123 456 World_This is a Regex Demo Extra strings' # # res=re.search('Extra.*?(\d+).*strings',content) # print(res.group(1)) # import requests,re # respone=requests.get('https://book.douban.com/').text # print(respone) # print('======'*1000) # print('======'*1000) # print('======'*1000) # print('======'*1000) # res=re.findall('<li.*?cover.*?href="(.*?)".*?title="(.*?)">.*?more-meta.*?author">(.*?)</span.*?year">(.*?)</span.*?publisher">(.*?)</span.*?</li>',respone,re.S) # # res=re.findall('<li.*?cover.*?href="(.*?)".*?more-meta.*?author">(.*?)</span.*?year">(.*?)</span.*?publisher">(.*?)</span>.*?</li>',respone,re.S) # # # for i in res: # print('%s %s %s %s' %(i[0].strip(),i[1].strip(),i[2].strip(),i[3].strip()))
hashlib模块
hashlib加密模块(用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法,md5是不可逆的)
import hashlib # ######## md5 ######## hash = hashlib.md5() # help(hash.update) hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) print(hash.digest()) ######## sha1 ######## hash = hashlib.sha1() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest())
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # ######## md5 ######## hash = hashlib.md5(bytes('898oaFs09f',encoding="utf-8")) hash.update(bytes('admin',encoding="utf-8")) print(hash.hexdigest())
python内置还有一个 hmac 模块,它内部对我们创建 key 和 内容 进行进一步的处理然后再加密
import hmac h = hmac.new(bytes('898oaFs09f',encoding="utf-8")) h.update(bytes('admin',encoding="utf-8")) print(h.hexdigest())
xml模块
xml 是实现不同语言或程序之间进行数据交换的协议(xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。)
浏览器返回的字符串
1,html
2,json
3, xml
页面上做展示(字符串类型一个xml格式文件)
配置文件(文件,内部数据xml格式)
tag 获取当前节点的标签名
attrib 或许当前节点的属性
text 获取当前节点的属性
getchlldren 获取所有的子节点(已经废弃)
find 获取第一个寻找到的子节点
findtext 获取第一个寻找到的子节点的内容
findall 获取所有的子节点
iterfind 获取所有指定的节点,并创建一个迭代器(可以被for循环)
每一个节点都是Element对象,
xml的格式如下,通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
导入xml模块
from xml.etree import ElementTree as ET etree=ET.parse('wenjian.xml')
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print('========>',child.tag,child.attrib,child.attrib['name']) for i in child: print(i.tag,i.attrib,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year=int(node.text)+1 node.text=str(new_year) node.set('updated','yes') node.set('version','1.0') tree.write('test.xml') #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
#在country内添加(append)节点year2 import xml.etree.ElementTree as ET tree = ET.parse("a.xml") root=tree.getroot() for country in root.findall('country'): for year in country.findall('year'): if int(year.text) > 2000: year2=ET.Element('year2') year2.text='新年' year2.attrib={'update':'yes'} country.append(year2) #往country节点下添加子节点 tree.write('a.xml.swap')
自己创建xml文档
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式
系统命令
可以执行shell命令的相关模块和函数有:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
import commands result = commands.getoutput('cmd') result = commands.getstatus('cmd') result = commands.getstatusoutput('cmd')
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。
call(执行命令,返回状态码)
ret = subprocess.call(["ls", "-l"], shell=False) ret = subprocess.call("ls -l", shell=True)
check_call(执行命令,如果执行状态码是 0 ,则返回0,否则抛异常)
subprocess.check_call(["ls", "-l"]) subprocess.check_call("exit 1", shell=True)
check_output(执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常)
subprocess.check_output(["echo", "Hello World!"]) subprocess.check_output("exit 1", shell=True)
subprocess.Popen(...)
用于执行复杂的系统命令
参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
执行普通命令
import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) ret2 = subprocess.Popen("mkdir t2", shell=True)
终端输入的命令分为两种:
输入即可得到输出,如:ifconfig
输入进行某环境,依赖再输入,如:python
import subprocess obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") obj.stdin.close() cmd_out = obj.stdout.read() obj.stdout.close() cmd_error = obj.stderr.read() obj.stderr.close() print(cmd_out) print(cmd_error)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") out_error_list = obj.communicate() print(out_error_list)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) out_error_list = obj.communicate('print("hello")') print(out_error_list)
shell=false的时候是传列表
import subprocess
ret=subprocess.call(["ls","-1"],shell=False)
shell=true的时候是传字符串
ret=subprocess.call(["ls","-1"],shell=True)
