
对sppnet网络的理解
前言:
接着上一篇文章提到的RCNN网络物体检测,这个网络成功的引入了CNN卷积网络来进行特征提取,但是存在一个问题,就是对需要进行特征提取图片大小有严格的限制。当时面对这种问题,rg大神采用的是对分割出的2000多个候选区域,进行切割或者缩放形变处理到固定大小,这样虽然满足了CNN对图片大小的要求,确造成图片的信息缺失或者变形,会降低图片识别的正确率. 如下图所示:
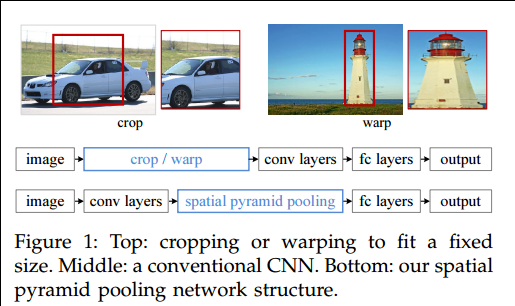
正文:
何凯明大神在看到RCNN模型,分析了CNN模型的特点后:由卷积部分和全连接两部分构成,而对于卷积部分而言,比如任意图片大小(w,h),任意的卷积核size(a,b),默认步长为1,我们都会得到卷积之后的特征图F(w-a+1,h-b+1),所以这部分对图片大小没有要求,有要求的地方在全连接层(如下图),全连接层的神经元设定之后是固定的(如图 Input layer 神经元个数),而每一个都对应者一个特征,rg大神在进入CNN前对图片进行warp处理,就是为了卷积之后的特征数,能够和了全连接层的神经元个数相等.

但是何大神觉得,事情还可以更有趣,他提出将特征数据(特征图)进一步处理,然后拼凑成和神经元个数相同的特征数,这样就可以不用warp图片大小也可以获得相同数量的特征,那么他是咋样处理这特征图的呢?
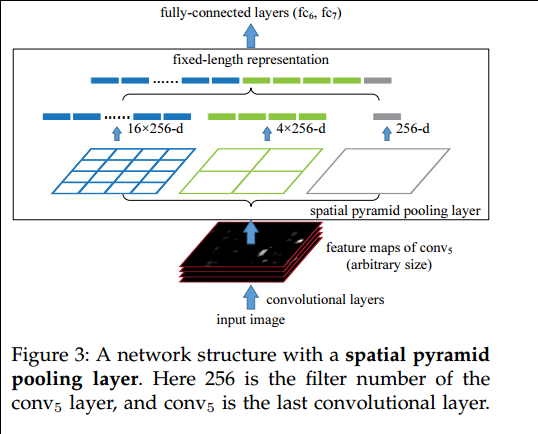
论文中提到,比如我们有一张图片为例子:

我们对这种图进行卷积处理(我们以zf为例,最后一个卷积之后得到这样的特征图)

这张图显示的是一个60*40*256的特征图,到这儿之后,如果要得到固定的神经元个数,论文中提到的是21,我们就需要将60*40的特征图,我们暂且称这个特征图为feature A,进行处理,怎么处理呢?
我们先贴个图:
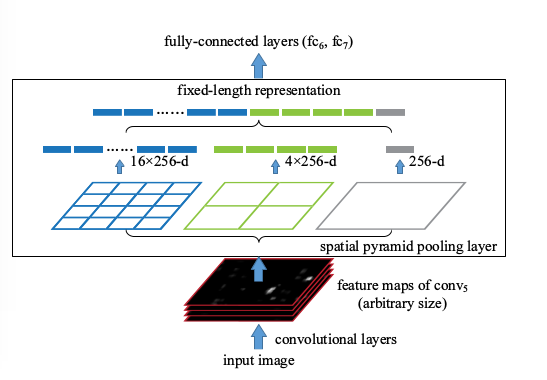
如上图所示:
我们使用三层的金字塔池化层pooling,分别设置图片切分成多少块,论文中设置的分别是(1,4,16),然后按照层次对这个特征图feature A进行分别
处理(用代码实现就是for(1,2,3层)),也就是在第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,
得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征,
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征.
然后将这1+4+16=21个特征输入到全连接层,进行权重计算. 当然了,这个层数是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可
这就是sppnet的核心思想,当然在这个模型中,何大神还对RCNN进行了优化,上面介绍的金字塔池化代替warp最重要的一个,但是这个也很重要,是什么呢?
何大神觉得,如果对ss提供的2000多个候选区域都逐一进行卷积处理,势必会耗费大量的时间,所以他觉得,能不能我们先对一整张图进行卷积得到特征图,然后
再将ss算法提供的2000多个候选区域的位置记录下来,通过比例映射到整张图的feature map上提取出候选区域的特征图B,然后将B送入到金字塔池化层中,进行权重计算.
然后经过尝试,这种方法是可行的,于是在RCNN基础上,进行了这两个优化得到了这个新的网络sppnet.
值得一提的是,sppnet提出的这种金字塔池化来实现任意图片大小进行CNN处理的这种思路,得到了大家的广泛认可,以后的许多模型,或多或少在这方面都是参考了这种思路,就连
rg大神,在后来提出的fast-rcnn上也是收益于这种思想的启发.
参考:
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
