
词向量可视化--[tensorflow , python]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
----------------------------------
Version : ??
File Name : visual_vec.py
Description :
Author : xijun1
Email :
Date : 2018/12/25
-----------------------------------
Change Activiy : 2018/12/25
-----------------------------------
"""
__author__ = 'xijun1'
from tqdm import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
import os
import codecs
words, embeddings = [], []
log_path = 'model'
with codecs.open('/Users/xxx/github/python_demo/vec.txt', 'r') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
for line in tqdm(range(vocab_size)):
word_list = f.readline().split(' ')
word = word_list[0]
vector = word_list[1:-1]
if word == "":
continue
words.append(word)
embeddings.append(np.array(vector))
assert len(words) == len(embeddings)
print(len(words))
with tf.Session() as sess:
X = tf.Variable([0.0], name='embedding')
place = tf.placeholder(tf.float32, shape=[len(words), vector_size])
set_x = tf.assign(X, place, validate_shape=False)
sess.run(tf.global_variables_initializer())
sess.run(set_x, feed_dict={place: embeddings})
with codecs.open(log_path + '/metadata.tsv', 'w') as f:
for word in tqdm(words):
f.write(word + '\n')
# with summary
summary_writer = tf.summary.FileWriter(log_path, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
embedding_conf.tensor_name = 'embedding:0'
embedding_conf.metadata_path = os.path.join('metadata.tsv')
projector.visualize_embeddings(summary_writer, config)
# save
saver = tf.train.Saver()
saver.save(sess, os.path.join(log_path, "model.ckpt"))
结果:
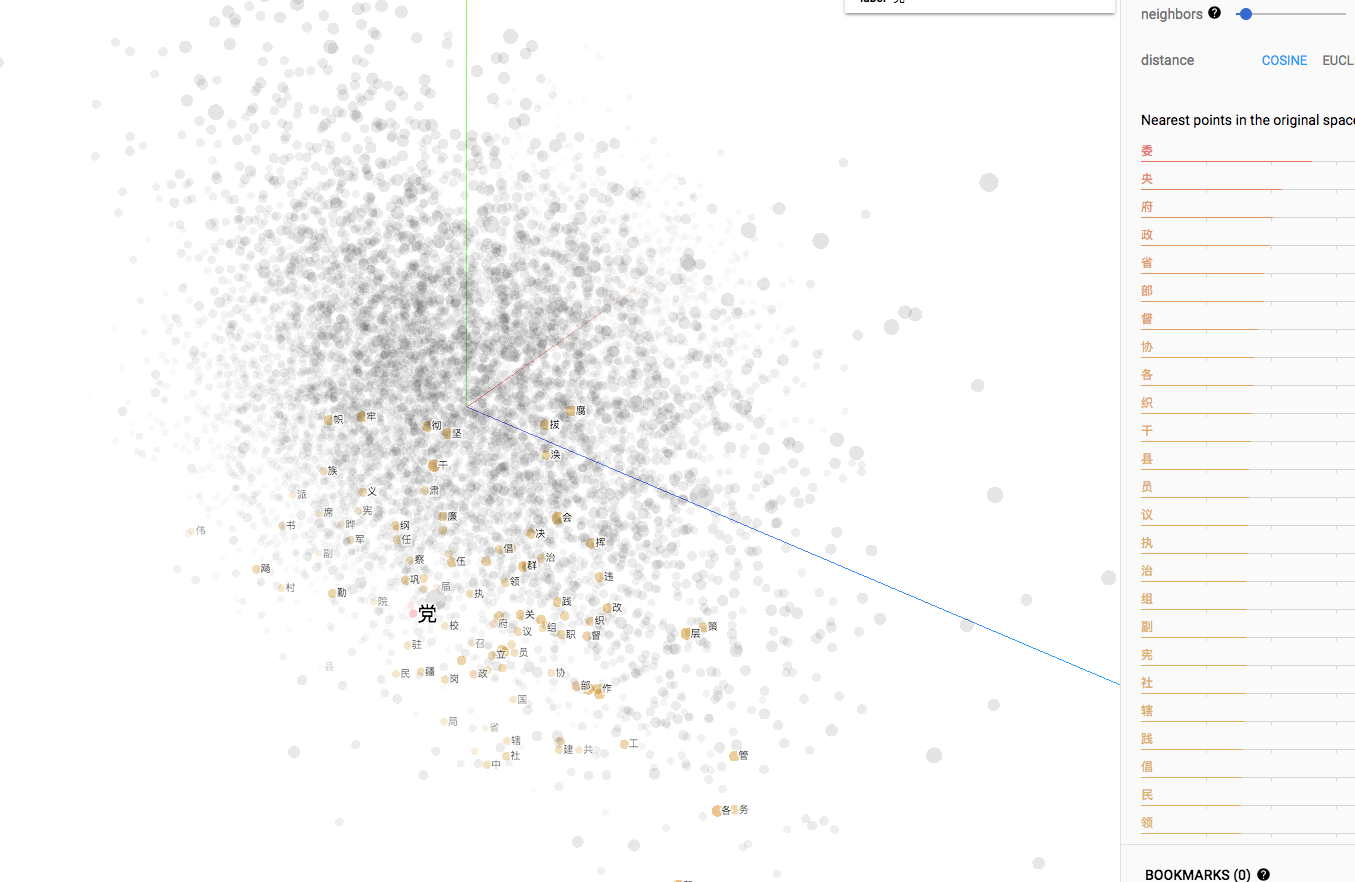
编程是一种快乐,享受代码带给我的乐趣!!!
分类:
tensorflow



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2017-12-25 makefile在编译的过程中出现“except class name”