
并行排序ShearSort ---[MPI , c++]
思想:
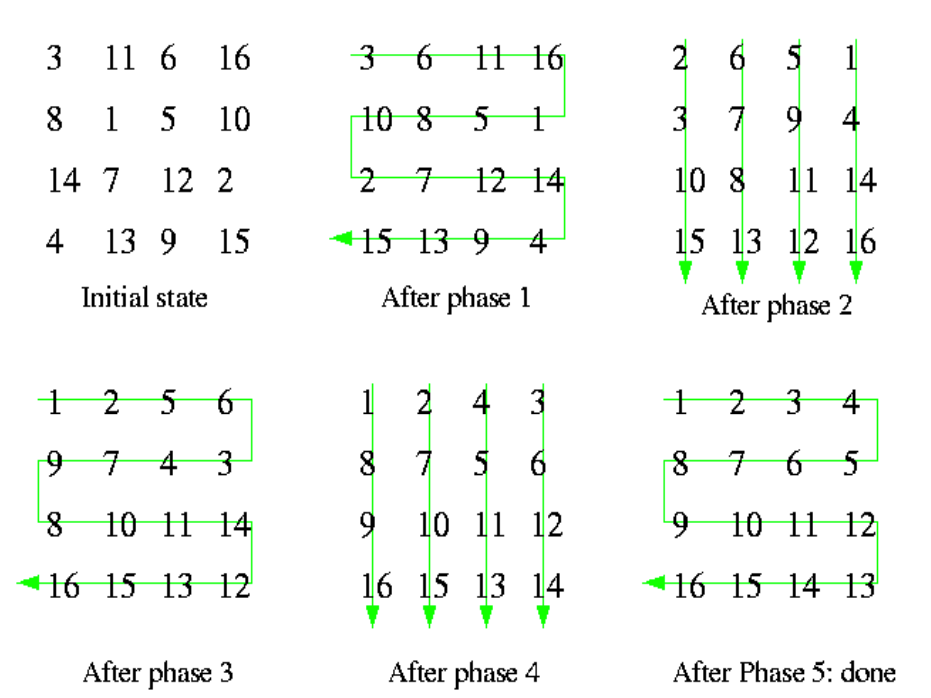
(1) 对于一个nxm的数组,使用N个work进行处理.
(2) 先按行对数组进行升序和降序排序【由左至右】,一般奇数序列work升序,偶数序号的work进行降序
(3)再按列对数组进行升序排序【由上至下】
(4)当数据不再发生变化时,终止退出.
/*
----------------------------------
Version : ??
File Name : ShearSort.py
Description :
Author : xijun1
Email : xijun1@staff.weibo.com
Date : 2018/12/18
-----------------------------------
Change Activity : 2018/12/18
-----------------------------------
__author__ = 'xijun1'
*/
#include "mpi.h"
#include <algorithm>
#include <iostream>
#include <vector>
#include <cassert>
using std::cin;
using std::cout;
using std::endl;
using std::vector;
//归并排序
bool Less(int a, int b){
return a <b;
}
bool Greater(int a, int b){
return a > b;
}
//升序
bool Merge(int *A ,int ps ,int mid , int len , bool( * Comp)(int a , int b) ){
int i=ps,j=mid,cnt=0;
int C[len-ps+1];
bool is_change = false;
while(i<mid&&j<len ){
if(Comp(A[i] , A[j])) {
C[cnt++] = A[j++];
is_change= true;
}
else C[cnt++]=A[i++];
}
while(i<mid) C[cnt++]=A[i++];
while(j<len) C[cnt++]=A[j++];
for(i=ps; i<len ;i++)
A[i]=C[i-ps];
return is_change;
}
//非递归版
bool Msort_(int *arg , int ps , int len , bool( * Comp)(int a , int b) ){
int s,t=1;
bool is_change = false;
while(ps+t<=len){
s=t;
t=2*s;
int pos=ps;
while(pos+t<=len){
is_change |= Merge(arg,pos,pos+s,pos+t , Comp);
pos+=t; //移动
}
if(pos+s<len)
is_change |= Merge(arg,pos,pos+s,len , Comp);
}
if(ps+s<len)
is_change |= Merge(arg,ps,ps+s,len , Comp);
return is_change;
}
int main( int argc , char * argv []){
int process_id , num_process;
MPI_Init( & argc , &argv);
//make process_id = 0 to master; other slaves
MPI_Comm_size( MPI_COMM_WORLD , &num_process);
MPI_Comm_rank( MPI_COMM_WORLD , &process_id);
assert( num_process == 4 );
int recv_buf [4];
int brr[16];
unsigned int part_size=(sizeof(recv_buf)/sizeof(recv_buf[0]));
//init
if( 0 == process_id ){
int arr[] = {3,11,6,16, 8,1,5,10,
14,7,12,2, 4,13,9,15};
int len =sizeof(arr)/ sizeof(arr[0]);
memcpy( brr , arr , len* sizeof(arr[0]));
}else{
int len =sizeof(brr)/ sizeof(brr[0]);
memset(brr,0, len* sizeof(brr[0]));
}
int epoch=0;
while( epoch < 5 ){
if( 0 == process_id){
//div part len( brr )/ num_process
part_size = (sizeof(brr)/sizeof(brr[0]))/num_process;
//send
for (int i = 0; i < num_process; ++i) {
MPI_Send(&brr[i*part_size] ,part_size ,MPI_INT ,i,i,MPI_COMM_WORLD);
}
}
{
//work calc
MPI_Recv(&recv_buf ,part_size,MPI_INT ,0 ,process_id,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
if( epoch&1 ){
Msort_(recv_buf, 0, sizeof(recv_buf) / sizeof(recv_buf[0]),Greater);
}else{
if (process_id & 1) {
Msort_(recv_buf, 0, sizeof(recv_buf) / sizeof(recv_buf[0]), Less);
} else {
Msort_(recv_buf, 0, sizeof(recv_buf) / sizeof(recv_buf[0]), Greater);
}
}
MPI_Send(&recv_buf ,part_size ,MPI_INT ,0,process_id,MPI_COMM_WORLD);
}
//recv
if(0 == process_id) {
std::cout << "start epoch: " << epoch << std::endl;
//recv
for (int i = 0; i < num_process; ++i) {
MPI_Recv(&brr[i * part_size], part_size, MPI_INT, i, i, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
for (int j = 0; j < 4; ++j) {
std::cout << " " << brr[i * part_size + j];
}
std::cout << std::endl;
}
//check 数组是否需要停止
//调整数组
if( epoch+1<5 ) {
for (int i = 0; i < 4; ++i) {
for (int j = i; j < 4; ++j) {
int tmp = brr[(i * part_size) + j];
brr[(i * part_size) + j] = brr[(j * part_size) + i];
brr[(j * part_size) + i] = tmp;
}
}
}
}
epoch++;
}
if(0 == process_id) {
std::cout<<"---------------------------"<<std::endl;
for (int j = 0; j < 4; ++j) {
for (int i = 0; i < 4; ++i) {
std::cout << brr[j*4 + i] << " ";
}
std::cout << std::endl;
}
}
MPI_Finalize();
return 0;
}
//
结果:
demo_mpi mpirun --mca btl_vader_backing_directory /tmp --oversubscribe -np 4 shear_sort
start epoch: 0
3 6 11 16
10 8 5 1
2 7 12 14
15 13 9 4
start epoch: 1
2 3 10 15
6 7 8 13
5 9 11 12
1 4 14 16
start epoch: 2
1 2 5 6
9 7 4 3
8 10 11 14
16 15 13 12
start epoch: 3
1 8 9 16
2 7 10 15
4 5 11 13
3 6 12 14
start epoch: 4
1 2 3 4
8 7 6 5
9 10 11 12
16 15 14 13
---------------------------
1 2 3 4
8 7 6 5
9 10 11 12
16 15 14 13
编程是一种快乐,享受代码带给我的乐趣!!!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2014-12-18 hdu 2818 Building Block
2013-12-18 HDUOJ---------2255奔小康赚大钱
2013-12-18 HDUOJ------1711Number Sequence
2013-12-18 HDUOJ---1712 ACboy needs your help