


floor报错注入浅析
常见报错语句:
select count(*),(floor(rand(0)*2)) x from information_schema.tables group by x;
1.通过concat函数连接注入语句与floor(rand(0)*2)函数,实现将注入结果与报错信息回显的注入方式。
1.1 floor()函数
floor函数的作用就是返回小于等于括号内该值的最大整数。
1.2 rand()函数
rand()可以产生一个在0和1之间的随机数
直接使用rand函数每次产生的数值不一样,但当我们提供了一个固定的随机数的种子0(官方的单词是seed)之后,每次产生的值都是相同的,这也可以称之为伪随机。
floor(rand(0)*2)就是对rand(0)产生的随机序列乘2后的结果,再进行取整。配合上floor函数就可以产生确定的两个数,即0和1,得到伪随机序列为如下图所示:
1.3 group by 与 count(*)
group by 主要用来对数据进行分组(相同的分为一组),这里与count() 结合使用的作用就能看得出来。
表中只有一条记录时,多次使用报错语句并不会报错。
表中只有两条记录时,多次使用报错语句也不会报错
表中有三条记录时,执行语句一定会报错
由此可见**floor(rand(0)_2)_报错是有条件的,记录必须是三条以上
看看rand(0)和rand(1)是否有决定因素,由上面函数介绍已经知道rand(0)和rand()的区别
一条记录的时候多次执行不报错
2条记录的时候出现了偶尔报错
三条记录的时候偶尔报错
试试添加多条记录,rand(0)与rand()的区别
可以看到floor(rand(0)_2)一定会报错,floor(rand()_2)的结果是随机的
看看官方mysql5.7版本的语法文档介绍
If an integer argument N is specified, it is used as the seed value:
With a constant initializer argument, the seed is initialized once when the statement is prepared, prior to execution.
With a nonconstant initializer argument (such as a column name), the seed is initialized with the value for each invocation of RAND().
如果指定了整数参数N,则将其用作种子值:
使用常量初始化器参数,种子在语句准备好时初始化一次,然后再执行。
使用非常量初始值设定项参数(例如列名),种子使用每次调用的值进行初始化 RAND()。
Use of a column with RAND() values in an ORDER BY or GROUP BY clause may yield unexpected results because for either clause a RAND() expression can be evaluated multiple times for the same row, each time returning a different result.
在ORDER BY或GROUP BY子句中使用带有RAND()值的列可能会产生意想不到的结果,因为对于这两个子句,同一行RAND()表达式可以被求多次值,每次都返回不同的结果。
问题就出在可能会产生意想不到的结果
select name,count(*) from cunmin group by name;
浅析下该语句的执行过程。
select count() from cunmin group by floor(rand(0)2); (记录必须是三条以上)
1、查询前默认会建立如下空虚拟表
| key | count(*) |
2、查询第一条记录,执行floor(rand(0)2),发现结果为0(第一次计算),查询虚拟表,发现0的键值不存在,则floor(rand(0)2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,结果如下:
| key | count(*) |
| 1(第一次计算结果) | 1 |
3、查询第二条记录,再次计算floor(rand(0)2),发现结果为1(第三次计算),查询虚表,发现1的键值存在,所以floor(rand(0)2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕,结果如下:
| key | count(*) |
| 1(第一次计算结果) | 2 |
4、查询第三条记录,再次计算floor(rand(0)2),发现结果为0(第4次计算),查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)2)被再次计算,作为虚表的主键,其值为1(第5次计算),然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了。
理解上面1、2、3、4这四段话看着上面标红色的图更容易理解。
5、整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要3条数据,使用该语句才会报错的原因。
补充:
1. group by 分组查询流程
下面的流程步骤未必正确,只是帮助更深入理解 group by 分组
1.1. 生成虚拟表
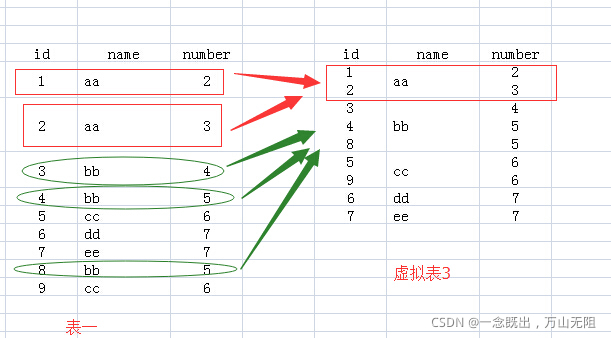
FROM user_info:该句执行后,结果就是原来的表(原数据表)
FROM user_info GROUP BY name:该句执行后,我们 想象 生成了虚拟表 3,如下所图所示
生成过程是这样的:group by name,那么找 name 那一列,具有相同 name 值的行,合并成一行,如对于 name 值为 aa 的,那么 <1 aa 2> 与 <2 aa 3> 两行合并成 1 行,所有的 id 值和 number 值写到一个单元格里面
1.2. 执行相关查询
接下来就要针对虚拟表 3 执行 select 了
如果执行 select * 的话,那么返回的结果应该是虚拟表 3,可是 id 和 number 中有的单元格里面的内容是有多个值的,而关系型数据库就是基于关系的,单元格中是不允许有多个值的。所以执行 SELECT * FROM user_info GROUP BY name; 时语句就报错了
我们再看 name 列,每个单元格只有一个数据,所以我们 select name 的话,就没有问题了。为什么 name 列每个单元格只有一个值呢,因为我们就是用 name 列来 group by 的
那么对于 id 和 number 里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如 COUNT(id),SUM(number),而每个聚合函数的输入就是每一个多数据的单元格
如我们执行
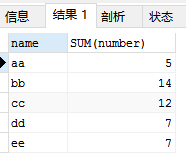
SELECT `name`,SUM(number) FROM user_info GROUP BY `name`;
那么 SUM 就对虚拟表 3 的 number 列的每个单元格进行 SUM 操作,如对 name 为 aa 的那一行的 number 列执行 SUM 操作,即 2 + 3 = 5。最后执行结果如下
group by 多个字段该怎么理解呢?如 group by name, number,我们可以把 name 和 number 看成一个整体字段,以他们整体来进行分组的。如下图

接下来就可以配合 select 和聚合函数进行操作了。如执行
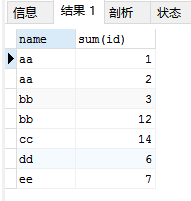
SELECT `name`, sum(id) FROM user_info GROUP BY `name`, number;
结果如下图
本文来自博客园,作者:易先讯,转载请注明原文链接:https://www.cnblogs.com/gongxianjin/p/17133262.html

