

Go常见面试题【由浅入深】2022版
Go语言相比C++/Java等语言是优雅且简洁的,是笔者最喜爱的编程语言之一,它既保留了C++的高性能,又可以像Java,Python优雅的调用三方库和管理项目,同时还有接口,自动垃圾回收和goroutine等让人拍案叫绝的设计。
有许多基于Go的优秀项目。Docker,Kubernetes,etcd,deis,flynn,lime,revel等等。Go无疑是云时代的最好语言!
题外话到此为止,在面试中,我们需要深入了解Go语言特性,并适当辅以源码阅读(Go源码非常人性化,注释非常详细,基本上只要你学过Go就能看懂)来提升能力。常考的点包括:切片,通道,异常处理,Goroutine,GMP模型,字符串高效拼接,指针,反射,接口,sync,go test和相关工具链。
一切问题的最权威的回答一定来自官方,这里力荐golang官方FAQ,虽然是英文的,但是也希望你花3-4天看完。从使用者的角度去提问题, 从设计者的角度回答问题。

面试题都是来源于网上和自己平时遇到的,但是很少有解答的版本,所以我专门回答了一下,放在专栏。
欢迎关注公众号“迹寒编程”,回复“go面试题”,获取本文章的pdf版本。
【所有试题已注明来源,侵删】
面试题1
来源:geektutu
基础语法
01 = 和 := 的区别?
=是赋值变量,:=是定义变量。
02 指针的作用
一个指针可以指向任意变量的地址,它所指向的地址在32位或64位机器上分别固定占4或8个字节。指针的作用有:
- 获取变量的值
import fmt
func main(){
a := 1
p := &a//取址&
fmt.Printf("%d\n", *p);//取值*
}- 改变变量的值
// 交换函数
func swap(a, b *int) {
*a, *b = *b, *a
}- 用指针替代值传入函数,比如类的接收器就是这样的。
type A struct{}
func (a *A) fun(){}
03 Go 允许多个返回值吗?
可以。通常函数除了一般返回值还会返回一个error。
04 Go 有异常类型吗?
有。Go用error类型代替try...catch语句,这样可以节省资源。同时增加代码可读性:
_, err := funcDemo()
if err != nil {
fmt.Println(err)
return
}也可以用errors.New()来定义自己的异常。errors.Error()会返回异常的字符串表示。只要实现error接口就可以定义自己的异常,
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
// 多一个函数当作构造函数
func New(text string) error {
return &errorString{text}
}
05 什么是协程(Goroutine)
协程是用户态轻量级线程,它是线程调度的基本单位。通常在函数前加上go关键字就能实现并发。一个Goroutine会以一个很小的栈启动2KB或4KB,当遇到栈空间不足时,栈会自动伸缩, 因此可以轻易实现成千上万个goroutine同时启动。
06 ❤ 如何高效地拼接字符串
拼接字符串的方式有:+ , fmt.Sprintf , strings.Builder, bytes.Buffer, strings.Join
1 "+"
使用+操作符进行拼接时,会对字符串进行遍历,计算并开辟一个新的空间来存储原来的两个字符串。
2 fmt.Sprintf
由于采用了接口参数,必须要用反射获取值,因此有性能损耗。
3 strings.Builder:
用WriteString()进行拼接,内部实现是指针+切片,同时String()返回拼接后的字符串,它是直接把[]byte转换为string,从而避免变量拷贝。
4 bytes.Buffer
bytes.Buffer是一个一个缓冲byte类型的缓冲器,这个缓冲器里存放着都是byte,
bytes.buffer底层也是一个[]byte切片。
5 strings.join
strings.join也是基于strings.builder来实现的,并且可以自定义分隔符,在join方法内调用了b.Grow(n)方法,这个是进行初步的容量分配,而前面计算的n的长度就是我们要拼接的slice的长度,因为我们传入切片长度固定,所以提前进行容量分配可以减少内存分配,很高效。
性能比较:
strings.Join ≈ strings.Builder > bytes.Buffer > "+" > fmt.Sprintf
5种拼接方法的实例代码
func main(){
a := []string{"a", "b", "c"}
//方式1:+
ret := a[0] + a[1] + a[2]
//方式2:fmt.Sprintf
ret := fmt.Sprintf("%s%s%s", a[0],a[1],a[2])
//方式3:strings.Builder
var sb strings.Builder
sb.WriteString(a[0])
sb.WriteString(a[1])
sb.WriteString(a[2])
ret := sb.String()
//方式4:bytes.Buffer
buf := new(bytes.Buffer)
buf.Write(a[0])
buf.Write(a[1])
buf.Write(a[2])
ret := buf.String()
//方式5:strings.Join
ret := strings.Join(a,"")
}
参考资料:字符串拼接性能及原理 | Go 语言高性能编程 | 极客兔兔
07 什么是 rune 类型
ASCII 码只需要 7 bit 就可以完整地表示,但只能表示英文字母在内的128个字符,为了表示世界上大部分的文字系统,发明了 Unicode, 它是ASCII的超集,包含世界上书写系统中存在的所有字符,并为每个代码分配一个标准编号(称为Unicode CodePoint),在 Go 语言中称之为 rune,是 int32 类型的别名。
Go 语言中,字符串的底层表示是 byte (8 bit) 序列,而非 rune (32 bit) 序列。
sample := "我爱GO"
runeSamp := []rune(sample)
runeSamp[0] = '你'
fmt.Println(string(runeSamp)) // "你爱GO"
fmt.Println(len(runeSamp)) // 4
08 如何判断 map 中是否包含某个 key ?
var sample map[int]int
if _, ok := sample[10]; ok {
} else {
}
09 Go 支持默认参数或可选参数吗?
不支持。但是可以利用结构体参数,或者...传入参数切片数组。
// 这个函数可以传入任意数量的整型参数
func sum(nums ...int) {
total := 0
for _, num := range nums {
total += num
}
fmt.Println(total)
}
10 defer 的执行顺序
defer执行顺序和调用顺序相反,类似于栈后进先出(LIFO)。
defer在return之后执行,但在函数退出之前,defer可以修改返回值。下面是一个例子:
func test() int {
i := 0
defer func() {
fmt.Println("defer1")
}()
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// defer1
// return 0
上面这个例子中,test返回值并没有修改,这是由于Go的返回机制决定的,执行Return语句后,Go会创建一个临时变量保存返回值。如果是有名返回(也就是指明返回值func test() (i int))
func test() (i int) {
i = 0
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// return 1
这个例子中,返回值被修改了。对于有名返回值的函数,执行 return 语句时,并不会再创建临时变量保存,因此,defer 语句修改了 i,即对返回值产生了影响。
11 如何交换 2 个变量的值?
对于变量而言a,b = b,a; 对于指针而言*a,*b = *b, *a
12 Go 语言 tag 的用处?
tag可以为结构体成员提供属性。常见的:
- json序列化或反序列化时字段的名称
- db: sqlx模块中对应的数据库字段名
- form: gin框架中对应的前端的数据字段名
- binding: 搭配 form 使用, 默认如果没查找到结构体中的某个字段则不报错值为空, binding为 required 代表没找到返回错误给前端
13 如何获取一个结构体的所有tag?
利用反射:
import reflect
type Author struct {
Name int `json:Name`
Publications []string `json:Publication,omitempty`
}
func main() {
t := reflect.TypeOf(Author{})
for i := 0; i < t.NumField(); i++ {
name := t.Field(i).Name
s, _ := t.FieldByName(name)
fmt.Println(name, s.Tag)
}
}
上述例子中,reflect.TypeOf方法获取对象的类型,之后NumField()获取结构体成员的数量。 通过Field(i)获取第i个成员的名字。 再通过其Tag 方法获得标签。
14 如何判断 2 个字符串切片(slice) 是相等的?
reflect.DeepEqual() , 但反射非常影响性能。
15 结构体打印时,%v 和 %+v 的区别
%v输出结构体各成员的值;
%+v输出结构体各成员的名称和值;
%#v输出结构体名称和结构体各成员的名称和值
16 Go 语言中如何表示枚举值(enums)?
在常量中用iota可以表示枚举。iota从0开始。
const (
B = 1 << (10 * iota)
KiB
MiB
GiB
TiB
PiB
EiB
)
17 空 struct{} 的用途
- 用map模拟一个set,那么就要把值置为struct{},struct{}本身不占任何空间,可以避免任何多余的内存分配。
type Set map[string]struct{}
func main() {
set := make(Set)
for _, item := range []string{"A", "A", "B", "C"} {
set[item] = struct{}{}
}
fmt.Println(len(set)) // 3
if _, ok := set["A"]; ok {
fmt.Println("A exists") // A exists
}
}- 有时候给通道发送一个空结构体,channel<-struct{}{},也是节省了空间。
func main() {
ch := make(chan struct{}, 1)
go func() {
<-ch
// do something
}()
ch <- struct{}{}
// ...
}- 仅有方法的结构体
type Lamp struct{}
18 go里面的int和int32是同一个概念吗?
不是一个概念!千万不能混淆。go语言中的int的大小是和操作系统位数相关的,如果是32位操作系统,int类型的大小就是4字节。如果是64位操作系统,int类型的大小就是8个字节。除此之外uint也与操作系统有关。
int8占1个字节,int16占2个字节,int32占4个字节,int64占8个字节。
实现原理
01 init() 函数是什么时候执行的?
简答: 在main函数之前执行。
详细:init()函数是go初始化的一部分,由runtime初始化每个导入的包,初始化不是按照从上到下的导入顺序,而是按照解析的依赖关系,没有依赖的包最先初始化。
每个包首先初始化包作用域的常量和变量(常量优先于变量),然后执行包的init()函数。同一个包,甚至是同一个源文件可以有多个init()函数。init()函数没有入参和返回值,不能被其他函数调用,同一个包内多个init()函数的执行顺序不作保证。
执行顺序:import –> const –> var –>init()–>main()
一个文件可以有多个init()函数!
02 ❤如何知道一个对象是分配在栈上还是堆上?
Go和C++不同,Go局部变量会进行逃逸分析。如果变量离开作用域后没有被引用,则优先分配到栈上,否则分配到堆上。那么如何判断是否发生了逃逸呢?
go build -gcflags '-m -m -l' xxx.go.
关于逃逸的可能情况:变量大小不确定,变量类型不确定,变量分配的内存超过用户栈最大值,暴露给了外部指针。
03 2 个 interface 可以比较吗 ?
Go 语言中,interface 的内部实现包含了 2 个字段,类型 T 和 值 V,interface 可以使用 == 或 != 比较。2 个 interface 相等有以下 2 种情况
- 两个 interface 均等于 nil(此时 V 和 T 都处于 unset 状态)
- 类型 T 相同,且对应的值 V 相等。
看下面的例子:
type Stu struct {
Name string
}
type StuInt interface{}
func main() {
var stu1, stu2 StuInt = &Stu{"Tom"}, &Stu{"Tom"}
var stu3, stu4 StuInt = Stu{"Tom"}, Stu{"Tom"}
fmt.Println(stu1 == stu2) // false
fmt.Println(stu3 == stu4) // true
}
stu1 和 stu2 对应的类型是 *Stu,值是 Stu 结构体的地址,两个地址不同,因此结果为 false。stu3 和 stu4 对应的类型是 Stu,值是 Stu 结构体,且各字段相等,因此结果为 true。
04 2 个 nil 可能不相等吗?
可能不等。interface在运行时绑定值,只有值为nil接口值才为nil,但是与指针的nil不相等。举个例子:
var p *int = nil
var i interface{} = nil
if(p == i){
fmt.Println("Equal")
}两者并不相同。总结:两个nil只有在类型相同时才相等。
05 ❤简述 Go 语言GC(垃圾回收)的工作原理
垃圾回收机制是Go一大特(nan)色(dian)。Go1.3采用标记清除法, Go1.5采用三色标记法,Go1.8采用三色标记法+混合写屏障。
标记清除法
分为两个阶段:标记和清除
标记阶段:从根对象出发寻找并标记所有存活的对象。
清除阶段:遍历堆中的对象,回收未标记的对象,并加入空闲链表。
缺点是需要暂停程序STW。
三色标记法:
将对象标记为白色,灰色或黑色。
白色:不确定对象(默认色);黑色:存活对象。灰色:存活对象,子对象待处理。
标记开始时,先将所有对象加入白色集合(需要STW)。首先将根对象标记为灰色,然后将一个对象从灰色集合取出,遍历其子对象,放入灰色集合。同时将取出的对象放入黑色集合,直到灰色集合为空。最后的白色集合对象就是需要清理的对象。
这种方法有一个缺陷,如果对象的引用被用户修改了,那么之前的标记就无效了。因此Go采用了写屏障技术,当对象新增或者更新会将其着色为灰色。
一次完整的GC分为四个阶段:
- 准备标记(需要STW),开启写屏障。
- 开始标记
- 标记结束(STW),关闭写屏障
- 清理(并发)
基于插入写屏障和删除写屏障在结束时需要STW来重新扫描栈,带来性能瓶颈。混合写屏障分为以下四步:
- GC开始时,将栈上的全部对象标记为黑色(不需要二次扫描,无需STW);
- GC期间,任何栈上创建的新对象均为黑色
- 被删除引用的对象标记为灰色
- 被添加引用的对象标记为灰色
总而言之就是确保黑色对象不能引用白色对象,这个改进直接使得GC时间从 2s降低到2us。
06 函数返回局部变量的指针是否安全?
这一点和C++不同,在Go里面返回局部变量的指针是安全的。因为Go会进行逃逸分析,如果发现局部变量的作用域超过该函数则会把指针分配到堆区,避免内存泄漏。
07 非接口的任意类型 T() 都能够调用 *T 的方法吗?反过来呢?
一个T类型的值可以调用*T类型声明的方法,当且仅当T是可寻址的。
反之:*T 可以调用T()的方法,因为指针可以解引用。
08 go slice是怎么扩容的?
Go <= 1.17
如果当前容量小于1024,则判断所需容量是否大于原来容量2倍,如果大于,当前容量加上所需容量;否则当前容量乘2。
如果当前容量大于1024,则每次按照1.25倍速度递增容量,也就是每次加上cap/4。
Go1.18之后,引入了新的扩容规则:浅谈 Go 1.18.1的切片扩容机制
并发编程
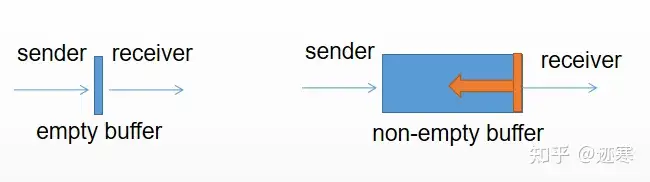
01 ❤无缓冲的 channel 和有缓冲的 channel 的区别?
(这个问题笔者也纠结了很久,直到看到一篇文章,阻塞与否是分别针对发送接收方而言的,才茅塞顿开)
对于无缓冲区channel:
发送的数据如果没有被接收方接收,那么发送方阻塞;如果一直接收不到发送方的数据,接收方阻塞;
有缓冲的channel:
发送方在缓冲区满的时候阻塞,接收方不阻塞;接收方在缓冲区为空的时候阻塞,发送方不阻塞。
可以类比生产者与消费者问题。
02 为什么有协程泄露(Goroutine Leak)?
协程泄漏是指协程创建之后没有得到释放。主要原因有:
- 缺少接收器,导致发送阻塞
- 缺少发送器,导致接收阻塞
- 死锁。多个协程由于竞争资源导致死锁。
- 创建协程的没有回收。
03 Go 可以限制运行时操作系统线程的数量吗? 常见的goroutine操作函数有哪些?
可以,使用runtime.GOMAXPROCS(num int)可以设置线程数目。该值默认为CPU逻辑核数,如果设的太大,会引起频繁的线程切换,降低性能。
runtime.Gosched(),用于让出CPU时间片,让出当前goroutine的执行权限,调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。
runtime.Goexit(),调用此函数会立即使当前的goroutine的运行终止(终止协程),而其它的goroutine并不会受此影响。runtime.Goexit在终止当前goroutine前会先执行此goroutine的还未执行的defer语句。请注意千万别在主函数调用runtime.Goexit,因为会引发panic。
04 如何控制协程数目。
The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
从官方文档的解释可以看到,GOMAXPROCS 限制的是同时执行用户态 Go 代码的操作系统线程的数量,但是对于被系统调用阻塞的线程数量是没有限制的。GOMAXPROCS 的默认值等于 CPU 的逻辑核数,同一时间,一个核只能绑定一个线程,然后运行被调度的协程。因此对于 CPU 密集型的任务,若该值过大,例如设置为 CPU 逻辑核数的 2 倍,会增加线程切换的开销,降低性能。对于 I/O 密集型应用,适当地调大该值,可以提高 I/O 吞吐率。
另外对于协程,可以用带缓冲区的channel来控制,下面的例子是协程数为1024的例子
var wg sync.WaitGroup
ch := make(chan struct{}, 1024)
for i:=0; i<20000; i++{
wg.Add(1)
ch<-struct{}{}
go func(){
defer wg.Done()
<-ch
}
}
wg.Wait()此外还可以用协程池:其原理无外乎是将上述代码中通道和协程函数解耦,并封装成单独的结构体。常见第三方协程池库,比如tunny等。
面试题评价:★★★☆☆。偏容易和基础。分为基础语法、实现原理、并发编程三个大部分,需要读者有扎实的基础。
面试题2
来源:Durant Thorvalds
❤new和make的区别?
- new只用于分配内存,返回一个指向地址的指针。它为每个新类型分配一片内存,初始化为0且返回类型*T的内存地址,它相当于&T{}
- make只可用于slice,map,channel的初始化,返回的是引用。
请你讲一下Go面向对象是如何实现的?
Go实现面向对象的两个关键是struct和interface。
封装:对于同一个包,对象对包内的文件可见;对不同的包,需要将对象以大写开头才是可见的。
继承:继承是编译时特征,在struct内加入所需要继承的类即可:
type A struct{}
type B struct{
A
}多态:多态是运行时特征,Go多态通过interface来实现。类型和接口是松耦合的,某个类型的实例可以赋给它所实现的任意接口类型的变量。
Go支持多重继承,就是在类型中嵌入所有必要的父类型。
uint型变量值分别为 1,2,它们相减的结果是多少?
var a uint = 1
var b uint = 2
fmt.Println(a - b)答案,结果会溢出,如果是32位系统,结果是2^32-1,如果是64位系统,结果2^64-1.
讲一下go有没有函数在main之前执行?怎么用?
go的init函数在main函数之前执行,它有如下特点:
func init() {
...
}init函数非常特殊:
- 初始化不能采用初始化表达式初始化的变量;
- 程序运行前执行注册
- 实现sync.Once功能
- 不能被其它函数调用
- init函数没有入口参数和返回值:
- 每个包可以有多个init函数,每个源文件也可以有多个init函数。
- 同一个包的init执行顺序,golang没有明确定义,编程时要注意程序不要依赖这个执行顺序。
- 不同包的init函数按照包导入的依赖关系决定执行顺序。
下面这句代码是什么作用,为什么要定义一个空值?
type GobCodec struct{
conn io.ReadWriteCloser
buf *bufio.Writer
dec *gob.Decoder
enc *gob.Encoder
}
type Codec interface {
io.Closer
ReadHeader(*Header) error
ReadBody(interface{}) error
Write(*Header, interface{}) error
}
var _ Codec = (*GobCodec)(nil)答:将nil转换为*GobCodec类型,然后再转换为Codec接口,如果转换失败,说明*GobCodec没有实现Codec接口的所有方法。
❤golang的内存管理的原理清楚吗?简述go内存管理机制。
golang内存管理基本是参考tcmalloc来进行的。go内存管理本质上是一个内存池,只不过内部做了很多优化:自动伸缩内存池大小,合理的切割内存块。
一些基本概念:
页Page:一块8K大小的内存空间。Go向操作系统申请和释放内存都是以页为单位的。
span : 内存块,一个或多个连续的 page 组成一个 span 。如果把 page 比喻成工人, span 可看成是小队,工人被分成若干个队伍,不同的队伍干不同的活。
sizeclass : 空间规格,每个 span 都带有一个 sizeclass ,标记着该 span 中的 page 应该如何使用。使用上面的比喻,就是 sizeclass 标志着 span 是一个什么样的队伍。
object : 对象,用来存储一个变量数据内存空间,一个 span 在初始化时,会被切割成一堆等大的 object 。假设 object 的大小是 16B , span 大小是 8K ,那么就会把 span 中的 page 就会被初始化 8K / 16B = 512 个 object 。所谓内存分配,就是分配一个 object 出去。
- mheap
一开始go从操作系统索取一大块内存作为内存池,并放在一个叫mheap的内存池进行管理,mheap将一整块内存切割为不同的区域,并将一部分内存切割为合适的大小。
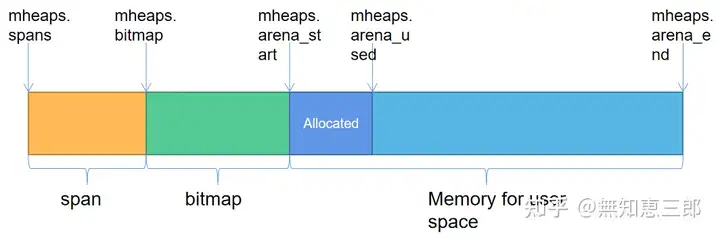
mheap.spans :用来存储 page 和 span 信息,比如一个 span 的起始地址是多少,有几个 page,已使用了多大等等。
mheap.bitmap 存储着各个 span 中对象的标记信息,比如对象是否可回收等等。
mheap.arena_start : 将要分配给应用程序使用的空间。
- mcentral
用途相同的span会以链表的形式组织在一起存放在mcentral中。这里用途用sizeclass来表示,就是该span存储哪种大小的对象。
找到合适的 span 后,会从中取一个 object 返回给上层使用。
- mcache
为了提高内存并发申请效率,加入缓存层mcache。每一个mcache和处理器P对应。Go申请内存首先从P的mcache中分配,如果没有可用的span再从mcentral中获取。
参考资料:Go 语言内存管理(二):Go 内存管理
❤mutex有几种模式?
mutex有两种模式:normal 和 starvation
正常模式
所有goroutine按照FIFO的顺序进行锁获取,被唤醒的goroutine和新请求锁的goroutine同时进行锁获取,通常新请求锁的goroutine更容易获取锁(持续占有cpu),被唤醒的goroutine则不容易获取到锁。公平性:否。
饥饿模式
所有尝试获取锁的goroutine进行等待排队,新请求锁的goroutine不会进行锁获取(禁用自旋),而是加入队列尾部等待获取锁。公平性:是。
参考链接:Go Mutex 饥饿模式,GO 互斥锁(Mutex)原理
面试题3
来源:如果你是一个Golang面试官,你会问哪些问题?
❤go如何进行调度的。GMP中状态流转。
Go里面GMP分别代表:G:goroutine,M:线程(真正在CPU上跑的),P:调度器。
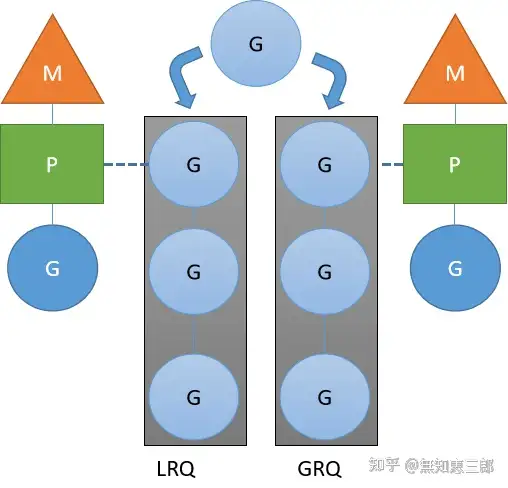
调度器是M和G之间桥梁。
go进行调度过程:
- 某个线程尝试创建一个新的G,那么这个G就会被安排到这个线程的G本地队列LRQ中,如果LRQ满了,就会分配到全局队列GRQ中;
- 尝试获取当前线程的M,如果无法获取,就会从空闲的M列表中找一个,如果空闲列表也没有,那么就创建一个M,然后绑定G与P运行。
- 进入调度循环:
- 找到一个合适的G
- 执行G,完成以后退出
Go什么时候发生阻塞?阻塞时,调度器会怎么做。
- 用于原子、互斥量或通道操作导致goroutine阻塞,调度器将把当前阻塞的goroutine从本地运行队列LRQ换出,并重新调度其它goroutine;
- 由于网络请求和IO导致的阻塞,Go提供了网络轮询器(Netpoller)来处理,后台用epoll等技术实现IO多路复用。
其它回答:
- channel阻塞:当goroutine读写channel发生阻塞时,会调用gopark函数,该G脱离当前的M和P,调度器将新的G放入当前M。
- 系统调用:当某个G由于系统调用陷入内核态,该P就会脱离当前M,此时P会更新自己的状态为Psyscall,M与G相互绑定,进行系统调用。结束以后,若该P状态还是Psyscall,则直接关联该M和G,否则使用闲置的处理器处理该G。
- 系统监控:当某个G在P上运行的时间超过10ms时候,或者P处于Psyscall状态过长等情况就会调用retake函数,触发新的调度。
- 主动让出:由于是协作式调度,该G会主动让出当前的P(通过GoSched),更新状态为Grunnable,该P会调度队列中的G运行。
更多关于netpoller的内容可以参看:https://strikefreedom.top/go-netpoll-io-multiplexing-reactor
❤Go中GMP有哪些状态?
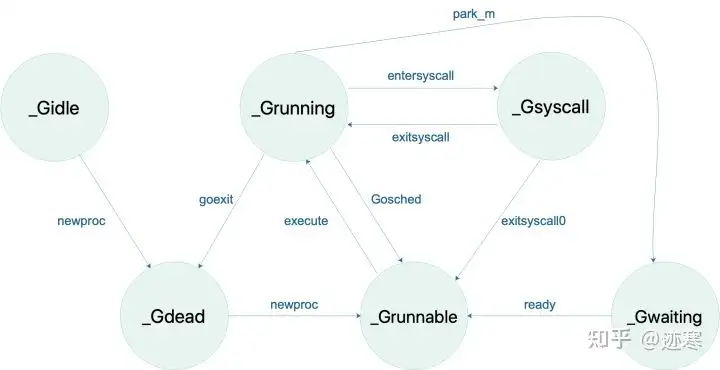
G的状态:
_Gidle:刚刚被分配并且还没有被初始化,值为0,为创建goroutine后的默认值
_Grunnable: 没有执行代码,没有栈的所有权,存储在运行队列中,可能在某个P的本地队列或全局队列中(如上图)。
_Grunning: 正在执行代码的goroutine,拥有栈的所有权(如上图)。
_Gsyscall:正在执行系统调用,拥有栈的所有权,与P脱离,但是与某个M绑定,会在调用结束后被分配到运行队列(如上图)。
_Gwaiting:被阻塞的goroutine,阻塞在某个channel的发送或者接收队列(如上图)。
_Gdead: 当前goroutine未被使用,没有执行代码,可能有分配的栈,分布在空闲列表gFree,可能是一个刚刚初始化的goroutine,也可能是执行了goexit退出的goroutine(如上图)。
_Gcopystac:栈正在被拷贝,没有执行代码,不在运行队列上,执行权在
_Gscan : GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在。
P的状态:
_Pidle :处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空
_Prunning :被线程 M 持有,并且正在执行用户代码或者调度器(如上图)
_Psyscall:没有执行用户代码,当前线程陷入系统调用(如上图)
_Pgcstop :被线程 M 持有,当前处理器由于垃圾回收被停止
_Pdead :当前处理器已经不被使用
M的状态:
自旋线程:处于运行状态但是没有可执行goroutine的线程,数量最多为GOMAXPROC,若是数量大于GOMAXPROC就会进入休眠。
非自旋线程:处于运行状态有可执行goroutine的线程。
GMP能不能去掉P层?会怎么样?
P层的作用
- 每个 P 有自己的本地队列,大幅度的减轻了对全局队列的直接依赖,所带来的效果就是锁竞争的减少。而 GM 模型的性能开销大头就是锁竞争。
- 每个 P 相对的平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行,减少空转,提高了资源利用率。
参考资料:https://juejin.cn/post/6968311281220583454
如果有一个G一直占用资源怎么办?什么是work stealing算法?
如果有个goroutine一直占用资源,那么GMP模型会从正常模式转变为饥饿模式(类似于mutex),允许其它goroutine使用work stealing抢占(禁用自旋锁)。
work stealing算法指,一个线程如果处于空闲状态,则帮其它正在忙的线程分担压力,从全局队列取一个G任务来执行,可以极大提高执行效率。
goroutine什么情况会发生内存泄漏?如何避免。
在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
暂时性内存泄露
- 获取长字符串中的一段导致长字符串未释放
- 获取长slice中的一段导致长slice未释放
- 在长slice新建slice导致泄漏
string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏
永久性内存泄露
- goroutine永久阻塞而导致泄漏
- time.Ticker未关闭导致泄漏
- 不正确使用Finalizer(Go版本的析构函数)导致泄漏
Go GC有几个阶段
目前的go GC采用三色标记法和混合写屏障技术。
Go GC有四个阶段:
- STW,开启混合写屏障,扫描栈对象;
- 将所有对象加入白色集合,从根对象开始,将其放入灰色集合。每次从灰色集合取出一个对象标记为黑色,然后遍历其子对象,标记为灰色,放入灰色集合;
- 如此循环直到灰色集合为空。剩余的白色对象就是需要清理的对象。
- STW,关闭混合写屏障;
- 在后台进行GC(并发)。
go竞态条件了解吗?
所谓竞态竞争,就是当两个或以上的goroutine访问相同资源时候,对资源进行读/写。
比如var a int = 0,有两个协程分别对a+=1,我们发现最后a不一定为2.这就是竞态竞争。
通常我们可以用go run -race xx.go来进行检测。
解决方法是,对临界区资源上锁,或者使用原子操作(atomics),原子操作的开销小于上锁。
如果若干个goroutine,有一个panic会怎么做?
有一个panic,那么剩余goroutine也会退出,程序退出。如果不想程序退出,那么必须通过调用 recover() 方法来捕获 panic 并恢复将要崩掉的程序。
参考理解:goroutine配上panic会怎样。
defer可以捕获goroutine的子goroutine吗?
不可以。它们处于不同的调度器P中。对于子goroutine,必须通过 recover() 机制来进行恢复,然后结合日志进行打印(或者通过channel传递error),下面是一个例子:
// 心跳函数
func Ping(ctx context.Context) error {
... code ...
go func() {
defer func() {
if r := recover(); r != nil {
log.Errorc(ctx, "ping panic: %v, stack: %v", r, string(debug.Stack()))
}
}()
... code ...
}()
... code ...
return nil
}
❤gRPC是什么?
基于go的远程过程调用。RPC 框架的目标就是让远程服务调用更加简单、透明,RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP)、序列化方式(XML/Json/ 二进制)和通信细节。服务调用者可以像调用本地接口一样调用远程的服务提供者,而不需要关心底层通信细节和调用过程。
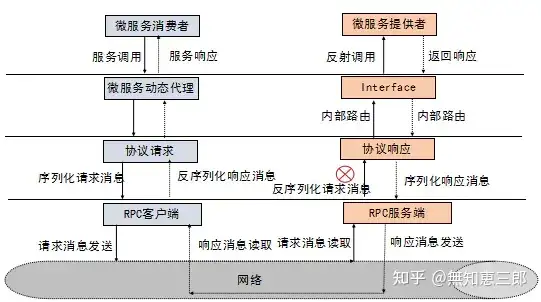
面试题4
需要面试者有一定的大型项目经验经验,了解使用微服务,etcd,gin,gorm,gRPC等典型框架等模型或框架。
微服务了解吗?
微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的 API 进行通信的小型独立服务组成。微服务架构使应用程序更易于扩展和更快地开发,从而加速创新并缩短新功能的上市时间。
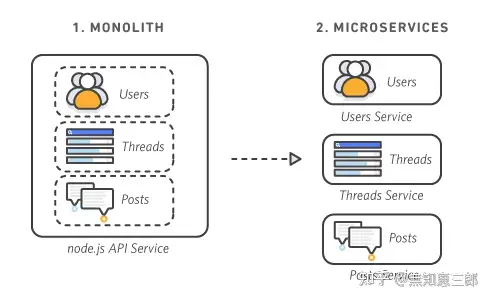
微服务有着自主,专用,灵活性等优点。
参考资料:什么是微服务?| AWS
服务发现是怎么做的?
主要有两种服务发现机制:客户端发现和服务端发现。
客户端发现模式:当我们使用客户端发现的时候,客户端负责决定可用服务实例的网络地址并且在集群中对请求负载均衡, 客户端访问服务登记表,也就是一个可用服务的数据库,然后客户端使用一种负载均衡算法选择一个可用的服务实例然后发起请求。该模式如下图所示:
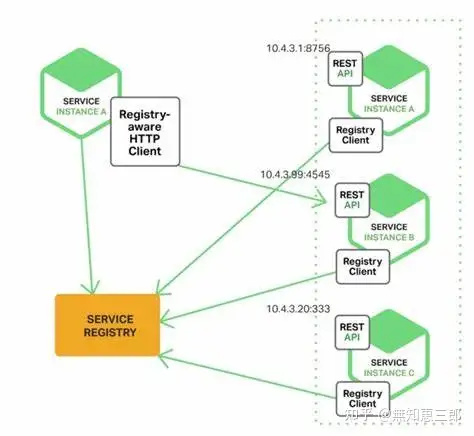
服务端发现模式:客户端通过负载均衡器向某个服务提出请求,负载均衡器查询服务注册表,并将请求转发到可用的服务实例。如同客户端发现,服务实例在服务注册表中注册或注销。

参考资料:「Chris Richardson 微服务系列」服务发现的可行方案以及实践案例
ETCD用过吗?
etcd是一个高度一致的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。它可以优雅地处理网络分区期间的领导者选举,即使在领导者节点中也可以容忍机器故障。
etcd 是用Go语言编写的,它具有出色的跨平台支持,小的二进制文件和强大的社区。etcd机器之间的通信通过Raft共识算法处理。
关于文档可以参考:v3.5 docs
GIN怎么做参数校验?
go采用validator作参数校验。
它具有以下独特功能:
- 使用验证tag或自定义validator进行跨字段Field和跨结构体验证。
- 允许切片、数组和哈希表,多维字段的任何或所有级别进行校验。
- 能够对哈希表key和value进行验证
- 通过在验证之前确定它的基础类型来处理类型接口。
- 别名验证标签,允许将多个验证映射到单个标签,以便更轻松地定义结构体上的验证
- gin web 框架的默认验证器;
参考资料:validator package - pkg.go.dev
中间件用过吗?
Middleware是Web的重要组成部分,中间件(通常)是一小段代码,它们接受一个请求,对其进行处理,每个中间件只处理一件事情,完成后将其传递给另一个中间件或最终处理程序,这样就做到了程序的解耦。
Go解析Tag是怎么实现的?
Go解析tag采用的是反射。
具体来说使用reflect.ValueOf方法获取其反射值,然后获取其Type属性,之后再通过Field(i)获取第i+1个field,再.Tag获得Tag。
反射实现的原理在: `src/reflect/type.go`中
你项目有优雅的启停吗?
所谓「优雅」启停就是在启动退出服务时要满足以下几个条件:
- 不可以关闭现有连接(进程)
- 新的进程启动并「接管」旧进程
- 连接要随时响应用户请求,不可以出现拒绝请求的情况
- 停止的时候,必须处理完既有连接,并且停止接收新的连接。
为此我们必须引用信号来完成这些目的:
启动:
- 监听SIGHUP(在用户终端连接(正常或非正常)结束时发出);
- 收到信号后将服务监听的文件描述符传递给新的子进程,此时新老进程同时接收请求;
退出:
- 监听SIGINT和SIGSTP和SIGQUIT等。
- 父进程停止接收新请求,等待旧请求完成(或超时);
- 父进程退出。
实现:go1.8采用Http.Server内置的Shutdown方法支持优雅关机。 然后fvbock/endless可以实现优雅重启。
参考资料:gin框架实践连载八 | 如何优雅重启和停止 - 掘金,优雅地关闭或重启 go web 项目
持久化怎么做的?
所谓持久化就是将要保存的字符串写到硬盘等设备。
- 最简单的方式就是采用ioutil的WriteFile()方法将字符串写到磁盘上,这种方法面临格式化方面的问题。
- 更好的做法是将数据按照固定协议进行组织再进行读写,比如JSON,XML,Gob,csv等。
- 如果要考虑高并发和高可用,必须把数据放入到数据库中,比如MySQL,PostgreDB,MongoDB等。
参考链接:Golang 持久化
面试题5
作者:Dylan2333 链接:

该试题需要面试者有非常丰富的项目阅历和底层原理经验,熟练使用微服务,etcd,gin,gorm,gRPC等典型框架等模型或框架。
channel 死锁的场景
- 当一个
channel中没有数据,而直接读取时,会发生死锁:
q := make(chan int,2)
<-q解决方案是采用select语句,再default放默认处理方式:
q := make(chan int,2)
select{
case val:=<-q:
default:
...
}- 当channel数据满了,再尝试写数据会造成死锁:
q := make(chan int,2)
q<-1
q<-2
q<-3解决方法,采用select
func main() {
q := make(chan int, 2)
q <- 1
q <- 2
select {
case q <- 3:
fmt.Println("ok")
default:
fmt.Println("wrong")
}
}- 向一个关闭的channel写数据。
注意:一个已经关闭的channel,只能读数据,不能写数据。
参考资料:Golang关于channel死锁情况的汇总以及解决方案
对已经关闭的chan进行读写会怎么样?
- 读已经关闭的chan能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
- 如果chan关闭前,buffer内有元素还未读,会正确读到chan内的值,且返回的第二个bool值(是否读成功)为true。
- 如果chan关闭前,buffer内有元素已经被读完,chan内无值,接下来所有接收的值都会非阻塞直接成功,返回 channel 元素的零值,但是第二个bool值一直为false。
写已经关闭的chan会panic。
说说 atomic底层怎么实现的.
atomic源码位于`sync\atomic`。通过阅读源码可知,atomic采用CAS(CompareAndSwap)的方式实现的。所谓CAS就是使用了CPU中的原子性操作。在操作共享变量的时候,CAS不需要对其进行加锁,而是通过类似于乐观锁的方式进行检测,总是假设被操作的值未曾改变(即与旧值相等),并一旦确认这个假设的真实性就立即进行值替换。本质上是不断占用CPU资源来避免加锁的开销。
参考资料:Go语言的原子操作atomic - 编程猎人
channel底层实现?是否线程安全。
channel底层实现在src/runtime/chan.go中
channel内部是一个循环链表。内部包含buf, sendx, recvx, lock ,recvq, sendq几个部分;
buf是有缓冲的channel所特有的结构,用来存储缓存数据。是个循环链表;
- sendx和recvx用于记录buf这个循环链表中的发送或者接收的index;
- lock是个互斥锁;
- recvq和sendq分别是接收(<-channel)或者发送(channel <- xxx)的goroutine抽象出来的结构体(sudog)的队列。是个双向链表。
channel是线程安全的。
参考资料:Kitou:Golang 深度剖析 -- channel的底层实现
map的底层实现。
源码位于src\runtime\map.go 中。
go的map和C++map不一样,底层实现是哈希表,包括两个部分:hmap和bucket。
里面最重要的是buckets(桶),buckets是一个指针,最终它指向的是一个结构体:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}每个bucket固定包含8个key和value(可以查看源码bucketCnt=8).实现上面是一个固定的大小连续内存块,分成四部分:每个条目的状态,8个key值,8个value值,指向下个bucket的指针。
创建哈希表使用的是makemap函数.map 的一个关键点在于,哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
map查找就是将key哈希后得到64位(64位机)用最后B个比特位计算在哪个桶。在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
关于map的查找和扩容可以参考map的用法到map底层实现分析。
select的实现原理?
select源码位于src\runtime\select.go,最重要的scase 数据结构为:
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}scase.c为当前case语句所操作的channel指针,这也说明了一个case语句只能操作一个channel。
scase.elem表示缓冲区地址:
- caseRecv : scase.elem表示读出channel的数据存放地址;
- caseSend : scase.elem表示将要写入channel的数据存放地址;
select的主要实现位于:select.go函数:其主要功能如下:
1. 锁定scase语句中所有的channel
2. 按照随机顺序检测scase中的channel是否ready
2.1 如果case可读,则读取channel中数据,解锁所有的channel,然后返回(case index, true)
2.2 如果case可写,则将数据写入channel,解锁所有的channel,然后返回(case index, false)
2.3 所有case都未ready,则解锁所有的channel,然后返回(default index, false)
3. 所有case都未ready,且没有default语句
3.1 将当前协程加入到所有channel的等待队列
3.2 当将协程转入阻塞,等待被唤醒
4. 唤醒后返回channel对应的case index
4.1 如果是读操作,解锁所有的channel,然后返回(case index, true)
4.2 如果是写操作,解锁所有的channel,然后返回(case index, false)
参考资料:Go select的使用和实现原理.
go的interface怎么实现的?
go interface源码在runtime\iface.go中。
go的接口由两种类型实现iface和eface。iface是包含方法的接口,而eface不包含方法。
iface
对应的数据结构是(位于src\runtime\runtime2.go):
type iface struct {
tab *itab
data unsafe.Pointer
}可以简单理解为,tab表示接口的具体结构类型,而data是接口的值。
- itab:
type itab struct {
inter *interfacetype //此属性用于定位到具体interface
_type *_type //此属性用于定位到具体interface
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}属性interfacetype类似于_type,其作用就是interface的公共描述,类似的还有maptype、arraytype、chantype…其都是各个结构的公共描述,可以理解为一种外在的表现信息。interfaetype和type唯一确定了接口类型,而hash用于查询和类型判断。fun表示方法集。
eface
与iface基本一致,但是用_type直接表示类型,这样的话就无法使用方法。
type eface struct {
_type *_type
data unsafe.Pointer
}这里篇幅有限,深入讨论可以看:深入研究 Go interface 底层实现
go的reflect 底层实现
go reflect源码位于src\reflect\下面,作为一个库独立存在。反射是基于接口实现的。
Go反射有三大法则:
- 反射从接口映射到反射对象;
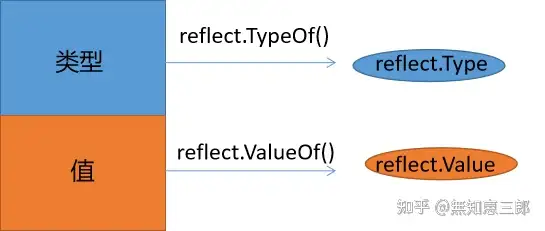
- 反射从反射对象映射到接口值;
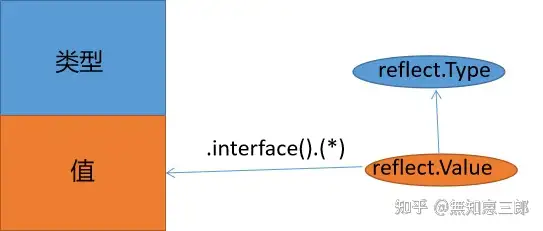
- 只有值可以修改(settable),才可以修改反射对象。
Go反射基于上述三点实现。我们先从最核心的两个源文件入手type.go和value.go.
type用于获取当前值的类型。value用于获取当前的值。
参考资料:The Laws of Reflection, 图解go反射实现原理
go GC的原理知道吗?
如果需要从源码角度解释GC,推荐阅读(非常详细,图文并茂):
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector/
go里用过哪些设计模式 ?

go的调试/分析工具用过哪些。
go的自带工具链相当丰富,
- go cover : 测试代码覆盖率;
- godoc: 用于生成go文档;
- pprof:用于性能调优,针对cpu,内存和并发;
- race:用于竞争检测;
进程被kill,如何保证所有goroutine顺利退出
goroutine监听SIGKILL信号,一旦接收到SIGKILL,则立刻退出。可采用select方法。
var wg = &sync.WaitGroup{}
func main() {
wg.Add(1)
go func() {
c1 := make(chan os.Signal, 1)
signal.Notify(c1, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
fmt.Printf("goroutine 1 receive a signal : %v\n\n", <-c1)
wg.Done()
}()
wg.Wait()
fmt.Printf("all groutine done!\n")
}
说说context包的作用?你用过哪些,原理知道吗?
context可以用来在goroutine之间传递上下文信息,相同的context可以传递给运行在不同goroutine中的函数,上下文对于多个goroutine同时使用是安全的,context包定义了上下文类型,可以使用background、TODO创建一个上下文,在函数调用链之间传播context,也可以使用WithDeadline、WithTimeout、WithCancel 或 WithValue 创建的修改副本替换它,听起来有点绕,其实总结起就是一句话:context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期。
关于context原理,可以参看:小白也能看懂的context包详解:从入门到精通
grpc为啥好,基本原理是什么,和http比呢
官方介绍:gRPC 是一个现代开源的高性能远程过程调用 (RPC) 框架,可以在任何环境中运行。它可以通过对负载平衡、跟踪、健康检查和身份验证的可插拔支持有效地连接数据中心内和跨数据中心的服务。它也适用于分布式计算的最后一英里,将设备、移动应用程序和浏览器连接到后端服务。
区别:
- rpc是远程过程调用,就是本地去调用一个远程的函数,而http是通过 url和符合restful风格的数据包去发送和获取数据;
- rpc的一般使用的编解码协议更加高效,比如grpc使用protobuf编解码。而http的一般使用json进行编解码,数据相比rpc更加直观,但是数据包也更大,效率低下;
- rpc一般用在服务内部的相互调用,而http则用于和用户交互;
相似点:
都有类似的机制,例如grpc的metadata机制和http的头机制作用相似,而且web框架,和rpc框架中都有拦截器的概念。grpc使用的是http2.0协议。
官网:gRPC
etcd怎么搭建的,具体怎么用的
熔断怎么做的
服务降级怎么搞
1亿条数据动态增长,取top10,怎么实现
进程挂了怎么办
nginx配置过吗,有哪些注意的点
设计一个阻塞队列
mq消费阻塞怎么办
性能没达到预期,有什么解决方案
编程系列
实现使用字符串函数名,调用函数。
思路:采用反射的Call方法实现。
package main
import (
"fmt"
"reflect"
)
type Animal struct{
}
func (a *Animal) Eat(){
fmt.Println("Eat")
}
func main(){
a := Animal{}
reflect.ValueOf(&a).MethodByName("Eat").Call([]reflect.Value{})
}
(Goroutine)有三个函数,分别打印"cat", "fish","dog"要求每一个函数都用一个goroutine,按照顺序打印100次。
此题目考察channel,用三个无缓冲channel,如果一个channel收到信号则通知下一个。
package main
import (
"fmt"
"time"
)
var dog = make(chan struct{})
var cat = make(chan struct{})
var fish = make(chan struct{})
func Dog() {
<-fish
fmt.Println("dog")
dog <- struct{}{}
}
func Cat() {
<-dog
fmt.Println("cat")
cat <- struct{}{}
}
func Fish() {
<-cat
fmt.Println("fish")
fish <- struct{}{}
}
func main() {
for i := 0; i < 100; i++ {
go Dog()
go Cat()
go Fish()
}
fish <- struct{}{}
time.Sleep(10 * time.Second)
}
两个协程交替打印10个字母和数字
思路:采用channel来协调goroutine之间顺序。
主线程一般要waitGroup等待协程退出,这里简化了一下直接sleep。
package main
import (
"fmt"
"time"
)
var word = make(chan struct{}, 1)
var num = make(chan struct{}, 1)
func printNums() {
for i := 0; i < 10; i++ {
<-word
fmt.Println(1)
num <- struct{}{}
}
}
func printWords() {
for i := 0; i < 10; i++ {
<-num
fmt.Println("a")
word <- struct{}{}
}
}
func main() {
num <- struct{}{}
go printNums()
go printWords()
time.Sleep(time.Second * 1)
}代码:
启动 2个groutine 2秒后取消, 第一个协程1秒执行完,第二个协程3秒执行完。
思路:采用ctx, _ := context.WithTimeout(context.Background(), time.Second*2)实现2s取消。协程执行完后通过channel通知,是否超时。
package main
import (
"context"
"fmt"
"time"
)
func f1(in chan struct{}) {
time.Sleep(1 * time.Second)
in <- struct{}{}
}
func f2(in chan struct{}) {
time.Sleep(3 * time.Second)
in <- struct{}{}
}
func main() {
ch1 := make(chan struct{})
ch2 := make(chan struct{})
ctx, _ := context.WithTimeout(context.Background(), 2*time.Second)
go func() {
go f1(ch1)
select {
case <-ctx.Done():
fmt.Println("f1 timeout")
break
case <-ch1:
fmt.Println("f1 done")
}
}()
go func() {
go f2(ch2)
select {
case <-ctx.Done():
fmt.Println("f2 timeout")
break
case <-ch2:
fmt.Println("f2 done")
}
}()
time.Sleep(time.Second * 5)
}代码:
当select监控多个chan同时到达就绪态时,如何先执行某个任务?
可以在子case再加一个for select语句。
func priority_select(ch1, ch2 <-chan string) {
for {
select {
case val := <-ch1:
fmt.Println(val)
case val2 := <-ch2:
priority:
for {
select {
case val1 := <-ch1:
fmt.Println(val1)
default:
break priority
}
}
fmt.Println(val2)
}
}
}
总结
Go面试复习应该有所侧重,关注切片,通道,异常处理,Goroutine,GMP模型,字符串高效拼接,指针,反射,接口,sync。对于比较难懂的部分,GMP模型和GC和内存管理,应该主动去看源码,然后慢慢理解。业务代码写多了,自然就有理解了。
推荐博客:

图书:
《Go语言底层原理剖析》
《Go高性能编程》
本文来自博客园,作者:易先讯,转载请注明原文链接:https://www.cnblogs.com/gongxianjin/p/16962958.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-12-07 谈软件-专家谈C/C++重构的操作与思路