
容器战争的胜利者Docker
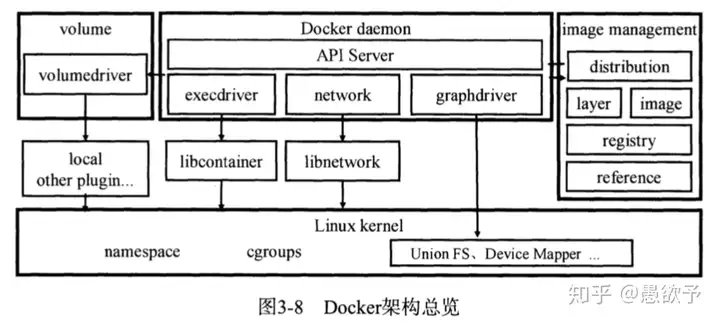
docker 的架构和发展
由于最早在2013年的时候,Docker 公司走红,而Docker公司的主打产品就是容器,因此我们现在谈到容器的时候,往往想到的是Docker,但是大家需要注意的是,容器并不是Docker的专利,而是内核的两个特性,进程隔离和Cgroup限制,任何人都可以借助内核特性创建容器,容器的本质是一组被限制的进程。
Docker公司真正创新的是容器镜像和容器卷。镜像可以说是Docker公司成功的杀手锏,把一次编译,到处运行扩大了一个层次,就是装软件和依赖库再也不用折腾了,遥想当年装依赖和库的血泪史,只要你把应用程序制作成镜像,那就可以到处跑,不只是Java等虚拟机语言,可以是任何语言写的程序。
最开始的docker架构非常简单,就是基于client-server模式,一个二进制同时支持两种模式运行,分别是客户端和服务端。启动docker的时候加-d参数就可以作为服务端,而通常docker命令就是客户端。
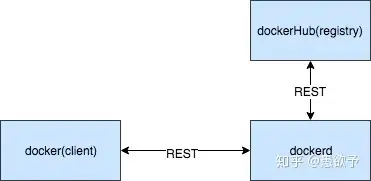
后来,容器和编排战争不断,docker不断的被拆解,并且还贡献出了很多组件。docker 1.11 以后的架构,已经变成了很多单独的组件。
现在docker的架构被拆为了四个部分: docker engine ,containerd ,containerd-shm ,runC二进制文件分别称为: dockerd,docker-containerd,docker-containerd-shim,docker-runc
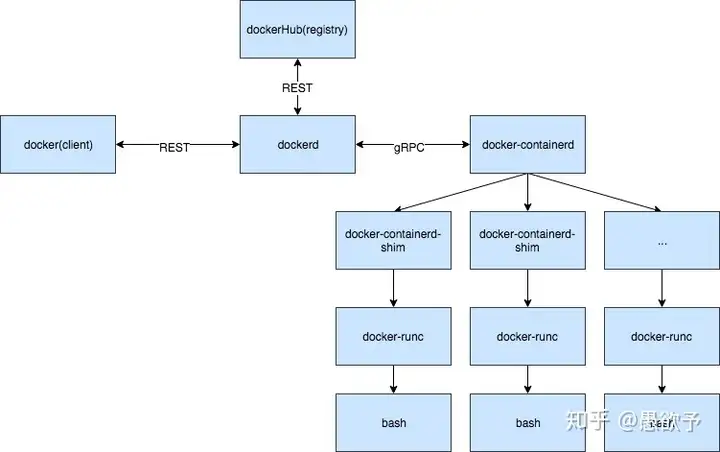
containerd架构
Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程: containerd 中了, 因此 Docker Daemon 其实仍然不能帮我们创建容器, 而是要请求 containerd 创建一个容器;
containerd 收到请求后, 并不会自己直接去操作容器, 而是创建一个叫做 containerd-shim 的进程, 让 containerd-shim 去操作容器。
这是因为容器进程需要一个父进程来做诸如收集状态, 维持 stdin 等 fd 打开等工作. 而假如这个父进程就是 containerd, 那每次 containerd 挂掉或升级, 整个宿主机上所有的容器都得退出了。 而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不需要是父子进程关系, 当 containerd 退出或重启时, shim 会 re-parent 到 systemd 这样的 1 号进程上);
我们知道创建容器需要做一些设置 namespaces 和 cgroups, 挂载 root filesystem 等等操作, 而这些事该怎么做已经有了公开的规范了, 那就是 OCI(Open Container Initiative, 开放容器标准). 它的一个参考实现叫做 runc. 于是, containerd-shim 在这一步需要调用 runc 这个命令行工具, 来启动容器;
runc 启动完容器后本身会直接退出, containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程;
docker ctr
| |
V V
dockerd -> containerd ---> shim -> runc -> runc init -> process
|-- > shim -> runc -> runc init -> process
+-- > shim -> runc -> runc init -> process```CRI(Container Runtime Interface)
介绍完了Docker以及容器运行时,下面介绍kubelet如何对接容器运行时。kubelet 最开始直接使用Docker作为container runtime的引擎,通过Docker 来进行容器操作。在1.6.6的代码中,你还能看到初始化的时候,runtime可以选择DockerManager,DockerManager实现的是runtime 接口。DockerManager 其实很简单,就是把 docker client 封装一下,通过 http 和docker 引擎通讯,进行容器的增删改查。
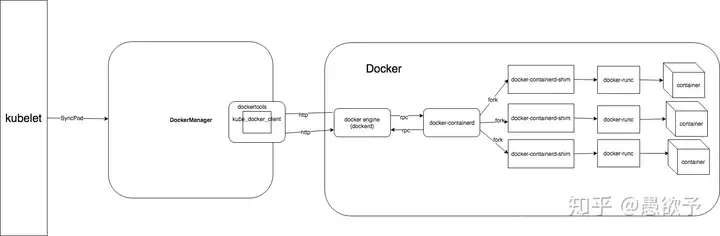
但是后来,kubelet 又引入了 KubeGenericRuntimeManager,用来替代 DockerManager。就这样,runtime 这个接口由语言层面的规范,上升到了协议层面的基于gRPC的规范。
KubeGenericRuntimeManager 在KEP[(Client/Server container runtime)](kubernetes/community),中提出,这个Proposal开始提出CRI,也就是提出了一个 容器运行时 接入 kubelet 的一种规范。该 KEP 的主要动机有一下两点:
- 更容易支持新的容器运行时
- 提高代码的可维护性
其实目的其实很纯粹,就是为了解耦,不然kubelet 每支持一种新的容器运行时,都必须在自己的代码加入对应的实现,维护起来很麻烦。这个KEP中,CRI其实就是 KubeGenericRuntimeManager 中远程调用 RemoteRuntime 的这些接口。
Kubelet KubeletGenericRuntimeManager RemoteRuntime
+ + +
| | |
+---------SyncPod------------->+ |
| | |
| +---- Create PodSandbox ------->+
| +<------------------------------+
| | |
| XXXXXXXXXXXX |
| | X |
| | NetworkPlugin. |
| | SetupPod |
| | X |
| XXXXXXXXXXXX |
| | |
| +<------------------------------+
| +---- Pull image1 -------->+
| +<------------------------------+
| +---- Create container1 ------->+
| +<------------------------------+
| +---- Start container1 -------->+
| +<------------------------------+
| | |
| +<------------------------------+
| +---- Pull image2 -------->+
| +<------------------------------+
| +---- Create container2 ------->+
| +<------------------------------+
| +---- Start container2 -------->+
| +<------------------------------+
| | |
| <-------Success--------------+ |
| | |
+ + +
但是这个引入,反而把调用链变长了。。
CRI 是K8S 定义的一套容器运行时接口,基于gRPC通讯,但是docker不是基于CRI的,因此 kubelet 又把docker 封装了一层,搞了一个所谓的shim,也即是dockershim的东西,dockershim 作为一个实现了CRI 接口的gRPC服务器,供 kubelet 使用。这样的过程其实就是,kubelet作为客户端 通过gRPC调用dockershim服务器,dockershim 内部又通过docker客户端走 http 调用 docker daemon api,多走了一次通讯的开销。下图是目前默认使用docker作为容器引擎的时候,调用过程。
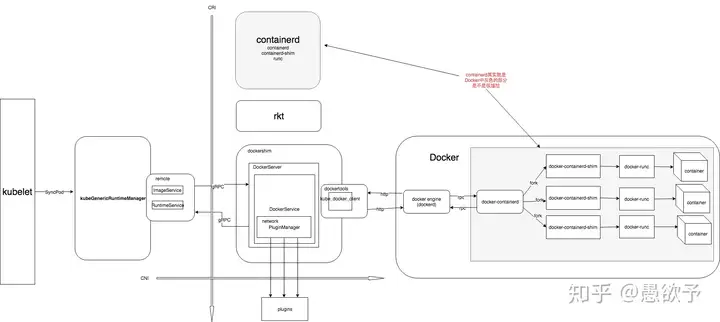
目前docker 1.11 以上开始,docker架构也变得零散,其实已经拆解出了containerd,上图的中docker engine又会继续走gRPC。
也就是说,为了做一次容器操作,进行了两次rpc,一次http,光从这个调用链来看,就处理的不够优雅。
Docker还能继续吗
Docker赢得了容器战争,但是输掉了编排战争,作为容器运行时的首选,kubelet早期支持docker是肯定的,不过,当人们已经习惯了在Kubernetes上使用Pod以及其它众多资源的时候,Kubernetes偷偷换掉容器运行时并不是不可以。
所以在2018年,kubernetes 宣布可以直接使用 containerd 来当容器引擎,从上文我讲述的CRI接口可以看到,直接使用containerd是可以省去很多中间步骤的,不会搞得那么冗余。

containerd 其实也经历了一些演变,早期 containerd 1.0 的调用链其实还是很长,和docker一样也需要一个实现了CRI的进程来负责和kubelet通讯,然后再和containerd通讯,但是到了 containerd 1.1 , containerd 将cri 做成了插件程序集成到了自己内部,这样就彻底减少了调用链的长度,一次 rpc 就可以操控运行时了。
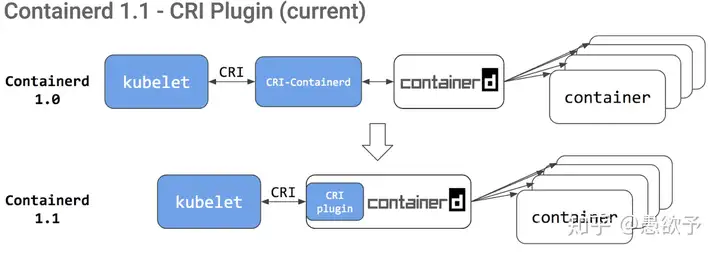
使用 containerd 作为kubelet的CRI,而不需要用 dockershim了。因为 containerd 完美支持cri,cri 只是 oci 的一个子集,并且 containerd 1.1 比 docker 1.18 更稳定快速。
目前阿里云的serverless产品使用的Kubernetes其实用的就是containerd,同时ebay已经将其2w台服务器全部切换成了containerd,也就是说,containerd很可能马上就会替代docker,成为Kubernetes首选的容器运行时。
从 containerd 官方主页看到,containerd 本身的设计初衷,就是嵌入到一个更大型的系统中供使用的,直接支持基于gRPC的CRI接口,那么就直接支持 Kubernetes。这样 Kubernetes 就可以不使用 Docker 来运行容器了,少了一层对 Docker 的冗余包装。
本文来自博客园,作者:易先讯,转载请注明原文链接:https://www.cnblogs.com/gongxianjin/p/16945018.html
