


论文笔记:Causal Attention for Vision-Language Tasks
论文笔记:Causal Attention for Vision-Language Tasks
Paper: Causal Attention for Vision-Language Tasks, CVPR 2021
Code: https://github.com/yangxuntu/lxmertcatt
概述
本文的主要工作就是利用因果理论对 attention 机制进行建模,然后从因果的角度分析了目前 attention 机制存在的问题,同时利用因果理论中的一些工具来解决。
因果模型的最大好处是它能解决数据分布不一致的问题,即训练集和测试集分布不一致,这对于传统的机器学习模型是很难克服的(通常得对采样特殊处理或者数据增强之类的),因果模型提供了一套比较好的方法去解决这样的问题(当然前提是你得先能构建出因果图)。
最近看了挺多张含望老师他们组的工作,见https://mreallab.github.io/,基本上都是针对cv领域的各种数据分布带来 bias 的问题,建立了各种各样的因果图进行分析并解决,个人觉得挺有意思的,所以最近想尝试入一下坑。
Try to accomplish
Attention 机制现在广泛应用在各领域和各模型之中,attention 涉及到了 Q-K-V 操作,想法是用 Q 去查找 K 中跟自己相似的成分,然后获得新的表示,具体做法就是先用 Q 和 K 求一个相似度作为权重,然后利用相似度对 V 进行加权获得一个新的表示,这个新的表示就融合了 Q 和 K 的相似度信息。
论文里用 image caption 举例说明了 vision-language 领域里两种使用 attention 的方式,如下图所示:

主要用到了两种 attention 模块,一种是 self-attention,另一种是 top-down attention。输入 X 包含了句子特征以及图像特征(RoI 特征),由于Q 与 K、V 相同,经过 self-attention 得到的新的特征表示,蕴含了图像特征之间的关联,例如上图中新的特征可能学到了人与马之间的关系。第二步就是 top-attention 模块,这里把 Q 换成了句子特征,当用 Q 与 K 求权重的时候,其实就是在求图像特征中哪些成分与句子特征更相关,例如根据“man”可能就会认为人所在的区域的图像特征权重更大,然后再用这个权重对图像特征加权后,所得到的新特征就是与句子相关的视觉特征。最后我们根据这个句子相关的视觉特征来做预测效果就会更好,因为它融入了两个模态相似度的信息。
那么这里面存在什么问题呢?

比如上面最左边的图,问题中关键字是“What sport”、“on screen”,但经过训练后的 attention 却把注意力放在了人身上(红色框),即提取到的句子相关的视觉特征是那两个人的区域,最后得到了错误的答案“Dancing”,而我们希望的是模型能够将注意力放在图像的屏幕区域,是什么导致了错误的 attention 呢?
作者认为是在训练集中,“Sport+Man”的出现次数远远高于“Sport+Screen”的次数,这样的偏倚让 attenion 学习的时候,会把“Sport”和人所在区域的图像特征联系起来,认为它们二者具有高相关性。但如果在测试集中,“Sport”和人所在区域的图像特征并没有这么高的相关性时(即训练集和测试集的分布不一致),那么在测试集中预测的时候带上这样的偏倚,很可能就会做出错误的预测。
Key element
因果图
如上面分析,数据集带来了 bias,从而产生了一些虚假的相关性(“Sport”和人图像特征),而建模和消除虚假相关性正是因果理论擅长的事,现在来看看作者是怎么对整个 vision-language 进行因果建模的,当然这是作者自己的想法,因果图并不是唯一确定的东西。
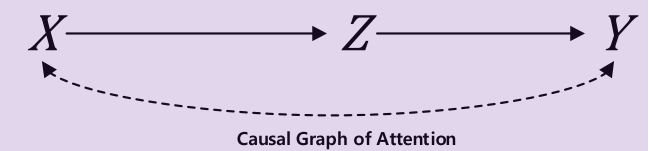
首先如第一张图所示,X 表示输入的数据,即原始的句子以及图像特征,Z 代表了句子相关的图像知识,X 和 Z 之间就存在着一个 X->Z 的因果关系,因为 Z 是 X 通过 attention 机制生成的嘛。然后利用 Z 去对最终结果 Y 做预测,显然这里也存在着 Z->Y,所以第一张图说明了从 X->Z->Y 的一条因果路径,即 X 通过 attention 机制做出的预测,这也是本文的重点研究目标。
如果只有这一条路径显然就不存在虚假的相关性,那么下一步作者就对为什么会产生虚假相关性这一点进行了建模,如下图所示:

这里 C 表示常识,C->X 表明视觉数据或者特征本质上是由常识生成的,例如第一张图中人骑马的图可以认为是常识“人可以骑马”生成的。M 表示 {person, horse} 的 object 集,它也是从图像中提取出来的(例如使用 Faster R-CNN),而它本身的值域也是由常识 C 决定的,最后对词的预测是根据 object 集做出的预测,所以是 M->Y。
从因果角度看 Attention
有了因果图后,首先先从因果角度看下 attention 机制,即 X->Z->Y 这条因果路径,传统的模型是基于相关性
这里是只考虑 X->Z->Y 因果图下的公式,还是比较直观的,P(Y|Z=z)表示知识对 Y 的预测,P(Z=z|X)表示根据 X 来选择相关的知识,不同的知识重要程度不同。按照我的理解,z 就是 attention 机制里的 K 和 V,P(Z=z|X) 其实就是 Q 和 K 求到的权重 \(\alpha\)。
但公式里是根据这个 P(Z=z|X) 对每个 z 对 Y 的预测结果 P(Y|Z=z) 求期望,也就是 IS-Sampling 操作,而 attention 是先根据 \(\alpha\) 对 z 求了个期望,用这个期望的 z 再去做预测。这个细微的区别我看了几遍论文才看出来,按照作者的意思这两个是等价的,而且由于 attention 是先对输入求了期望,然后光把这个期望值丢进网络 forward 一边,肯定要比把所有输入全部 forward 然后在期望代价要小得多。
论文第 7 部分的公式 (19) 有类似的推导,即公式 (19) 的最后一行,本来按照前面的推导求期望应该停留在 g 外面,一开始不知道为啥作者的推导直接塞到函数的输入里了,后来我觉得应该是反正还不知道拟合结果怎样,那不如就先对输入求个期望,然后对期望 forward 之后的结果,让它和这两个操作反过来(先 forward 再期望)的结果一样不就行了。
总之,attention 的 Q-K-V 操作可以和这个条件概率公式对应起来了。
消除偏倚
正如前面构建的因果图,如果直接拟合 P(Y|X) 会带来 bias,bias 产生的原因是 C 这个 confounder,即 X<-C->M->Y 这条非因果路径,由于我们又没有 C 的数据,所以 back-door 是别想了。而我们想求的是 X->Z->Y 这条因果路径事实上也不需要 C 的数据。首先看 X->Z,X 和 Z 之间唯一能让信息流动的就只有这一条,别的路径统统被 M->Y<-Z 给对撞没了,所以 X 和 Z 之间没有混杂。
关键是 Z 和 Y 之间存在混杂,不过幸运地是这个混杂可以通过对 X 进行 adjust 给消除掉,而 X 的数据是我们有的,所以接下来就简单了,如下进行 back-door (关于 back-door 可以参考下别人的讲解的,简单来说就是分情况讨论,在不同的 X 下,P(Y|X=x,Z) 是该情况下 Z 对 Y 的因果效应,那么根据 X 的不同情况求个平均即可):
CS-Sampling跟上面的IS-Sampling一样也是求期望的操作,区别在于前者是来自于不同的样本,后者仅来自于当前样本。同时为了和 do(X) 里的 X 区分开,这里换成 \(x'\)。在后面会看到作者也和 attention 里的做法类似,直接把 CS-Sampling 丢给输入 Z 了。
有了 X 对 Z 因果以及 Z 到 Y 的因果,那么自然就能得到 X 到 Y 的因果(通过 Z)。结合两个公式,即把 P(Y|X) 展开式里的 P(Y|Z) 替换为 P(Y|do(X)),得到
即去偏倚后的 attention 比原来多了一个求期望的步骤。
IS-ATT 和 CS-ATT
本论文核心就是要实现上面这个 \(P(Y|do(X))\),首先我们先构造一个函数 \(g(\cdot)\) 来拟合 \(P(Y|Z,X)\),为了表示分布在 \(g\) 外面套一个 softmax,如下
最终结果 \(P(Y|do(X))\) 就是 \(P(Y|Z,X)\) 计算了两次期望(IS-Sampling 以及 CS-Sampling),然后如前面所说,为了减少数据 forward 次数,直接把这两个求期望塞到最原始的输入那里去做(具体推导可以见论文第 7 部分),总之这里直接放结果
依据这个推导,作者提出了两个 attention,一个就对应了原来的 attention,即 IS-ATT,另一个就是 CS-ATT,如下图

未完
碎碎念
因为本论文使用的是 front-door adjustment,所以只要再找一个 confounder,且这个 confounder 不会有一条到 Z 的因果路径都能使用 front-door,我比较困惑的是作者对虚假相关性这部分建模的时候引入了又一条 X 到 Y 的因果路径,即 X->M->Y,这样就会导致实际上 P(Y|do(X)) 计算的其实是有这条路径的信息在里面的,而 X->M 又被 C 给 confound 了,所以这应该没法用 front-door 才对。
但作者依然对 X->Z->Y 这条路径用了 front-door 的公式,事实上计算的就不是 P(Y|do(X)) 了,而仅仅是 X 通过 Z 对 Y 对因果效应。当然这也是本文的核心所在,研究纯纯的因为 attention 的影响,所以好像也没啥毛病,只不过写 P(Y|do(X)) 可能就有点小问题了,起码在论文里给出的因果图我觉得是有些问题。

