
论文笔记:Adaptive Consistency Regularization for Semi-Supervised Transfer Learning (CVPR 2021)
论文笔记:Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Paper: Adaptive Consistency Regularization for Semi-Supervised Transfer Learning, CVPR 2021
Code: https://github.com/SHI-Labs/Semi-Supervised-Transfer-Learning
Try to accomplish
以往的半监督学习所用的模型大多都是随机初始化的,因为如果使用了预训练模型,半监督就很难带来很多性能提升,然而那些只是简单地将两种学习方法结合,这篇论文里提出了一个新的将迁移学习和半监督学习结合的模型,在保留了预训练模型的知识的基础上,也让半监督学习发挥出相应的性能提升。
学习目标
整个模型的结构图如下:
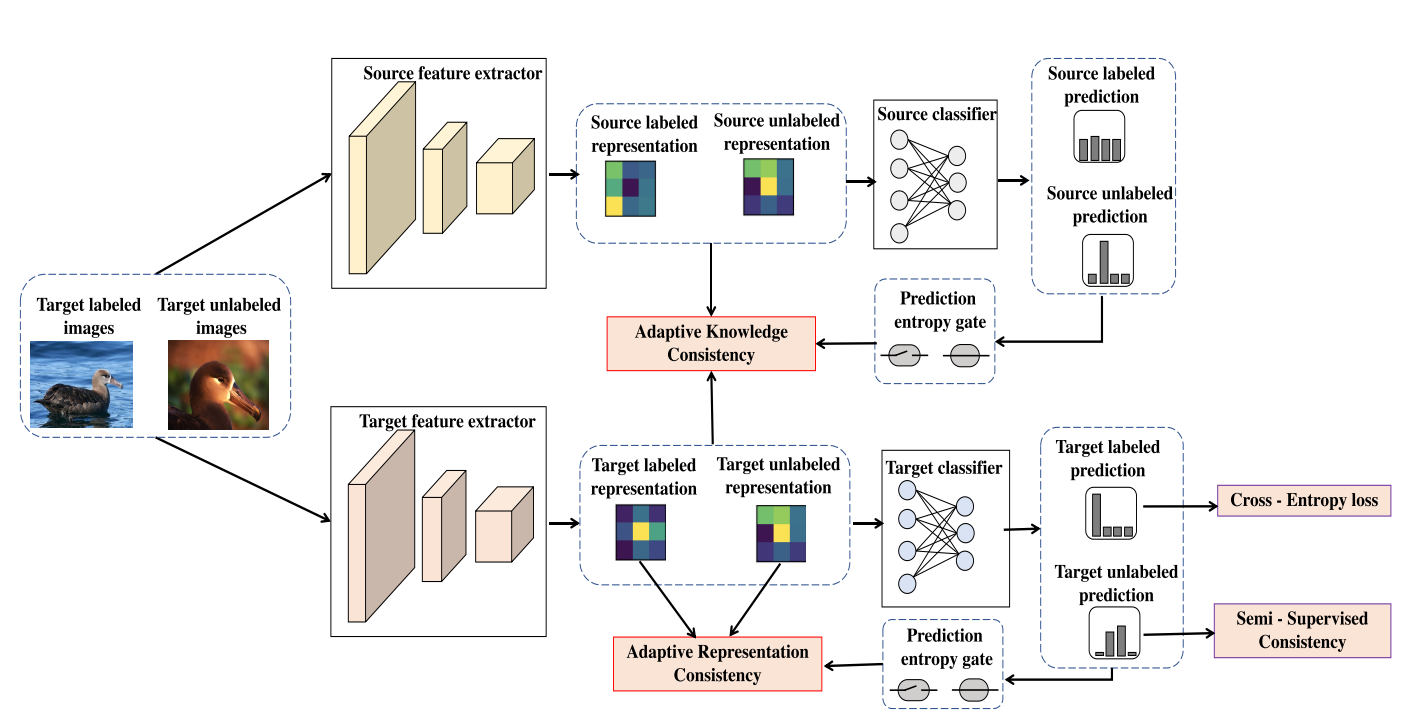
主要就是2条网络分支以及4个子模块,2个网络分支分别为 source 模型和 target 模型,source 模型就是预训练模型,在后续学习中不会变化,而 target 模型就是要学习的模型。4个子模块即图上4个框起来的1个 loss 和3个 consistency,接下来一个个进行解读。
首先明确模型的目标是什么,半监督学习希望能够将大量的无监督数据能够帮助有监督学习的过程,显然一个基本的要求就是有监督的部分首先能够学好,无监督数据作为正则项来对模型的偏好进行调整,所以整体的目标如下所示:
这里把模型分为了两部分,前半部分是特征提取器 \(F\),模型参数为 \(\theta\),后半部分是任务相关模型 \(G\),比如分类问题就可以是一层全连接层,参数为 \(\phi\)。
模型目标整体上也分为两部分,一个是有监督部分,这里以分类问题为例,可以是最小化有监督数据的 cross entropy,后半部分是一个关于特征提取器的正则项,无监督数据主要就是对这个正则项贡献。
接下来会主要对图上的4个模块进行说明。
Supervised Loss
有监督部分其实没什么太多说的内容,就是简单地将 batch 中有标签的数据计算下交叉熵(这篇论文主要针对的是分类问题)。需要说明的一点是关于模型的初始化,因为本篇论文主要的一个想法就是想将迁移学习和半监督学习结合起来,所以模型的初始化也沿用迁移学习的思路,特征提取器 \(F\) 直接就用预训练模型的特征提取器的参数。
关于任务相关模型 \(G\) 的参数并非就是随机初始化了事,而是采用了一个 Imprint 的做法,这篇论文我没有看,大概看了下代码,看起来是将有监督数据全部过一下预训练模型,然后将同一类别的输出取了一个平均,有点类似于“类别中心”的概念,然后将这个“类别中心”赋给 \(G\) 作为其初始化参数。
除此之外还需要说明的一点是,模型图中上面的那条分支(source feature extractor 和 source classifier)存的就是预训练模型参数,这条分支的参数是一直不更新的,只有下面的 Target 模型的参数会学习。
Adaptive Knowledge Consistency (AKC)
这是本文设计的第一个正则项,其思想为,源模型的F是具有泛性的(迁移学习能work的原因),为了保留这个泛性,目标模型的F提取的特征应该与源模型的特征要相同或尽可能相近,这里可以利用包括有监督无监督数据一块丢进来训练,有点类似于知识蒸馏。
简单点说,就是让 source 模型和 target 模型的特征提取器提取的特征要一致。 就像模型图上的,AKC模块的输入是两个模型提取出来的 feature。
但如果要求提取完全一致直接就让 target 模型的 \(F\) 的参数等于 source 模型的不就好了吗?其实并非要完全一致,因为预训练模型提取的特征未必就完全适用于当前这个任务,那么能否给出一个标准,什么样的特征才是适用于当前这个任务的?
这里给出了一个方案,就是当前任务的数据(这里不需要用到标签,无监督数据也可以参与进来),经过了 source 模型后,其输出的数据分布 logits 区分度很高,即某个类别的概率远高于其他类别的概率,我们就可以认为当前这个特征提取的比较好。
怎么量化这个区分度,这里就用 logits 的熵,熵越高就越接近均匀分布,这个样本的置信度不高,所以就不要要求 target 模型的特征和 source 一致,反之,如果熵小,就说明区分度可能比较高,那么就让 target 模型和 source 模型的特征一致。故而可以设计一个熵门控函数。AKC的正则项如下:
这里用带权 KL 散度来计算AKC正则项,从公式中可以看到 \(x\) 既可以是有监督数据也可以是无监督数据,权重 \(w\) 是一个关于熵的门控函数,如下:
只有当 source 模型预测结果的熵小于某个阈值时,\(w\) 才会为1。这就是模型图中 AKC 模块的3条输入来源。
Adaptive Representation Consistency (ARC)
接下来是第二个正则项,ARC的出发点是无监督数据包含了数据结构信息,应该利用上这部分信息去指导有监督数据训练,即尽可能地拉近无监督数据和有监督数据的数据分布,首先现引入描述两个分布的一个经典度量 Maximum Mean Discrepancies (MMD):
即给定两个数据集,计算出两个数据集中的数据对应的数据分布之间的差异性,本篇论文中就是要尽可能最小化有监督数据的特征集和无监督数据的特征集的 MMD。
但存在一个问题,早期由于模型还没训练好,所以无标签数据的分布是不准确的。这时候也不应该要求两个集合保持一致,否则可能就影响了有监督数据的训练。
这里采用与AKC类似的思路,只对置信度高的样本,即 target 模型如果对数据预测结果的熵够低,我们才认为这个特征值得参与进ARC的正则项计算,才进行计算MMD,这里的样本即包含有监督也包含无监督。
所以开辟两个高置信度的有监督数据特征集以及无监督数据特征集:
考虑到Mini-batch中的样本量不足以确定一个分布,这里开辟了有监督缓冲区和无监督缓冲区来存放最近选择的高置信度样本。每次都会将batch中计算的高置信度有监督和无监督样本格子添加到相应的缓冲区中,然后从缓冲区中抽取最新的 k 个构成有监督特征集以及无监督特征集,进行计算 MMD 得到 ARC 正则项:
Semi-Supervised Consistency
模型图中的最后一个模块,这里直接就是应用了别人提出的各种半监督的一致性损失,例如 MixMatch、FixMatch、Pseudo-labeling 等等,因为本论文提出的 AKC 和 ARC 只是两个正则项,是可以和别的半监督方法一起使用的,故而最终的学习目标(损失函数)为:
Results
以下是在3个分类数据集上和不同半监督方法的对比:
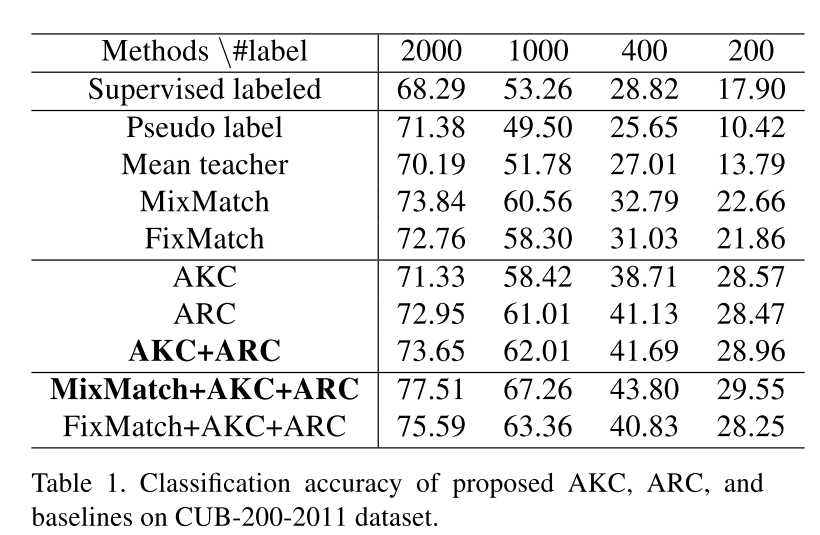
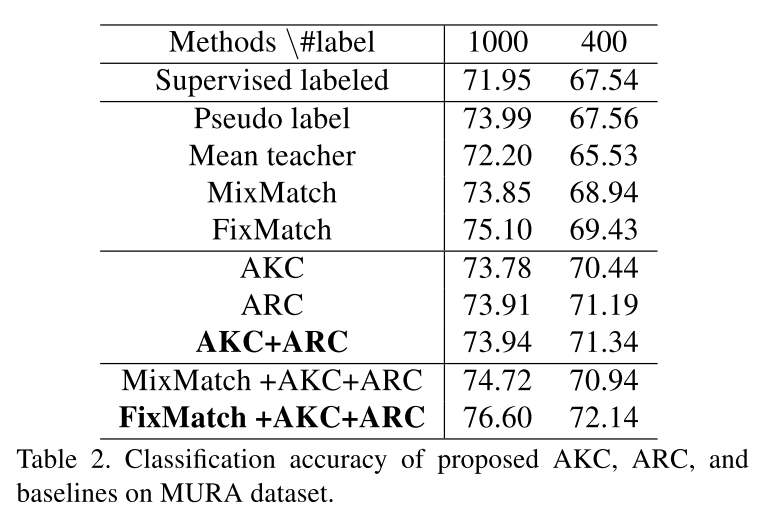
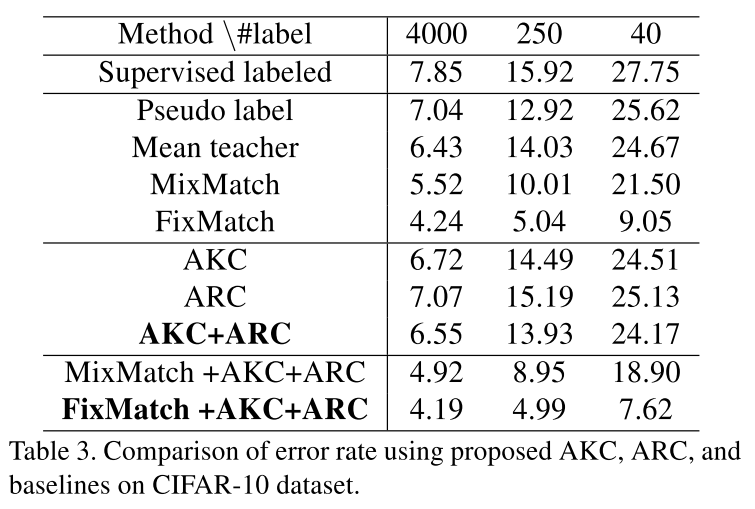
可以看到两个正则项和一些经典的半监督方法比都能旗鼓相当,而将其与这些半监督方法一块使用时,效果更是提升了不少,证明这两个正则项还是有一定效果的。

