看了很多讲解新概念新模型的文章,这些文章往往要么讲的很浅不讲原理只讲应用,让人知其然不知其所以然。要么讲的很深小白看不懂,同时总是忽略关键部分,经常性引入陌生概念让初学者疑惑,因此有了本系列文章,任何能熟练掌握线性代数知识且逻辑思维能力尚可的人都可以理解,而无需其他数模知识,涉及任何新概念都会先讲解后使用
回归分析专题
- 数据预处理
回归分析前要先进行数据预处理,主要有以下三种
- 中心化处理,使得样本均值为0

- 无量纲化处理,使得样本方差均为1
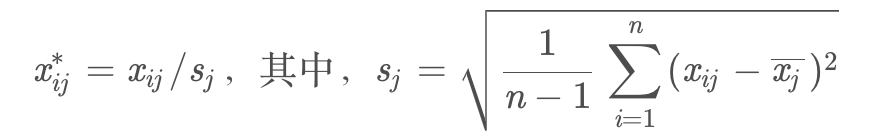
- 标准化处理,即同时进行中心化处理和无量纲化处理
二、常见回归模型(方法)
- 线性回归
线性回归使用直线在因变量y与自变量X(X是列向量,包括1~n个自变量)直线建立一种关系,即y=w*X+b+e,预测量y’=w*X+b,行向量w称为回归系数
我们的目标是使得预测量y’与真值y之间的误差足够小,那便只需要按照最小二乘估计原则,让y-y’=e的平方和足够小即可
在使用线性回归前,要从逻辑上或者示例图上大致确定自变量和因变量之间的关系是线性关系
对于回归模型y=Xw+e而言,(X是矩阵,每行是“一组自变量取值+一个常量”,有多少行便有多少组完整的数据,Y此时是列向量,每一个的元素值对于着对应行的X值,e是偏差列向量),列出正规方程组X’y=X’Xw,得到w的最小二乘估计的表达式为w=(X’X)^(-1)*X’y
要注意,只要回归系数和自变量之间是线性的就可以,自变量本身可以是由其他自变量非线性表示的,仍然算是线性回归模型。但如果回归系数和自变量之间不是线性的,那边不算是线性回归模型,如下(这事有点抽象,有待进一步阐明*)

2.逻辑回归*
当因变量属于二元型变量(如0、1型变量)时,我们就应该使用逻辑回归,换句话说,在面对类似于分类问题的回归问题时我们使用逻辑回归,因为逻辑回归本来就是一种是一种用于回归分析的分类算法
逻辑回归在广义上也属于线性回归分析模型*
最大似然估计方法(MLE)是逻辑回归的核心思想,具体内容如下
似然函数是关于权值矩阵的,似然函数的值是在给定权值的情况下,训练集中的自变量能够得到正确的因变量结果的概率,MLE就要是使得这个概率最大化。(因变量是离散的,甚至是二值的,因此不存在“多近似于正确答案算是正确”这个问题)
也即,我们选择参数的宗旨是最大化似然估计,不再是最小化偏差平方和了。
(略去部分数学推导*)
我们要进行最大化似然估计所利用的sigmoid确实也类似于神经网络模型中同名的激活函数,把偏差映射为二值的结果,1为有、0为无,逻辑回归中用到的sigmoid就是logistic函数y=1/(a+bexp(-x)),这也是这个算法得名的原因
但logistic回归并不需要真的用logistic进行映射,而只需要计算一个线性函数,其结果用logistic函数化为二值型分类结果罢了,因此逻辑回归是一种广义的线性回归分析模型
这里就必须回忆单层感知机SLP了,在此前的笔记《零基础神经网络》中我们谈到了使用了S型激活函数的非线性SLP其实也是线性模型,有趣的是,Logistic函数其实就是一种S型激活函数,而Logistic回归的实际运行过程其实也是像SLP一样是在求解一个线性回归模型。
因此,我们甚至可以大胆的说,Logistic回归就是SLP的一种,常常用于分类,之所以名为回归是因为一切分类算法都可以是做离散型回归问题
要知道,逻辑回归算法本身的提出只是基于最大似然估计原理的,却得出了一个和SLP一样的模型,这显然不是一种巧合,换句话说我们甚至可能搞反了因果,不过Logistic回归碰巧和SLP一样,而是SLP的数学基础就是Logistic回归算法推导过程中用到的最大似然估计思想!!!
因此,对逻辑回归算法的推导中我们甚至无意间进一步理解了神经网络算法的底层原理,更直观的感受到了神经网络算法为什么能行。
逻辑回归时广义的线性回归模型,但要注意的是显然逻辑回归可以处理非线性的关系,毕竟广义的线性回归模型本来就可以处理非线性的关系。
但要注意的是,如果样本数据量过少,我们更应该考虑用狭义的线性模型直接进行线性拟合,而不应该进行非线性的Logistic拟合(这里不得不探讨一个文字游戏了,那就是拟合和回归的区别,他们之间存在细小的差别,但其实并不重要,这种差别更多的是紧扣历史含义才创造出来的小差异,而并不是数学上的本质差异。因此,如果不玩文字游戏的话,我们大可以认为拟合和回归是同一个概念,散点回归和曲线拟合其实是应用于不同主语的同一件事)
3. 多项式回归
多项式回归可以达到任意大的R值,但我们要注意防止欠拟合和过拟合的出现,选择恰当的阶数,在matlab中使用[]=polyfit()即可实现
- 利用线性回归模型进行非线性回归
即对原数据集进行某种非线性变换,然后使得新数据集具有线性相关性,然后进行线性回归分析。
三.检验与评测
完成回归模型的计算后,我们评测拟合程度,评测方法如下:
R方分析
定义R方=1-SSE/SST,用于表示预测程度,
这很合理,因为SSE/SST相当于把真值中心化了之后真值平方和的偏差平方和的比值,SSE/SST越接近与0则说明线性相关性越强,越接近与1则说明预测值可能和真值毫不相关,即线性相关性极弱。
对应的,R方越接近0则相关性越弱,越接近1则线性相关性越强,该指标可以很好的反应拟合程度的好坏。
我们再引入以下概念:
总平方和SST:真值与平均值差的平方
回归平方和SSR:预测值与平均值差的平方
残差平方和SSE:真值和预测值差的平方,即残差的平方
不难证明当预测值是依据最小二乘法算出来的时候,SST=SSR+SSE,换句话说在线性回归模型中SST=SSR+SSE,非线性回归模型中则该式不成立
因此,在线性回归模型中,常利用等式SST=SSR+SSE推出R方=SSR/SST
F检验
回归自变量数量的增加总会导致R方的增加,很明显通过不同回归自变量数达成的同一R方的“含金量”是不同的,因此我们如果想对两个回归自变量数目不同的模型进行有意义的比较,我们需要对残差平方和(即方差)进行F检验
F检验在考虑到了自变量个数的情况下,负责检验自变量组是否和因变量有较强的线性相关关系,综合分析拟合程度的好坏
我们要先讲解方差分析法,才能进一步说明F检验的过程
用于试图证明某因素对结果毫无影响或者影响极大时使用方差分析法,换句话说,方差分析用于显著性检验中,检验两种情况下的结果是否有明显差异。
首先要给定1个原假设H0,H0通常为“某因素对结果毫无影响”,也可以设为等价的说法“某因素的回归系数和0没有显著性差异”,与此同时存在1个与H0相对立的备择假设H1,H0和H1有且仅有1个成立。然后进行通过一次随机仿真实验进行抽样,再然后分析结果。
若发生了小概率事件,可依据“小概率事件在一次实验中几乎不可能发生”的理由,推翻原假设,即拒绝原假设H0,从而说我们有1-Alpha 的把我说明备择假设H1成立;
反之,小概率事件并没有发生,就没有理由拒绝H0。因此我们还要确定多大概率的时间算小概率事件,即显著性水平Alpha,一般设置Alpha=0.05
只考虑一个因素A对于所关心的试验结果的影响。A 取k 个水平,在每个水平上作 ni次试验(其中i=1,2,⋯,k )试验过程中除A 外其它影响试验结果的因素都保持不变(只有随机因素存在)。我们的任务是从试验结果推断,因素A 对试验结果有无显著影响,即当A 取不同水平时试验结果有无显著差别。
记第i个水平的第j个观测值为Yij,则Yij=ai0+eij(ai0是Y第i行的平均数,即A取第i个水平时实验结果的均值,eij表示每次实验的随机误差)
eij作为随机误差,自然是相互独立的。一般还假设eij都服从均值为0方差相同的某个正态分布。
记Ybar=Y中每个元素的平均值
则记ai=ai0-Ybar,表示由不同的A水平带来的附加效应
那么Yij=Ybar+ai+eij
因此原假设A对实验结果Y毫无影响的等价表述就是a1=a2=...=ak=0
Yij并不相同,这其中有随机误差的因素,还可能有由不同水平的A所带来到底差异化因素,那么我们分别定义SS、SSA、SSE,分别用来刻画总偏差、A带来的偏差和随机因素带来的偏差
以下三个式子是很自然的定义
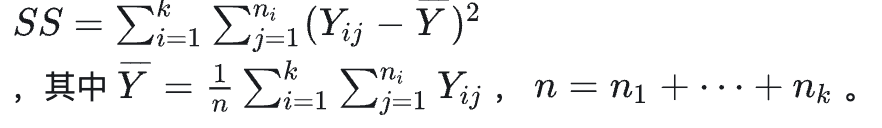
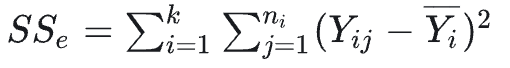
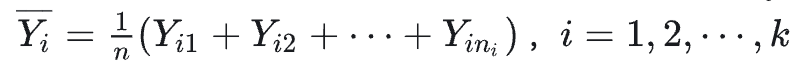
SSA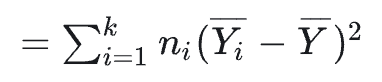
代入即可证明SS=SSE+SSA (SS其实就是前面所说的SST)
这里要引入一个概念,自由度,即样本所能提供的独立的信息的个数,一般来说,自由度等于独立变量数减掉其衍生量数。自由度的大小会影响方差分析的结果和检验的效力。
拿SSA为例,当我们已知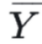 的情况下,我们只要知道k-1个
的情况下,我们只要知道k-1个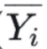 即可算出SSA,也就是说这组样本中其实只有k-1个独立数据,因此SSA的自由度应该是k-1,那么用来表示因素A带来的偏差的MSA就应该等于SSA/(k-1)而不是SSA/k,(这么做其实不是很有道理但是很好用),同样设ni的和为N,则SSE=SS-SSA=(N-1)-(k-1)=N-k,因此表示随机因素带来偏差的MSE应该等于SSE/(N-k)。还不理解就看这个:
即可算出SSA,也就是说这组样本中其实只有k-1个独立数据,因此SSA的自由度应该是k-1,那么用来表示因素A带来的偏差的MSA就应该等于SSA/(k-1)而不是SSA/k,(这么做其实不是很有道理但是很好用),同样设ni的和为N,则SSE=SS-SSA=(N-1)-(k-1)=N-k,因此表示随机因素带来偏差的MSE应该等于SSE/(N-k)。还不理解就看这个:
https://www.zhihu.com/question/20099757/answer/26318750
统计学家指出,基于前面随机偏差服从正态分布的假设和基于自由度给出表示偏差的量的行为,我们可以认为当H0成立时MSA/MSE的值(即F值)服从与F(k-1,n-k)分布,那么我们就可以用实际的MSA/MSE值和显著性水平Alpha来进行F检验了,如果MSA/MSE的值在F(k-1,n-k)中出现的概率小于Alpha,我们就拒绝接受H0,如果出现概率大于Alpha,我们则暂时没理由拒绝H0,即承认A与Y毫不相关,敏感性很低
整个过程可以用matlab的anova1函数来计算,还能自动绘图呐
F是关于似然比统计量单调的函数,因此F检验属于似然比检验。
或者我们也可以使用调整后的R方来进行此类比较,设变量数为p,样本量为n,则调整后R方的计算公式为:
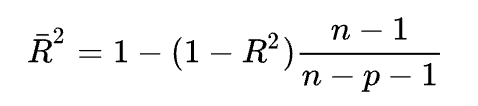
这个量的引入其实就是为了体现统计学家的一个主张,即在回归建模时,采用尽可能少的自变量,不要盲目地追求复判定系数R方的提高,如果引入一个新变量,使得R方有所提高,但调整后R方几乎没提高则不必增加此变量。
注意到了吧,调整后R方的计算公式用到了和F检验一样的自由度思想,因此两种方法使用一种即可,调整后R方完美兼顾了回归自变量数目和拟合程度(R方)两个需要考虑的因素
这里需要引入一个matlab中常见的概念,p值,指“在原假设正确的情况下,出现现状或比现状更差的情况的概率”,通常p值足够小则说明原假设错误,p值过大则说明原假设正确。
在这里,当前模型的p值足够小则说明当前模型通过F检验,说明综合拟合程度足够好
t检验
t检验负责检验哪些回归自变量没有有存在的必要,换句话说t检验单独检验某一自变量是否和因变量有显著的相关关系
很显然,t检验是用来单独分析每个自变量的,分别检验各自变量是否有存在的意义
指定自变量的p值过大则接受原假设,认为该回归变量的均值与0没有显著性差异,也即该自变量和因变量没有显著相关关系,该变量不应该存在,未通过t检验;p值足够小则说明通过检验,该变量可以存在。
总结
概括一下,F检验和t检验其实都用到了方差分析法,只不过F检验是对整个模型而言的,检验模型整体的拟合情况,而t检验是单独针对每一个自变量而言的,检验自变量是否有存在的必要。
调整后R值则利用了和F检验类似的核心思想而定义出来的统计量,可以比F检验更简便的反映出数据拟合情况
四、解决缺陷
多元变量的回归模型就算R值过高也未必能实现特别好的预测,因为如果自变量过多,会导致过拟合,使得模型参数关于数据集高度敏感。
若R方和调整后R方相差过大,说明考虑的变量过多(很明显,看调整后R方的计算公式即可发现这一点),模型可能具有多重共线性缺陷,我们应该考虑减少或调整变量
如果自变量过少,则会导致欠拟合,即模型可能有异方差性缺陷,我们应该考虑引入交互项从而考虑到所有因素。
因此,对于多元变量的回归模型而言,不论是哪种回归模型都可能有较大缺陷,我们要会分析缺陷、解决缺陷
检验模型是否有缺陷有多种办法
我们可以简单的删除或增加一个变量,然后再做回归分析,如果删除一个变量后回归系数极其敏感的大幅度变化,则说明此时的估计系数不可信,要思考回归模型有什么缺陷。
也可以系统性地进行各种检验,发现缺陷并解决缺陷,直到确保没有缺陷为止。
缺陷分类
多元线性回归的常见缺陷有:多重共线性,自相关性和异方差性
--多重共线性
----定义
自变量之间具有较大的线性相关性则成当前模型具有多重共线性
----造成缺陷的原因
对于线性回归模型y=Xw+e而言,w的最小二乘估计的表达式为w=(X’X)^(-1)*X’y,当X线性相关性较大时,X和X’行列式极小,X’X更是行列式极小,逆矩阵等于伴随矩阵除以行列式,因此行列式极小时逆矩阵的计算会有极大误差。
以上是一个比较狭义的解释,无法解释为什么逻辑回归中也会有多重共线性问题,因此有了第二种解释:
当存在多重共线性的时候,按照自变量的线性关系对回归系数做线性变换,误差平方和却可能几乎不变,也就是说回归系数的剧烈变化无法体现在误差平方和上,误差平方和已经不适合用来表示模型拟合的好坏程度了,而我们计算模型时却仅仅依照误差平方和最小的原则,显然会造成较大误差。
在逻辑回归中,似然函数值的计算公式中自变量也是线性的,因此如果按照线性关系对回归系数做较大线性变换的同时也可以使似然函数值变化不大,则使得似然函数值不再适合用于体现模型你和成都,而MLE的原则恰恰仅仅是使得似然函数值最大,因此会造成较大误差,因此逻辑回归模型也存在多重共线性问题
----分析方法
我们要先用皮尔逊相关系数(在线性回归分析中,皮尔逊相关系数r的平方就是拟合优度或者说决定系数R方,即r(皮尔逊相关系数)=R,r方=R方)分析问题中的连续型自变量之间是否有多重共线性的问题,如果两自变量的皮尔逊相关系数大于0.8则认为存在多重共线性,
对于离散型自变量而言则辅以其他方式来分析是否存在多重共线性问题
我们还可以进行t检验,如果t检验不显著,则说明当前模型可能存在多重共线性
最正规的检验方法是分析方差膨胀因子VIF的值,
若有自变量A、B、C,则ABC分别有一个VIF值,把A作为因变量,其他原自变量均作为自变量做一次回归分析,计算新回归分心的R方,VIF_A就等于1/(1-R方),通常VIF_A值越接近1则说明A越独立,VIF_A大于5则说明A和其他变量有弱线性相关性,VIF_A大于10则可以直接认定当前模型存在多重共线性
(有的文章还会提到利用容忍度Tol来判断多重共线性,容忍度其实就是VIF的倒数,因此既然已经考虑了VIF,就没有任何必要还要考虑Tol了)
----解决方法
1.我们往往使用向前选择法,向后剔除法和逐步筛选法来选择重要的自变量,高度相关的自变量中只保留一个,其余皆删去,从而降低变量元数,
向前选择法
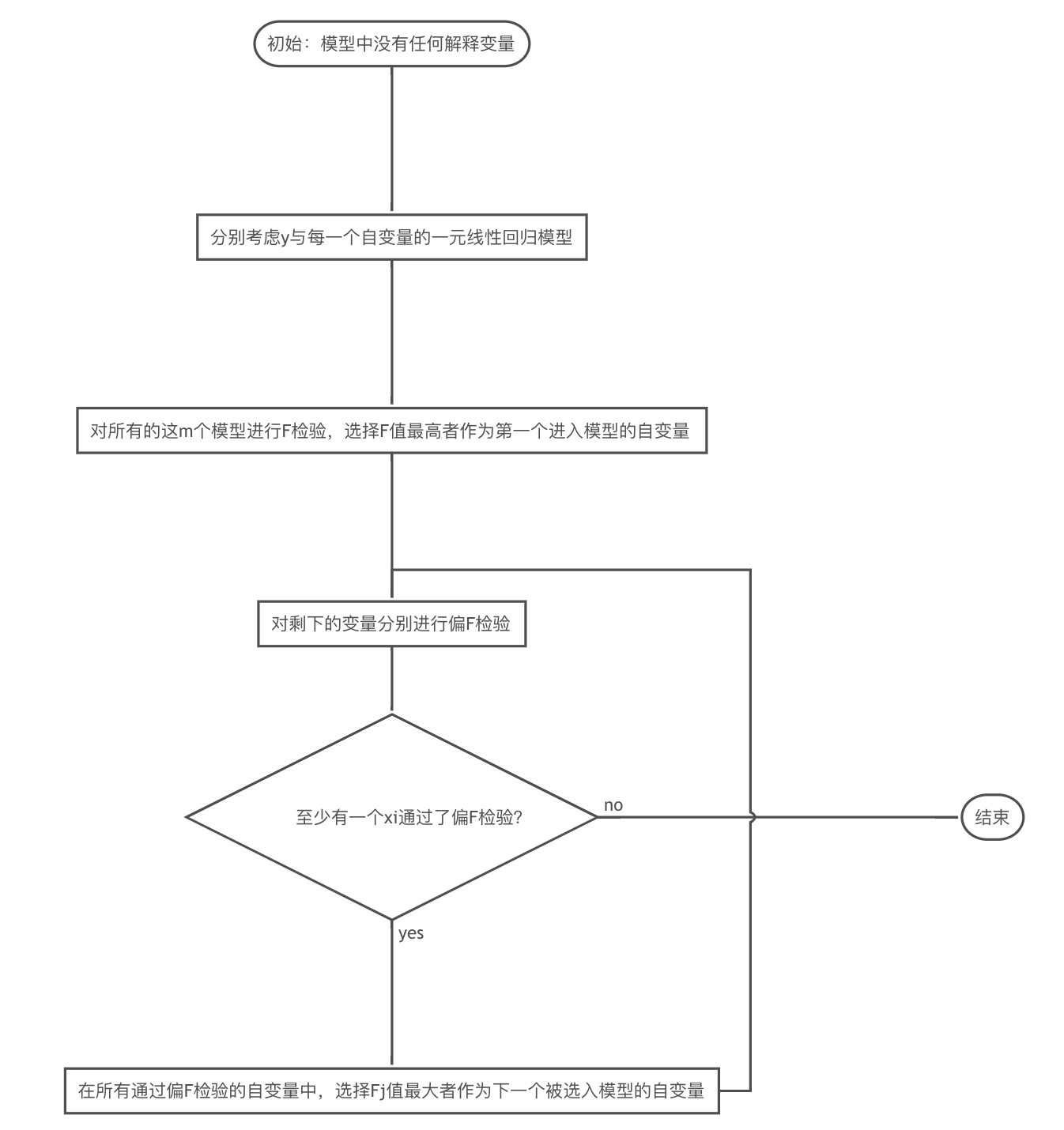
一旦某个自变量被选入模型,它就永远留在模型中。然鹅,随着其他变量的引入,由于变量之间相互传递的相关关系,一些先进入模型的变量的解释作用可能会变得不再显著。
向后剔除法
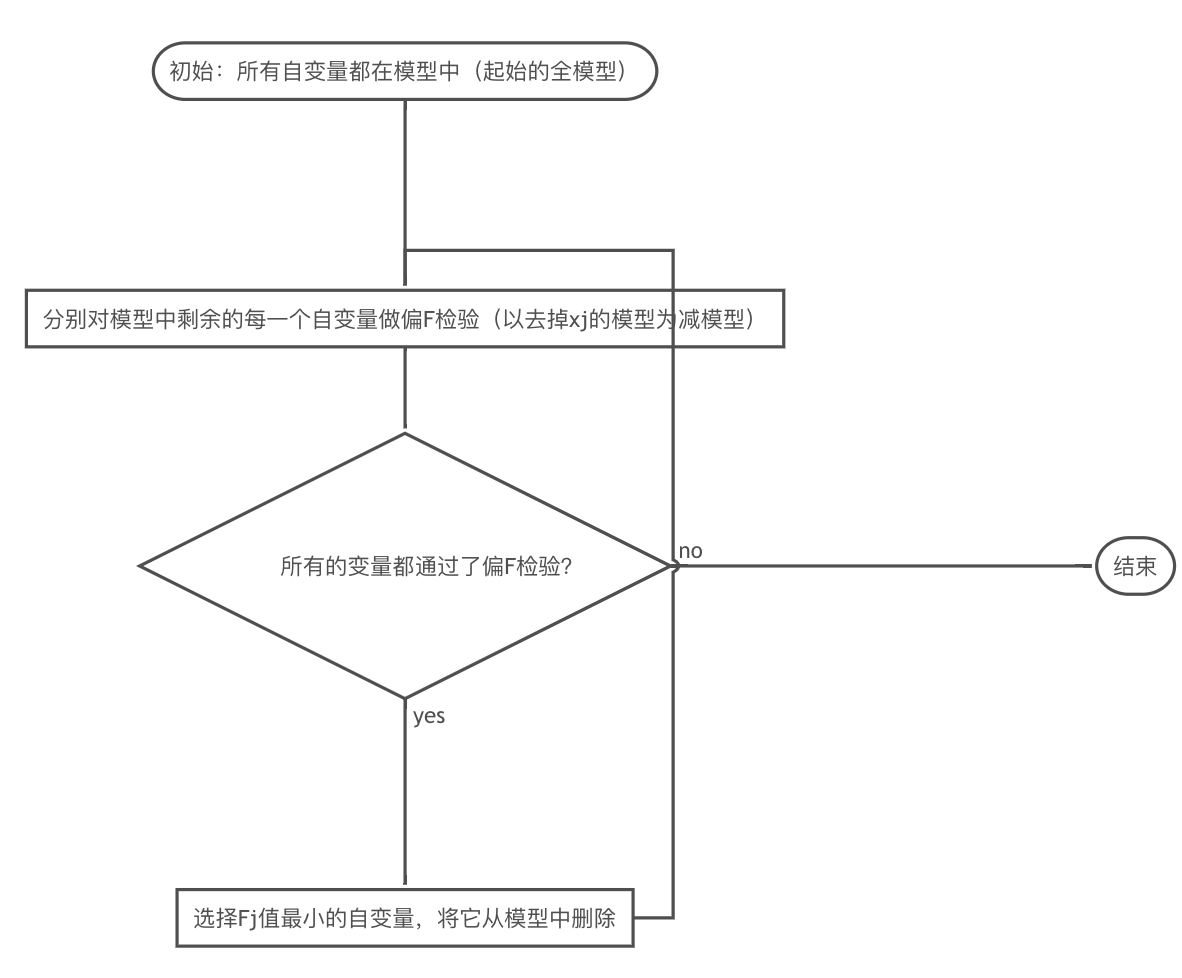
缺点:一旦某个自变量被删除后,它就永远被排斥在模型之外。但是,随着其它变量的被删除,它对 y 的解释作用也可能会显著起来。
因此我们更常使用逐步回归法,这种方法综合了向前选择和向后剔除,采用了边退边进的方法,具体如下:
对于模型外部的变量,只要它还可以提供显著的解释信息,就可以再次进入模型
对于已在内部的变量,只要他的存在无意义,即偏F检验(偏F检验似乎等价于t检验)不能通过,则还可能从模型中删除
当然,为了防止变量过度次数地反复进出,一般定义一个选入变量的偏F检验最小临界值F进,还要定义一个删除变量的偏F检验最大临界值F出,要注意F进>F出。通常定义为0.1和0.05
- 进行特征合并,将相关变脸线性组合在一起处理(即先对线性相关的自变量进行线性回归分析,再把回归得到的因变量当做自变量)
3.采用有偏估计法,比如通过主成分分析法等数据降维方法进行特征降维,或者利用偏最小二乘法*、岭回归法*等等
4. 引入L1和L2正则化*
- 差分法:将原模型变换为差分模型*
--异方差性
----定义
随机误差项理应具有相同的方差,如果随机误差项具有不同的方差,那么就称当前模型具有异方差性
----原因
我们的模型中可能遗漏了部分解释变量,使得这部分会造成定向影响但并未被考虑在内的因素被归入了随机误差项,从而使得异方差性产生
因变量和自变量之间如果具有非线性关系,在线性回归模型中被简单处理成了线性关系,那么此时就也会产生异方差性
在随时间变化的数据集中,随着时间的推移,抽样技术或搜集方法得到改进,使得测量误差逐渐减少,或者还有可能随着时间的推移误差逐步积累,总之肯呢个产生异方差性
----影响
会使得我们低估回归系数的方差,使得高估回归系数的t检验值,使得原本不显著的回归系数被误认为是显著的回归系数,换句话说异方差性的存在会使得参数的显著性检验时效
----检验方法
最方便的方法是残差图分析法,以e为纵坐标,以各自变量为因变量分别绘制残差图,然后根据残差图直接分析是否存在异方差问题(鉴别方法如下)
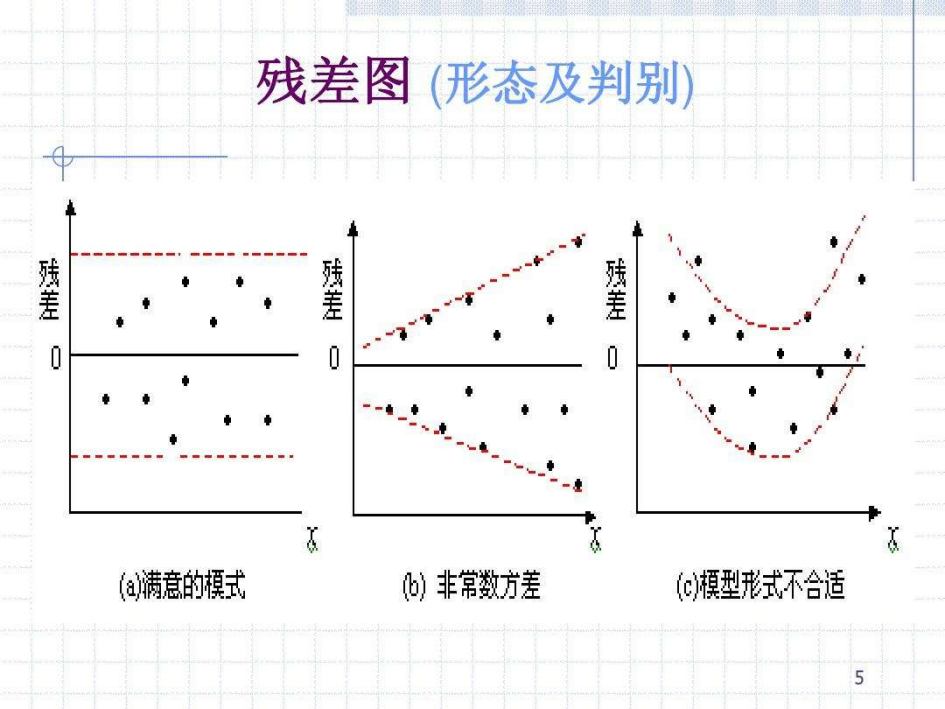
----解决方案
1我们设法检验偏差量e的方差与各自变量的相关性,然后利用加权最小二乘估计法重新求解模型
2. 引入交互项,如不仅将x1和x2作为自变量,还把x1方,x2方,x1x2作为自变量等等
--自相关性*
----定义
若误差项的取值受自身影响,则称当前模型具有自相关性
----影响
会使得误差项具有明显的正相关
----检验方法
利用DW检验*或迭代法*
----解决办法
差分变换与广义最小二乘法*
上述文章中的*内容也暂未搞清楚,有待进一步的研究,自相关性和多重共线性的详细区分也没太搞清楚,过段时间再说
例题:2021B、国赛2023C、美赛2023C
以国赛2021B的第二题为例,下面是写的代码
```
%导入
% 设置导入选项并导入数据
opts2 = spreadsheetImportOptions("NumVariables", 10);
% 指定工作表和范围
opts2.Sheet = "性能数据表";
opts2.DataRange = "A2:J115";
% 指定列名称和类型
opts2.VariableNames = ["x_______", "x_____", "x__", "x________", "x________1", "C4________", "x________2", "x___4_12_________", "x_________________", "x____________"];
opts2.VariableTypes = ["char", "char", "double", "double", "double", "double", "double", "double", "double", "double"];
% 指定变量属性
opts2 = setvaropts(opts2, ["x_______", "x_____"], "WhitespaceRule", "preserve");
opts2 = setvaropts(opts2, ["x_______", "x_____"], "EmptyFieldRule", "auto");
% 导入数据
Maintable = readtable("/Users/Kai/Desktop/B 2/附件1.xlsx", opts2, "UseExcel", false);
% 转换为输出类型
Maintable = table2cell(Maintable);
numIdx = cellfun(@(x) ~isnan(str2double(x)), Maintable);
Maintable(numIdx) = cellfun(@(x) {str2double(x)}, Maintable(numIdx));
% 清除临时变量
clear numIdx
% 清除临时变量
clear opts2
% 显示结果
%Maintable
index=["催化剂编号类别","Co量","HAP量","Co负载量","乙醇浓度","温度","乙醇转化率(%)", ...
"乙烯选择性(%)","C4烯烃选择性(%)","乙醛选择性(%)", "碳数为4-12脂肪醇选择性(%)", ...
"甲基苯甲醛和甲基苯甲醇选择性(%)","其他生成物的选择性(%)"];
cata=[1 200 200 1 1.68; ...
1 200 200 2 1.68; ...
1 200 200 1 0.9; ...
1 200 200 0.5 1.68; ...
1 200 200 2 0.3; ...
1 200 200 5 1.68; ...
1 50 50 1 0.3; ...
1 50 50 1 0.9; ...
1 50 50 1 2.1; ...
1 50 50 5 2.1; ...
1 50 90 1 1.68; ...
1 50 50 1 1.68; ...
1 67 33 1 1.68; ...
1 33 67 1 1.68; ...
2 50 50 1 1.68; ...
2 100 100 1 1.68; ...
2 10 10 1 1.68; ...
2 25 25 1 1.68; ...
2 50 50 1 2.1; ...
2 75 75 1 1.68; ...
2 100 100 1 0.9; ...
];
p=1;
MainTable=[];
for i=1:21
lp=p;
p=p+1;
while(p<=114&&isempty(Maintable{p,2}))
p=p+1;
end
B=zeros(p-lp,5+8);
for j=lp:p-1
for k=1:5
B(j-lp+1,k)=cata(i,k);
end
end
for j=lp:p-1
for k=3:10
B(j-lp+1,k+3)=Maintable{j,k};
end
end
MainTable=[MainTable;B];
end
%目前Table 依次是装料方式、Co量、HAP量、Co负载量、乙醇浓度、温度、乙醇转化率、各物质选择性
%导入end
%针对第二题进行数据初步处理
%要分析的是催化剂组合和温度对乙醇转化率和C4烯烃选择性的影响,因此可以其他物质的选择性。同时选择相同的装料方式和乙醇浓度
%先去除其他物质转化率
Table=MainTable;
Table(:,8)=[];
Table(:,9)=[];
Table(:,9)=[];
Table(:,9)=[];
Table(:,9)=[];
display(Table);
%再分析乙醇浓度
c_C2H5OH=Table(:,5);
uc=unique(c_C2H5OH);
t=size(uc);
counts=zeros(size(uc));
for i=1:t(1)
for j=1:114
if(c_C2H5OH(j)==uc(i))
counts(i)=counts(i)+1;
end
end
end
display(uc);
display(counts);
proportion=counts/114;
display(proportion);
%发现基本都是1.68的,有10%的0.3,15%的0.9,15的%2.1
%因此只分析1.68的
anac=uc(3);
for i=114:-1:1
if(Table(i,5)~=anac)
Table(i,:)=[];
end
end
Table(:,5)=[];
display(Table);
%最后再根据装料方式分为两个表
TableA=Table(Table(:,1)==1,2:7);
TableB=Table(Table(:,1)==2,2:7);
display(TableA);display(TableB);
%数据初步处理完毕
%对A展开拟合分析
%数据的进一步处理
data=TableA;
%引入C4转化率,装料比
data=[data data(:,5).*data(:,6)];
data(:,2)=data(:,1)./data(:,2);
dataindex=["Co量","装料比","Co负载量","温度","乙醇转化率(%)","C4烯烃选择性(%)","C4烯烃转化率"];
display(dataindex);
display(data);
%尝试对乙醇转化率绘图
hold on;
scatter(data(:,5),data(:,1),"filled","LineWidth",3);
scatter(data(:,5),data(:,2),"filled","LineWidth",3);
scatter(data(:,5),data(:,3),"filled","LineWidth",3);
scatter(data(:,5),data(:,4),"filled","LineWidth",3);
legend(dataindex(1:4));
%尝试绘图完毕,未标准化处理的数据果然难以观察
%数据标准化,使得均值为0方差为1
undealed_data=data;
m=zeros(1,7);s=m;
for i=1:7
anav=data(:,i);
m(i)=mean(anav);
anav=anav-m(i);
s(i)=std(anav);
anav=anav/s(i);
data(:,i)=anav;
end
%data(:,i)*s(i)+m(i)=undealed_data
display (data);
%进一步绘图
clf
hold on;
scatter(data(:,5),data(:,1),"filled","LineWidth",3);
scatter(data(:,5),data(:,2),"filled","LineWidth",3);
scatter(data(:,5),data(:,3),"filled","LineWidth",3);
scatter(data(:,5),data(:,4),"filled","LineWidth",3);
legend(dataindex(1:4));
clf
hold on;
scatter(data(:,6),data(:,1),"filled","LineWidth",3);
scatter(data(:,6),data(:,2),"filled","LineWidth",3);
scatter(data(:,6),data(:,3),"filled","LineWidth",3);
scatter(data(:,6),data(:,4),"filled","LineWidth",3);
legend(dataindex(1:4));
clf
hold on;
scatter(data(:,7),data(:,1),"filled","LineWidth",3);
scatter(data(:,7),data(:,2),"filled","LineWidth",3);
scatter(data(:,7),data(:,3),"filled","LineWidth",3);
scatter(data(:,7),data(:,4),"filled","LineWidth",3);
legend(dataindex(1:4));
clf
%进一步绘图完毕
%观察图像,初步发现:
% 更大的Co量,更小的Co负载量,更高的温度有利于提高乙醇转化率
% 更小的Co量,更小的Co负载量,更小的温度有利于提高C4选择性
% 更大的Co量,更小的Co负载量,更高的温度有利于提高C4转化率
X=data(:,1:4);
x1=X(:,1);
x2=X(:,2);
x3=X(:,3)
x4=X(:,4);
Ys=data(:,5:7);
y1=Ys(:,1);
y2=Ys(:,2);
y3=Ys(:,3);
%数据的进一步处理完毕
%狭义线性拟合
%stepwise(X,y1);
% 逐步回归发现只有x1,x4通过p检验,说明有显著相关性;x2,x3未通过p检验,说明均无显著相关性
% R方0.796062,调整后R方0.785329,F检验的p值小于十的负十三次方,通过检验。
% 即Y1=0.446046*x1+0.803004*x4 ,乙醇转化率和Co量、温度正相关
%stepwise(X,y2);
% x1 x3 x4通过p检验,R方=0.60相关性一般
% Y2=0.656311*x1-0.336374*x2+0.525877*x4,C4选择性和Co量、温度正相关,和装料比负相关
%stepwise(X,y3);
%x1 x4通过p检验,R方=0.65相关性一般
%Y3=0.442635*x1+0.716395*x4,C4转化率和Co量、温度正相关
%狭义线性回归完毕
%考虑x1方,x2方,x3方,x4方,x1x2,x1x3 x1x4 x2x3 x2x4 x3x4
moreX=[X,x1.*x1,x2.*x2,x3.*x3,x4.*x4,x1.*x2,x1.*x3,x1.*x4,x2.*x3,x2.*x4,x3.*x4]
%stepwise(moreX,y1);
%x1 x4 x1^2 x4^2 x1*x4通过了t检验,回归系数皆为正,即乙醇转化率与Co量、温度正相关(HTP有着不太可信的负相关性)
% 模型R方=0.9048,调整后R方=0.891287,通过F检验,相关性非常强
%stepwise(moreX,y2);
%只有x1 x4 x3^2通过了t检验,x3本身未通过t检验,说明x3和y2的关系更接近于二次而非线性。
%x1 x4回归系数为正,x3^2回归系数为负,
%即C4选择性与Co量、温度正相关,与负载量的平方负相关
%y3关于x3转折点在0,而-0.7<x3<2.5,因此可以认为与负载量先正相关后负相关
%模型R方=0.65,调整后R方=0.52,通过F检验
%stepwise(moreX,y3);
%x1 x3 x4 x3^2 x4^2 x1x4通过了t检验,x3^2系数为负,其余为正,
%说明C4转化率与Co量、负载量、温度正相关,与负载量的平方负相关
%y3=w*[x1 x4 x4^2 x1x4]+0.36872*x3-0.255898*x3^2
%y3关于x3的转折点在0.36872/(2*0.255898)=0.72,而-0.7<x3<2.5,因此可以认为与负载量先正相关后负相关
%模型R方0.9024,调整后R方0.885213,通过F检验,相关性非常强
%拟合分析完毕
%x1~x4:"Co量","装料比(Co/HAP)","Co负载量(Co/SiO2)","温度",
muchmoreX=[moreX moreX(:,5:14).*moreX(:,5:14) exp(X)];
% 1~4 x1~x4;5~8 x1方~x4方;9~14 x1x2 x1x3 x1x4 x2x3 x2x4 x3x4;
% 15~18x1^4~x4^4;19~24 (x1x2 x1x3 x1x4 x2x3 x2x4 x3x4)^2;25~28 exp(x1~x4)
% stepwise(muchmoreX,y1);
% R方=0.905534 调整后R方=0.895938 通过F检验,模型相关性极强
% x4 x11 x21 x25通过t检验 回归系数均为正
% y1=0.77*x4+0.31*x1x4+0.19*x1x1x4x4+0.44*exp(x1)
% 可以认为y1和x4正相关,和x1指数级正相关,和x1x4线性相关且平方级正相关
% 乙醇转化率和温度、Co量强正相关
% stepwise(muchmoreX,y2);
% R方=0.93759 调整后R方0.919471 通过F检验 模型相关性极强
% x1 x4 x9 x12 x15 x17 x20 x24 x27通过t检验 9 20 27为负,其余为正
% y2=1.03*x1+0.54*x4-3.46*x1x2+6.54*x2x3+1.73*x1^4+1.47*x4^4
% -7.01*x1x1x3x3+0.06*x3x3x4x4-1.87*exp(x3)
% x2x3和x3x4^2的t检验值不算太大,且x3x4回归系数极小,可以忽略,忽略后R方为0.90左右,故舍去x3 x4
% 可以认为y2和x1、x4线性级四次方级正相关,和x1x2负相关 和x1x1x3x3强负相关 和x3指数级负相关
% C4选择性和Co量、温度强正相关、和HAP量正相关 和SiO2量正相关、和装料比负载量基本不相关
% stepwise(muchmoreX,y3);
% R方=0.9062,调整后R方=0.889718 通过F检验,相关性极强
% x4 x7 x8 x10 x11 x25通过t检验 x7为负,其余为正
% y3=0.68*x4-0.26*x3^2+0.31*x4^2+0.38*x1x3+0.47*x1x4+0.61*exp(x1)
% =0.68*x4+0.31*x4^2-0.26*x3^2+0.38*x1x3+0.47*x1x4+0.61*exp(x1)
% 根据x3正向负向的t检验值比较,我们可以认为y3和x3负相关,和x4线性平方四次方级正相关,和x1指数级正相关,和x1x4强线性正相关
% C4转化率和负载量微弱负相关即和SiO2微弱正相关,和Co量、温度强正相关
%验证一下引入HAP与SiO2后Ys的变化
endX=[moreX moreX(:,5:14).*moreX(:,5:14) exp(X) x1./x2 x1./x2];
%stepwise(endX,y1);
%引入HAP与SiO2后对y1无影响,未通过t检验,但却不知为什么却略微拉低了R方
%stepwise(endX,y2);
%y2和HAP有微弱正相关关系,对R方几乎无影响
%stepwise(endX,y3)
%引入HAP与SiO2后对y3毫无影响,未通过t检验,R方几乎不变
%总结,更高的温度和Co量可以提高乙醇转化率和C4转化率,更高的SiO2可以提高C4选择性和转化率。更高的HAP可以提高C4选择性但几乎不影响最终的C4转化率
%因此,更高的温度和Co量有利于C4转化率(即C4收率),装料比无所谓,负载量低一些更好
display(X)
myy3=-1.08875+0.68*x4+0.31*x4.*x4-0.26*x3.*x3+0.38*x1.*x3+0.47*x1.*x4+0.61*exp(x1)
%没明白为什么换成scatter(xno,dealede3);后就会有一个超级突出的异常点
%y3=0.68*x4+0.31*x4^2-0.26*x3^2+0.38*x1x3+0.47*x1x4+0.61*exp(x1)
Co0=(0-m(1))/s(1)
x30=(0-m(3))/s(3)
T200=(200-m(4))/s(4)
%q3-1: -1.66<x1<1.5 -1.1<x3<3 -2.2<x4<2
T350=(350-m(4))/s(4)
%q3-2: -1.66<x1<1.5 -1.1<x3<3 -2.2<x4<0.7631
%同理对B进行拟合分析
%拟合分析完毕
%反过头来分析其他乙醇浓度所能得到的结果
%分析完毕
function answer=funy3(x1,x3,x4)
answer=-(0.68*x4+0.31*x4.*x4-0.26*x3.*x3+0.38*x1.*x3+0.47*x1.*x4+0.61*exp(x1))
end
```
针对问题3,还有:
```
%y3=0.68*x4+0.31*x4^2-0.26*x3^2+0.38*x1x3+0.47*x1x4+0.61*exp(x1)
%q3-1: -1.66<x1<1.5 -1.1<x3<3 -2.2<x4<2
%q3-2: -1.66<x1<1.5 -1.1<x3<3 -2.2<x4<0.7631
s=[76.3835 0.4353 1.3665 50.3418 24.0286 14.7002 895.3544];
m=[126.8293 1.0096 1.5366 311.5854 23.6681 18.0254 617.7497];
ans1=fmincon(funYp,[0 0 0],[eye(3);-eye(3)],[0.9579 3.0 1.7563 1.66 1.1 2.2])
((-funY(ans1))*s(7)+m(7))/100
ans1beforedealed=ans1.*s([1,3,4])+m([1,3,4])
%Co 241.4045 装料比 3.0345 温度 400 ->63.79%
%Co 200mg 装料比 2.49 温度 400 ->47.88%
ans2=fmincon(funYp,[0 0 0],[eye(3);-eye(3)],[0.9579 3.0 0.7631 1.66 1.1 2.2])
((-funY(ans2))*s(7)+m(7))/100
ans2beforedealed=ans2.*s([1,3,4])+m([1,3,4])
%Co 241.4mg 装料比 3.0345 温度350->44.53%
%Co 200mg 装料比 2.49 温度350 ->30.89%
```
问题2中还没分析VIF值(但考虑到反应条件之间确实从逻辑上彼此完全独立,因此没必要分析),没检验异误差性,未考虑用Logistic函数拟合等等,换句话说模型还有改进空间
问题2建模时把AB分开考虑倒没什么,最后得出两组回归函数,还可以比较一下哪种更好。但还大可以把乙醇浓度也纳入回归变量,虽然没要求分析乙醇浓度,但不考虑乙醇浓度便少了40%的数据,因为如果乙醇用作分类而不是回归变量的话会把本就分为两类的数据进一步分为八类...而且不利于第三问的求解。
问题3我分析出Co量和结果强正相关后,得出结果在允许20%(40mg)的Co的情况下得出了63.79%和44.53%,应该算是比较优秀的结果了,
还得出就算是不允许使用比题目中更优秀的条件,也得出了47.88%和30.89%这个中规中矩的结果,毕竟原本1.68的乙醇浓度的实验数据中最大的只有31.11%(也是在400度下达成的,但我的负载量为2.49不大不小正合适,所以实现了31->48的提升)
所以在这部分的回归分析做的不错,就是可惜没考虑到乙醇浓度了。
结论 在固定乙醇浓度1.68ml/min,最允许400度的情况下最优解为200mg 2.49wt%Co/SiO2-200mgHAP-乙醇浓度1.68ml/min,可实现47.88%的收率
为什么不考虑450呢?因为我这个模型所用的数据全都是400及以下的温度,如果强行把温度上线提高到450就会得到下面这个优秀到简直荒谬的结果,显然是过拟合了
%Co 200mg 装料比 2.49 温度 450 ->70.35%
那为什么没把450的温度纳入考虑范围呢?是因为那部分温度的乙醇浓度全都不是1.68,也就是说恰恰在舍弃的那40%数据中,这就更体现了不该舍去那部分乙醇了,把乙醇纳入考虑就好了
然而,我发现以上全部是计算错误未考虑到截距的结果...这还是在我做画残差图、画回归曲线拟合图的时候发现的....哎..
真实情况是:
如果允许多用20%的Co,那么450度是不可信的78.24%,400度是可信的54%,350是34.78%表现不错
如果Co至多可以使用200mg,那么450度是不可信的60.61%,400度是可信的38.13%,350度是21.14%,考虑到400度原本可信的是31.11%,那说明在不把其他乙醇浓度纳入在内因而温度最高只能选择400度的情况下这个结果不能算好但也不差了,算是中规中矩,就是21.14%这个数小丑了些了。
罢了,反正这些足够证明只要把其他乙醇纳入考虑在内就能得到优秀模型,那便不继续浪费时间了,第三题就到这里为止
然后便要开始灵敏度分析了,那这到底是什么意思呢?灵敏度分析就是“该灵敏的就灵敏反应,不该灵敏的完全不受其影响”,就是说,该有关的指标在数据集中如果改变(比如-5%~5%的上下偏差),那么该指标对应回归系数也应该有一个不算小的线性变化,如果无关的指标做出改变,那么其他回归系数就不应该有任何显著变化。就是这么简单,理解了含义自然就会做灵敏度分析了。
至于第四题,则两个主要思路,一是把我们预测出来的1~2个最优解进行测试,看看到底优不优秀。然后再根据均匀实验设计法的思想,即正交实验的思想,补全该做但没做的实验,换句话说根据实验科学本身的知识来补全即可。总之不复杂,这题便是完成了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具