遗传算法学习笔记【零基础系列】
用简单的例子引入算法
对于一个特定的问题而言,我们用x来表示解,x的所有可能取值便构成了解空间,肯呢个取值的个数便是解空间的大小。已知解空间的大小我们便要用一套编码来表示解空间中的一个特定的解。
以求 f(x) = x + 10sin(5x) + 7cos(4x), x∈[0,9] 的最大值这道题为例。
假如设定求解的精度为小数点后4位,那么就可以将x的解空间划分为 (9-0)×(1e+4)=90000个等分,我们大可以直接用实数编码,但这会导致常常收敛于局部最优解(关于这一点后续会有更多介绍,这里半懂不懂也可以),因此我们要用二进制进行编码。
2^16<90000<2^17,因此用17位二进制来编码,一个二进制数字便是一个染色体chromosome,一开始的二进制码是随机生成的,无需编码过程,但最后算出来的结果总得转化为编码所对应的解,也就是解码,解码规则不难想到,如下x = 0 + decimal(chromosome)×(9-0)/(2^17-1)。
显然甚至不难想到此类问题的通用解码公式:
f(x), x∈[lower_bound, upper_bound]
x = lower_bound + decimal(chromosome)×(upper_bound-lower_bound)/(2^chromosome_size-1)
编码方式还有很多种,除了直接用二进制表示的二进制法以外,还有格雷编码法、浮点数编码法等等,但最终结果都是形成一个二进制的数字。
编码被称为位串,是遗传算法中极常用个体表现形式,二进制编码的每个位就是一个基因,编码本身就是基因型,编码解码后的数据就是表现型,环境选择是针对表型进行的,也就是说适应度函数的输入参数应该是表现型
基因本身还具有权,不同基因的重要度不同,衡量是否优秀时要靠谱基因的权重,基因的权重称作特征值。
一个染色体便描述了一个个体的性状,我们初始随机生成的一些染色体对应的一群个体便构成了一个种群,
我们模拟选择压力,就要评价一个个体好不好,就需要一个评价环境适应度的函数,称为适应度函数,在本题中f(x)就是适应度函数,适应度函数值越大,对应个体性状就越优良。
现在,已经有了一个种群和环境压力,如何能让种群变得更加优秀呢?遗传与变异。
只要我们规定遗传与变异的方式,那么进化就会自然而然的发生,没有任何人规定种群要进化,但进化就是会自然而言的发生。
首先,我们要选择(selection),依照适应度函数选择多对个体,这些个体获得活下去的机会,作为父母繁衍后代。具体选择方式可以采用轮盘赌法,每个人被选中的概率何其适应度函数值的大小成正比,也可以直接采用精英机制,直接选择最优的一批个体。
然后要交叉(crossover),即交配。父母依据交叉概率(cross_rate,即得到繁殖机会的个体数占种群个体总数的比例)按照某种方式交换其部分基因产生子女,具体交换方式可以是单点交叉法,也可以是其他交叉方法。
最后要变异,产生的子代染色体要按照变异概率(mutate_rate,即娃变异的概率)按照某种方式进行染色体的变异,具体编译方式可以是单点变异法,也可以使用其他变异方法。
一般而言,交叉概率很高,如0.6,变异概率极低,如0.01。
具体而言,我们先初始化种群,然后进行进化,进化过程是“先按照适应度对个体进行排序,然后选择、交叉、变异,生出多少个子女,原种群中适应度最差的多少个体就被淘汰掉,新生子女取而代之加入种群,从而构成的新种群”,如果此时终止条件被满足则终止运算,进化过程中所出现过的适应度最高的个体即为答案,输出即可,否则,重新开始进化。
在MATLAB中使用GA工具可以对此类问题进行求解
这里会有一个疑问,那就是优秀父母的后代真的一定优秀吗?自然界中基于基因重组的遗传大概率能满足“优秀父母生出优秀子女”,但我们这种直接交叉基因的遗传方法其实未必,实际上此时的遗传算法退化成了一种能够尽量避免局部最优解的随机算法。但其实这也已经足够了。
这告诉我们,采用更生物学的遗传方式才能让遗传算法真正成为高效率的优质算法,但就算没有采用此类遗传方式,瞎遗传,遗传算法也可以给出一个蛮不错的解,毕竟遗传算法最坏情况下无非是退化成一个能避免局部最优解的随机算法。
关于之前用二进制编码而不是实数编码的原因也很容易理解了,用二进制编码能实现这种瞎遗传但勉强有点道理的遗传方式,而实数编码则难以给出勉强有道理的遗传方式,真就只能要么完全瞎遗传要么用某这特定公式计算子女了,前者效率过低,后者容易收敛于局部最优解。
遗传算法中的环境并不是不可改变的,环境本身也可以改变,具体体现为计算适应度的算法的改变,但这种改变不能过快,否则进化速度跟不上环境改变的速度。我们往往会有意随时间推移逐渐增大环境压力,防止种群在过于安逸的环境中收敛于局部最优解,这便是适应度尺度变换了,适应度尺度变换有三种经典方法,线性尺度变换、乘幂尺度变换以及指数尺度变换。
抽象化算法流程
再举一个例子,Max-cut problem问题,即将一个无向图切成2个部分(子图),从而使得2个子图之间的边数最多。
假设该问题中给定图如下
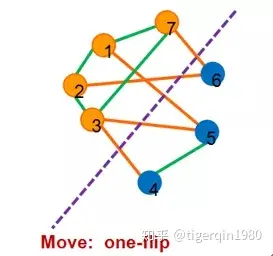
- 定义编码规则
对每个节点进行编号,使用7位的位串来编码一个解,某一位位0则代表对应的位属于子图1,为1则代表对应的位属于子图2
2.根据编码规则和问题要求写出解码函数和适应度函数
3设置种群大小
然后随机生成初始种群,比如如下(括号内是基因型,括号外是表型)
S1=7(0001111),S2=5(0011010),S3=7(1110000),S4=7(1011011)
S5=7(0101100),S6=5(0111100),S7=3(1110011),S8=4(0011110),S9=6(0001101),S10=6(1101001);
- 定义杂交规则,
本题中定义为若亲代对应位相同,则子代亦相同,若不同则随机遗传其中一方
- 设置变异概率和变异规则
本题中设置变异概率为0.05,变异规则是随机选取一位取反
- 设定终止规则,如达到最大迭代次数、达到最长运行时间、或者误差足够小等等。
实现方法
matlab的优化工具箱中提供了一系列函数用于实现遗传算法,但我们通常并不直接使用这些函数,而是在实时脚本中的优化工具箱中使用可视化工具辅助我们描述问题、解决问题,就我手头的23a版本而言,这部分的汉化做的还不错,只要从上述描述中理解到算法的内部机理,就能很轻松的使用可视化工具实现遗传算法。
算法评析
遗传算法的局限性在于如果种群的基因多样性不够丰富,那么就可能会过早趋同,陷入局部最优解,因此我们要保障足够丰富的基因多样性和足够多的迭代次数,这会导致遗传算法是一种耗时很长的启发性算法,不过遗传算法非常适合进行并行化处理,我们可以开启matlab的并行计算模式来降低算法耗时。
遗传算法的优势在于求得全局最优解的概率较大,且有较强的抗噪能力,当数据集噪声过大时可以考虑遗传算法。
遗传算法适用于难以求解的数学函数问题、难以确定参数时的调参问题(如用遗传算法算出较为优秀的初始值或超参数,进而优化BP神经网络等其他算法)
当然,遗传算法还有一个最大的劣势,那就是在相同时间内,他的求解精度几乎是启发式算法中最低的了,而启发式算法本身又以很难收敛到高精度而著称。因此能用确切的传统数学方法解决的问题,就不要使用遗传算法,比如问你2*2等于几,聪明人会掏出计算器说等于4,没学明白的人会用遗传算法迭代十万次得出结果3.99728。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」