零基础亦能看懂的神经网络笔记【零基础数模系列】
神经网络算法
前言(可跳过)
作为数模小白,看了很多讲解新概念新模型的文章,这些文章往往要么讲的很浅不讲原理只讲应用,让人知其然不知其所以然。要么讲的很深小白看不懂,同时总是忽略关键部分,经常性引入陌生概念让初学者疑惑,因此有了本文,任何能熟练掌握线性代数知识且逻辑思维能力尚可的人都可以理解,而无需其他数模知识,涉及任何新概念都会先讲解后使用
所以我就打算把自己学完之后的笔记整理出来,其中每一篇文章中可能含有直接从其他文章中搜集过来的公式,因为这些文章原本只是我自己的笔记,我懒得敲公式,只是写完之后想着整理出来,弘扬一下互联网精神,于是就有了这个系列。
一、主要应用
神经网络可以处理各种类型的问题,包括但不限于以下几种:
分类问题:神经网络可以用于分类问题,将输入数据分配到两个或更多的类别中。
评价问题:神经网络可以用于评价问题,例如信用评分、风险评估等。在这些问题中,神经网络的目标是根据输入数据生成一个评分或评级。
预测问题:神经网络可以用于预测问题,例如股票价格预测、销售预测等。在这些问题中,神经网络的目标是根据过去的数据预测未来的数据。
求最优解问题:神经网络可以用于求解优化问题,例如路径规划、资源分配等。在这些问题中,神经网络的目标是找到一组解,使得某个目标函数达到最优。
二、分类
最原始的神经网络是感知机SLP,由一个输入层和一个输出层构成,没有隐藏层,即只有一层神经元,计算过程是单向的。
进一步地,设置一个、两个或多个隐藏层便形成了多层感知机(MLP),多层感知机具有两个及以上的神经元,计算过程是单向的。
BP神经网络,是一种特殊的MLP模型,信号单向地从前往后传播,而误差则同样单向地从后往前传播。
SLP、MLP和BP都输出前馈神经网络(FNN),which的特点是计算过程是单向的,神经元之间是树状的,不存在跨层连接和同层连接。
卷积神经网络(CNN)类似于前馈网络,利用线性代数的原理来识别图像,专门用于计算机视觉处理等领域
循环神经网络(RNN)主要用于已知过往数据、预测未来结果,顾名思义布局并不仅仅单向流动
因此我们应该从单层感知机SLP开始,进一步研究MLP和BP神经网络,最后再了解RNN,从而试图理解BP是一种可迁移的思想,也可以应用于RNN中
- 单层感知机SLP
单层感知机常常用于分类,属于一种线性分类模型,类似于逻辑回归模型。与逻辑回归模型的区别在于SLP的激活函数是sign(将大于0的分为1、小于0的分为0,通常被称为单位阶跃函数),而逻辑回归的激活函数是sigmoid(将大于0.5的分为1、小于0.5的分为0)
如果数据集可以完全被某个超平面划分为两类(超平面即N维空间中的N-1维存在,比如二维空间中的直线),那么这个数据集就被称为是线性可分的数据集,否则成为线性不可分的数据集。
对于线性可分的数据集,SLP的基本任务就是在N维空间中寻找一个N-1维超平面S:wx+b=0完全把两类数据划分开来,而科学家也已经证明在这种情况下SLP的结果一定收敛。
不过,对于线性不可分的分类类问题,SLP就很难处理了,其结果难以收敛
其中,w=[w_1,...,w_n],x=[x_1,...,x_n]’,x不是横轴坐标,x_i表示第i轴的坐标,n个一次未知量恰好构成了一个N-1维的超平面方程。
一般的,如果我们已知一个数据集(p1,y1)~(pn,yn),其中x表示一个含有各指标的对象所对应的数据点坐标,y代表这个数据点的类别(二分类取值为0或1),就可以运用SLP算法来得出超平面S的解析式wp*b=0,得出模型f(x)=sign(wp+b)
SLP的具体运用步骤如下
先明确学习规则,即用来计算新的权值矩阵W和偏差向量B的算法
设目标向量为t(即答案为t),我们计算出来的估计向量y(即我们算出来的答案为y),输入向量(即题目)为p,则规定delta_Wij=(ti-yi)*pj,delta_bi=ti-yi
(这很合理,既然y=Wp+b,那么delta_Wij=deviation_y/p,b=deviation_y)
这个学习规则有如下效果:
1.如果第i个神经元的输出是正确的,即yi=ti,那么与第i个神经元联接的权值wij和偏差值bi保持不变
2.如果第i个神经元的输出是0,但期望输出为1,即有yi=0,而ti=1,此时权值修正算法为:新的权值wij为旧的权值wij加上输人矢量pj;新的偏差bi为旧偏差bi加上1
3.如果第i个神经元的输出为1,但期望输出为0,即有ai=1,而ti=0,此时权值修正算法,新的权值wij等于旧的权值wij减去输入矢量pj;新的偏差bi为旧偏差bi减去1
于是,我们的训练过程就是先给出一个初步模型f0,然后在输入向量x的作用下得出输出向量y,然后与目标向量t作比较,根据比较结果依据学习规则来进行权值和偏差的调整,得出改进后的模型
重新评价新模型,重复进行权值和偏差的调整,直到y彻底等于t或者训练次数达到事先设置的最大值时停止训练,然后便得到了最终模型
原始的SLP算法只能取0和1两个值,且学习规则不算完善,因此弊端较大,故而人们提出了下面这个改进版本ALE,即自适应线性网络,实际上相当于线性的改进SLP算法
ALE使用的激活函数是线性的,如f(x)=x,这允许输出是任意值,同时他采用的是W-H学习法则,也成最小均方差规则(LMS规则)来进行训练
先定义一个输出误差函数E(W,B)=(1/2)*([T-WP]^2)
W_H学习规则的目标就是通过调节权值矩阵和偏差向量使得E(W,B)达到最小值,形象的说,使E(W,B)从误差空间的某一点开始,沿着斜面向原点滑行
具体学习规则如下:
权的修正值正比于当前位置上E(W,B)的梯度,其比值称为学习速率,简称学习率,记为η,规定η∈(0,1),一般而言,当学习速率取得越大,训练过程就越不稳定,可能出现震荡现象。
在实际的应用中,η往往取一个接近1的数,或者取值为η=0.99/max{det(P*P’)}.
对于第i个神经元而言,有:
![]()
即Delta_Wij=η(ti-yi)*pj , Delta_Bi=η(ti-yi)
(有个疑问,为什么这个偏导数恰好等于这个结果,这是个数学问题,可以直接严谨计算,偏微分求导就相当于把其他所有量都看做常数,导一下就会发现确实是这个结果,也可以理解为在极小处一切函数都相当于是以导数为斜率的直线,因此有着这种直接比值的关系,至于为什么比值是1?嘿,显然是因为科学家特意这么定义的E才方便让比值是1,这样可以减少不必要的复杂度,同时这个被算出来的ti-ai其实暗示了我们刚才的那个粗糙的原始学习规则其实就是一种特殊的W-H规则,说明之前的按个朴素的学习规则也是有一定科学依据的)
采用W-H规则训练时,被训练的输入矢量必须是线性无关的,否则无法收敛。同时如果学习速率过大,还会导致振荡现象
同样,在确定了学习规则之后,我们的训练过程就是先给出一个初步模型f0,然后在输入向量p的作用下得出输出向量y,然后与目标向量t作比较,根据比较结果依据学习规则来进行权值和偏差的调整,得出改进后的模型,然后重新评价新模型,重复进行权值和偏差的调整,直到y彻底等于t或者训练次数达到事先设置的最大值时停止训练,从而得到了最终模型
应用举例,若有输入矢量P和目标矩阵T如下,T的每一行都是一个目标向量Ti
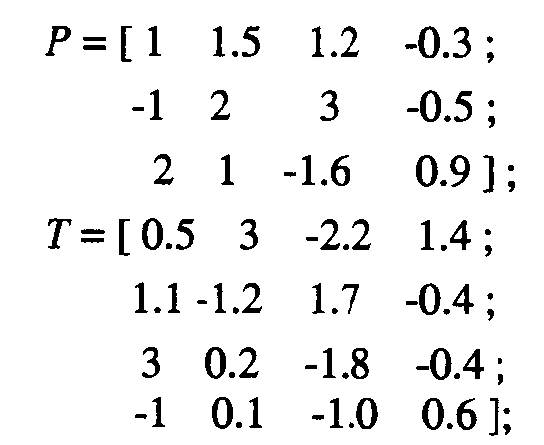
这是四个“三个指标描述的数据点归类到一个指标描述的线性类别中”的问题,等价于解一个线性方程组,比如w_1*P+b1=T1,然后W=[w_1,...,w_n]’,B=[b1,...,bn]’。
解得精确解为:
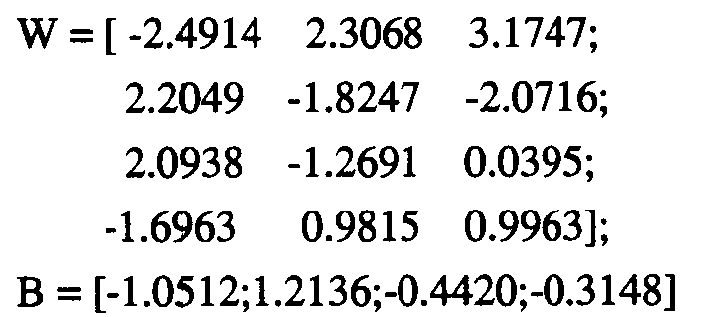
这其实解决了一个问题,那就是为什么权值向量w和偏差数值b变成的权值矩阵W和偏差向量B,就是因为我们往往把“四个‘三个指标描述的数据点归类到一个指标描述的线性类别中’的问题”视为“一个‘三个指标描述的数据点归类到四个指标描述的线性类别中’的问题”,因此要为每个描述类别的指标(每个问题)分别有一个w和b,放到一起可不就成了W和B了吗,即从下面的左图变成下面的右图
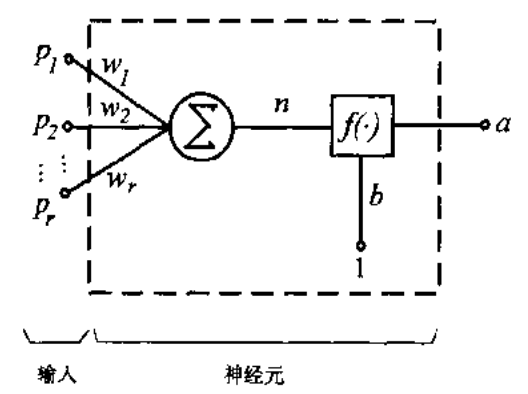
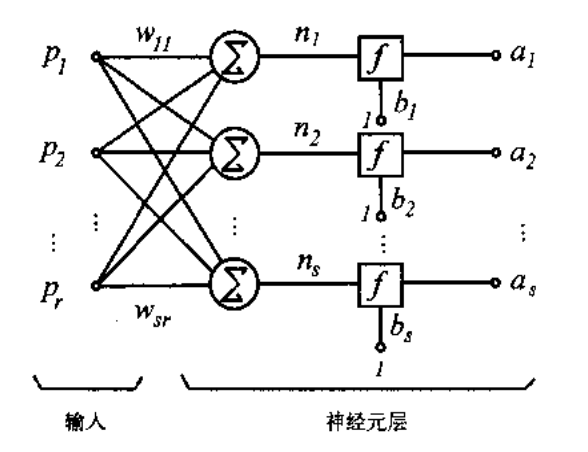
注意这两个图中都没有隐藏层,f层是激活函数,Sigma是超平面S的表达式,他们共通构成了一层神经元,直接从输入p到输出a(神经元可以理解为两层之间的链接,因此有两层神经元才算是一共有三层内含隐藏层,只有一层神经元则没有隐藏层,不要误把神经元当做是隐藏层。表述神经元的是权矩阵W和偏差向量B,因此有n层神经元就有n对W-B)
运用神经网络训练:
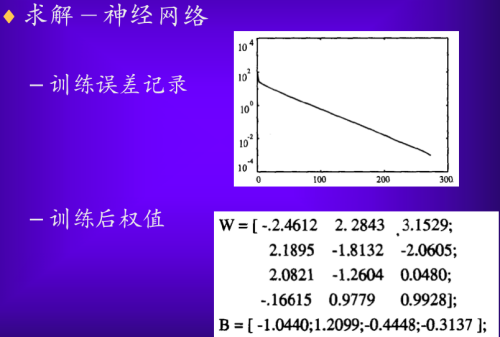
再比如


可见,对于特别简单的问题,神经网络往往无法得到足够精确的解,因为训练误差达到期望误差值或训练次数达到最大循环次数之后训练就会被终止,想要解决这个问题,要么进行更多轮训练循环,要么直接改用能求精确解的普通算法,换句话说,没必要用神经网络的问题就不要楞用神经网络了。
再或者,对于有着零误差的精确线性权值关系的问题而言,可以直接用函数solvelin求解,此时得到的权值就是精确的了
进而,我们还可以让激活函数是S型(Sigmoid)的,比如

对应的神经网络模型自然又是一种新的SLP,即非线性的改进SLP。
注意到,分类其实就是一种对二值型函数的预测,线性激活函数和S型函数的提出使得神经网络不仅可以处理分类类问题,还可以处理评价类问题和预测类问题。
要注意,我们说SLP是线性的/非线性的实际上是在说它的激活函数是线性的还是非线性的,但SLP本身是用超平面去划分的,这使得一切SLP本质上都是线性的,激活函数无非是一种“距S距离”->”类别”的映射,01型在S上是1,S下是0,线性型SLP在S上方1单位长度是1,在S上方两单位长度是4,非线性型SLP中在S上方1单位长度是2,在S上方2单位长度是3或5或其他数。总之仅仅改变了类别划分,并未改变决策边界本身是线性的这一事实。
因此,只要数据集本身是非线性可分的,SLP就难以处理,哪怕是非线性的SLP也难以处理。
尽管我们已经知道单层感知机难以处理线性不可分的数据集,但我们还是直观的来感受一下单层感知机的缺陷吧,拿XOR问题为例,(0,0)->0;(1,1)->0;(1,0)->1;(0,1)->1;感知机甚至无法给出这么简单问题的答案,就是因为这是一个线性不可分的数据集,我们无法找到一条线,把(0,0),(1,1)分在一边,而把(0,1),(1,0)分在另一边。
另外,W_H规则其实就是数模领域人们常说的梯度下降法
此外,有人指出W_H学习规则+ALE的线性激活函数才是真正的SLP,还有人称之为线性SLP,还有人认为我们前文所说的朴素学习规则+0/1型激活函数的SLP才是原始SLP等等,这门复杂科学在发展过程中产生了很多概念错用的情况,具体情况或许可以考察,但没有意义,具体的分类其实不重要,算法本身的思想懂了即可
对SLP(这里的SLP是广义的,包括尚文所说的MP(即原始SLP)、01型SLP、ALE(即线性SLP)和非线性SLP)的改进诞生了多层感知机,而针对多层感知机MLP的权值如何确定科学家也提出了多种方法,其中最为人所熟知的就是BP算法,运用了BP算法的MLP就属于BP神经网络
原始SLP可以通过matlab中的learnp函数来实现,可用于解决线性二分类型的问题。线性改进SLP可以通过matlab的trainwh来实现,但其实这种更复杂的SLP则没必要使用,毕竟BP-MLP神经网络全面优于这些改进型的SLP,我们学习这些SLP只是为了更好地理解MLP,而不是为了直接使用SLP。(哪怕是原始SLP也不一定使用,可以用原始SLP和求超定方程最小二乘解从而求划分直线的方法进行对比,哪个的结果表现得更好就用哪个)
四.多层感知机MLP
多层感知机本身很容易理解,就是有多层神经元,后一层的神经元把前一个神经元的输出当做输入,如下,
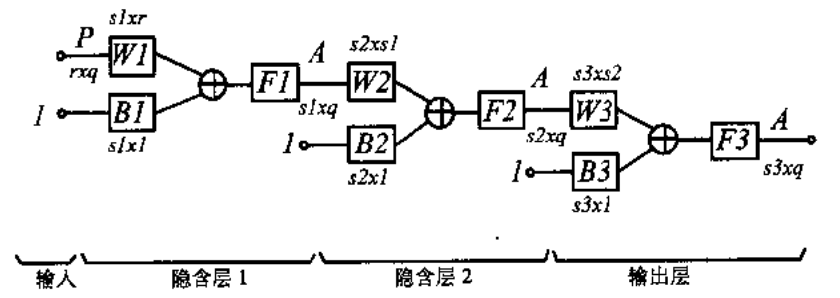
其中,
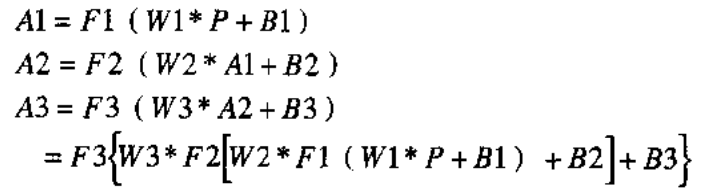
其中,每一层的激活函数可以不同,一般而言,只有最后一层神经元使用线性激活函数,前面的隐藏层神经元(前面说过了, 神经元不在层中,层是描述数据的而不是神经元的,但我们一般用“隐藏层神经元”“这个词来方便的指代除了最后一个神经元层以外的所有神经元层,这个词可能起源于误用,最后因为应用过于广泛而不得不被人们所接受)都用S型激活函数。
这是因为如果比如有连续的两层使用了线性激活函数,比如第一层和第二层,那么就会有A2=F2(W2*A1)=W2*AI=W2*F1(W1*P)=W2*W1*P,即这两层相当于等效于以W1*W2为权值矩阵的单层线性网络的输出,因此不应该连续的使用两层线性激活函数。为了方便处理,一般都是只有最后一层神经元使用线性激活函数,隐藏层神经元都用S型激活函数。(当然也可以所有神经元全用S型激活函数,取决于具体需求)
为什么没提及01型激活函数呢,这是因为为了解决非线性可分的数据集的划分问题,我们不仅要使用MLP,还要要求MLP网络的每一层的激活函数都是处处可导的,所以实际应用的MLP神经网络中不可以出现01型激活函数,只能出现线性激活函数、对数型S激活函数和双曲正切型S激活函数。
多层神经网络所划分的超平面不是线性的,是一个比较柔和的任意光滑界面,因此可以实现更为精确的划分,从而解决数据集非线性可分的问题。
但是,有一个很重要的问题有待解决,那就是如何确定这些W和B,W_H规则只适用于单层或者多线性层的问题,即只适用于SLP模型,而不适用于此类MLP模型,必须提出一个新的确定权值的办法,由此,人们提出的BP算法,这是最常用的MLP确定权值的方法之一,人们将用BP算法确定权值的MLP神经网络成为BP神经网络
五.BP神经网络
BP网络的产生归功于BP算法的获得,BP算法是一种监督式的学习算法,可以理解为是一种双向的W_H规则,毕竟W_H规则也叫最小均方差规则,核心思想也是通过线性修正实现最小均方差,而BP算法的核心思想也是通过线性修正实现最小均方差,只不过会既会进行信息的正向传播,也可以进行误差的反向传播。
拿双层神经元的BP神经网络为例把,把两层神经元分别命名为隐藏层神经元和输出层神经元,权值矩阵分别命名为W1、W2,偏差向量分别命名为B1、B2,对应函数分别为f1、f2,输出向量分别为a1a2,每一层产生的误差分别是e1e2。
下面是一本比较好的讲神经网络入门的书籍中的证法,有余力的人可以看看下面这个烂透了的做法,着急的人就别看了,直接跳过看我重写的证明。哎,怎么就没有大牛愿意写入门级书籍呢。
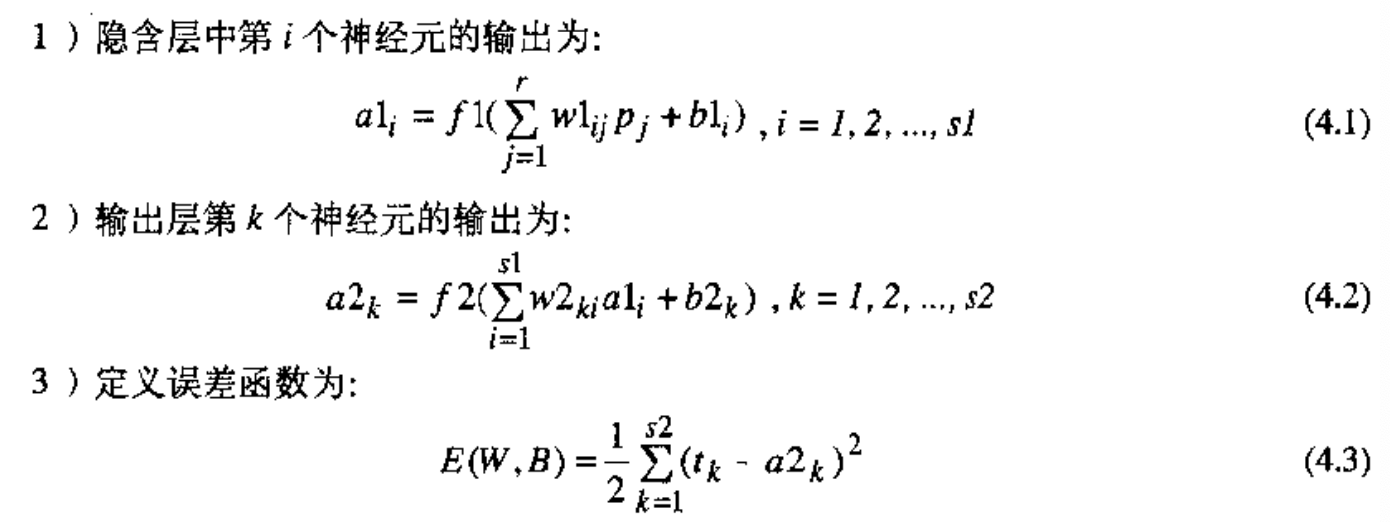

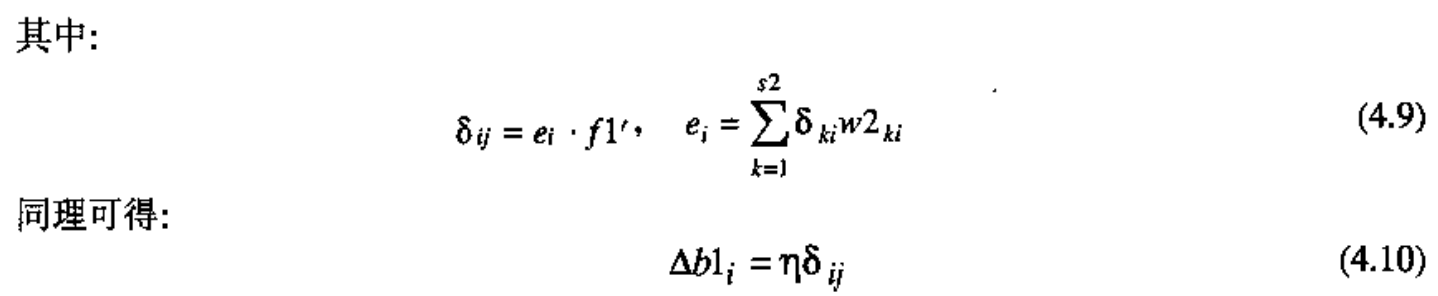
。
但这里还有不少问题,比如(4,6)就很明显写错了,再比如(4,8)中凭空引入a2k极其奇怪,k是啥?毫无道理,而且怎么推导出sigma来的?也毫无道理。再比如推导过中总有只用部分元素代表整体元素的嫌疑。再再再再再比如引入的delta明显出现用同一符号表示不同表达式的严肃问题,造成了极其混乱的结果,比如(4,9)中的两个delta一个是e*f1一个是e*f2,且他妈的竟然两个e也不是同一个意思。这个指明到元素的证法逻辑上有问题而且难以理解,极为复杂度很高以至于作者都写错了呵呵,所以我自己重写了整个推导过程,用向量和矩阵直接推导整个过程简单无数倍且没有逻辑问题,而且所以请忘掉上面那个狗屎过程吧,那个愚蠢的过程可能坑走了我这个小白近一个点的时间...

舍弃掉一万个下标之后反而没有了逻辑错误,且更容易理解了,真是神奇,这说明矩阵求导是个极有利的工具,有空得多琢磨琢磨。
显然,偏差变量e2应该等于t-a2,
那么,注意到Delta_W2=η(t-a2)f2’a1=ηe2f2’a1,
仿写Delta_W1=ηe1f1’p,则e1=e2*f2’*a1。
当然,为什么这么仿写是有道理的以及这么算出来的e1又为什么担得起表示的担子就比较复杂了,没查到,总之先忽略这块。总之注意到,偏差变量e的计算是一个逆过程,和结果变量a的计算正好相反,因此我们称BP算法是一个数据正传、偏差逆传的算法。
还可以这么理解,根据公式我们发现Delta_W1=Delta_W2*f2’*a1,因此偏差的计算是一个逆过程,因此称BP算法是一个数据正传、偏差逆传的算法。总之无所谓了,这块不重要,反正算法公式本身已经理解了,这部分讲解“怎么个偏差逆传法”的部分其实并不重要
通过BP神经网络解题的步骤也很容易地能类比出来,我们已经确定了把BP算法作为学习规则,接下来只需要随机初始化每一对W和B,给出初始模型,然后进行正向运算,然后检验模型,反向求出偏差值更新模型,然后在正向计算周而复始,直到误差足够小于目标误差或者运算次数达到规定的上限为止
六.循环神经网络RNN
数模一般用不到,过一会再写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号