【Machine Teaching】An Overview of Machine Teaching
Machine Teaching
1 Introduction
1️⃣ 什么是 Machine Teaching?
searching the optimal (usually minimal) teaching set given a target model and a specific learner
学生可以类比为机器学习算法,老师知道学生的算法以及参数,并且知道学生模型参数的最优值,但是不能直接告诉学生,而是构造最优的训练集让学生训练,使得学生的参数尽可能达到该最优值。
2️⃣ 如何定义最优?
一般的,训练集基数越小越好。
3️⃣ 如果老师已经知道了最优参数,为什么还要费劲去训练学生学会呢?
该问题在第二章中有解释。老师和学生是独立的个体,不能发生心电感应,有些时候只能通过训练数据向学生传递最优参数信息。在一些场景,比如训练集中毒的网络安全问题上以及图片类型识别上有所体现。
4️⃣ 为什么说机器教学是机器学习的逆过程?
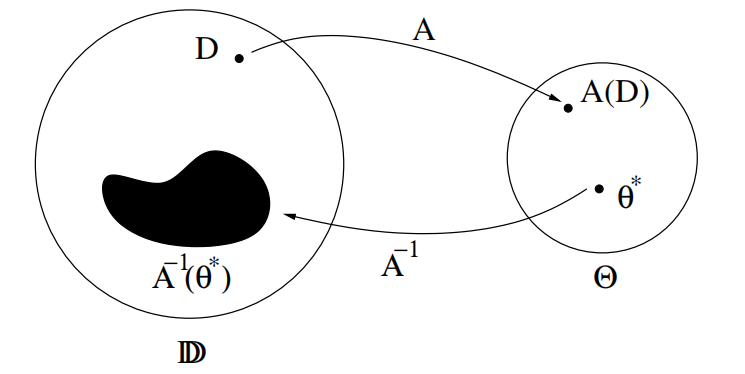
机器学习是学生利用给定的训练数据 \(D\) ,在算法 \(A\) 上进行训练,得到训练结果 \(A(D)\),该结果表示模型中的参数取值。
机器教学是老师利用已知的最优模型参数,在算法 \(A\) 的逆运算上反向得到最优的训练数据。
5️⃣ 如何求解训练集
不会去求 \(A\) 的逆,而是转化成优化问题。
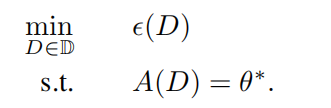
- \(\epsilon(D)\):teaching effort function,大小一般与训练集基数相等,越小越好。也可以给其增加更复杂的含义,比如分类问题中不同类之间的距离。
- $\mathbb{D} $:训练集的搜索空间。比如在 pool-based machine teaching 中,池子包含数据集 \(S\) ,训练集数据只能从池子里面选择,即只能是 \(S\) 的一个子集,搜索空间表示池子中数据的所有可能组合情况,即 \(2^S\)。
幂集:设有集合A,由A的所有子集组成的集合,称为A的幂集,记作 \(2^A\),即:\(2^A=\left\{ S|S\subseteq A \right\}\) 。
6️⃣ 如果机器学习算法没有闭合解?
闭合解:closed-form expression 是一个数学表达式;这种数学表达式包含有限个标准运算。
对于大多数学生,没有闭合形式的 \(A(D)\),没法通过公式直接计算,大部分机器学习算法求解是基于最优化
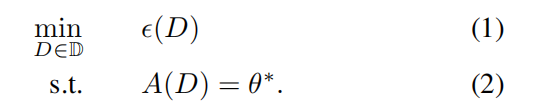
所以一般将 \(A(D)\) 表示成最优化的形式,即二维优化问题:
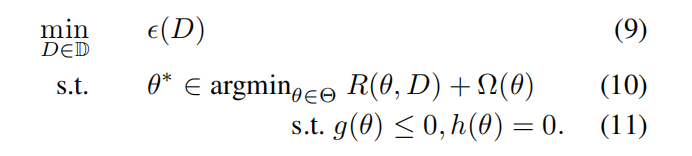
- \(R\) :经验风险
- $\varOmega $ :正则化项
- \(g,h\):约束
二维优化问题难解,对于某些凸的机器学习算法,可以将(10)转化成KKT条件,这样的话下式就变成了上式的一些新的约束,二维优化就转化为了一维优化问题。
(2)式和(10)式这两个约束可能过于严格,很难满足。
一个解决方法就是放松教学的约束,(1)式等价于
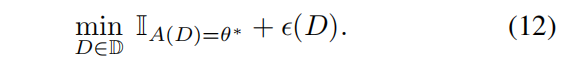
其中
如果学生正确学习到了 \(\theta^*\) ,值为 0;否则值为 \(\infty\) 。
可以放松这个约束,学生不用非得精确地学习到 \(\theta^*\) ,将(1)式放松为:
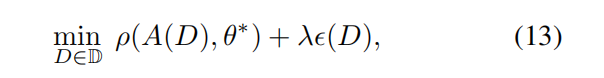
- \(\lambda\):调节
teaching risk和teaching effort的权重。 - $\rho \left( \right) $ :
teaching risk,用来衡量 \(A(D)\) 与 \(\theta^*\) 之间的差异。回归问题可以使用范数,分类问题可以定义如下:
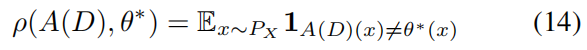
这样放松二维优化问题得到下式:

7️⃣ 老师是否能知道学生的算法的一切呢?
如果学生是人类,老师就无法知道学生的想法了。
有一种情况是,学生的算法属于一类算法的集合 $A\in \mathbb{A} $ ,老师只知道 $\mathbb{A} $ 。一个解决方法就是通过 probe ,老师从一个初始训练集 \(D_0\) 开始,学生进行训练,但是老师不能直接观察学生训练后的模型 \(A(D_0)\),老师可以给学生数据让其预测结果,对于 $A'\in \mathbb{A} $,只要 $A'\left( D_0 \right) \left( X \right) \ne A\left( D_0 \right) \left( X \right) $ ,就可以把 \(A'\) 剔除,最后集合中剩下的一个算法就是学生的算法。
Example1: 1D threshold classifier
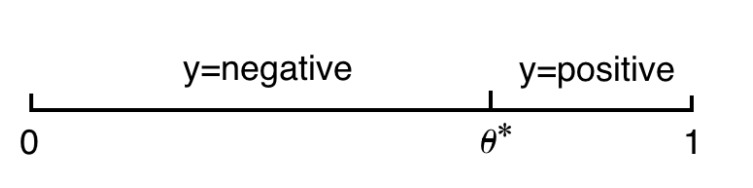 $$
y=\begin{cases}
positive,x>\theta ^*\\
negative,x<\theta ^*\\
\end{cases}
$$
输入 $n$ 个独立同分布且服从 $0-1$ 分布的训练数据进行训练。
$$
y=\begin{cases}
positive,x>\theta ^*\\
negative,x<\theta ^*\\
\end{cases}
$$
输入 $n$ 个独立同分布且服从 $0-1$ 分布的训练数据进行训练。
Passive learning
泛化误差:
这是因为 \(n\) 个独立同分布且服从 \(0-1\) 分布的训练数据的平均间隔是 \(1/n\) ,代表了决策边界的不确定性区间大小。
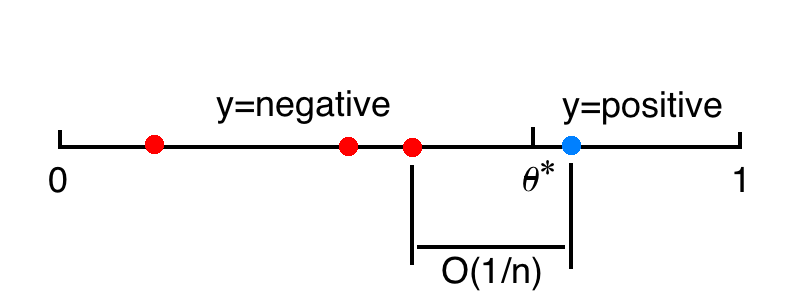
如果想要控制泛化误差为 \(0.001\),就需要令 \(n=1000\)。
简单来说,被动学习中,学生仅仅接受知识,而不进行提问。学生对于训练数据只知道它们的标签应该是什么,而该分类问题的关键是距离 \(\theta^*\) 最近的靠近 0 端和靠近 1 端的两个数据,其他训练数据没有用处。
Active learning
泛化误差:
主动学习是一个二分检索的过程,学生会向老师提问,老师回答目标 \(\theta\) 的答案,每次淘汰一半的数据。
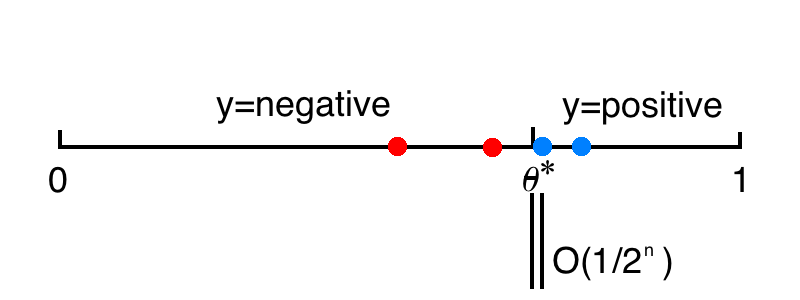
如果想要控制泛化误差为 \(0.001\),只需要令 \(n=10\)。
简单来说,主动学习中,学生不仅接受知识,而且对老师进行提问,老师进行解答。
Machine teaching
老师知道目标参数 \(\theta^*\) ,如果想要泛化误差为 $\epsilon $ ,只需要提供两个训练数据,一个在 \(\theta^*\) 左边,一个在 \(\theta^*\) 右边,两个训练数据之间的距离是 $\epsilon $ ,而 $\theta^* $ 位于中间即可。

简单来说,机器教学中,老师知道最优参数以及学生的模型和参数,并且会由此设计最优的训练集用来训练学生,使得学生参数尽可能达到最优参数。
Example2: SVM
老师想要教给学生 SVM d 维空间超平面决策边界,只需要提供两个训练数据,分别位于超平面两侧被平面平分且连线垂直于超平面,这样的点可以有无数种组合。
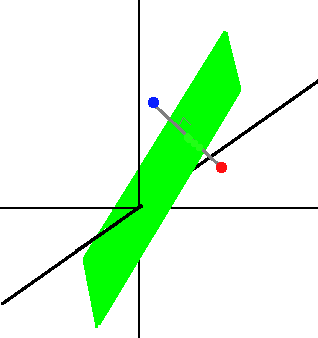
Example3: Gaussian density
对于 d 维高斯密度,
学生通过计算样本均值和样本协方差矩阵来学习。
老师可以用 \(d+1\) 个点构造训练集,这些点是以 \(\mu\) 为中心的 \(d\) 维四面体顶点,且进行适当缩放。
Contrast
机器学习就是计算经验风险取到最小值时的参数。
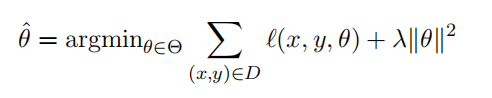
对于机器教学,目标参数 \(\theta^*\) 是已知的,老师需要找到一个训练集,使得学生在该训练集上训练能够得到损失函数最小时的参数接近 \(\theta^*\) 。
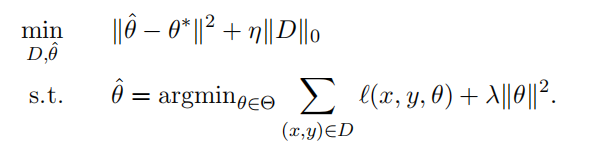
上式优化是老师的问题,老师需要关注学生学习情况,即 \(\hat{\theta}\) 是否接近 \(\theta^*\) ,同时还需要控制训练集的大小,使用尽量小的训练集。
下式优化是学生的机器学习问题。
老师需要知道学生的算法来构造优化。
2 Why bother if the teacher already knows \(\theta^*\) ?
有时候老师已经知道了 \(\theta^*\) ,那机器教学还有什么意义?有的老师需要通过训练数据来向学生传达 \(\theta^*\) 。
- 地质学家知道如何判断岩石类型,这个决策边界 \(\theta^*\) 存放在老师那里,没法通过心灵感应直接传递给学生,但是老师可以通过挑选合适的岩石标本给学生展示,如果挑选的岩石标本代表性足够强,学生就可以很快学会。利用机器教学可以优化岩石样本的选择。
- 训练集中毒。 考虑一个垃圾邮件过滤器,它不断调整它的阈值以适应。随着时间的推移,合法内容的变化。知道该算法的攻击者可以向垃圾邮件过滤器发送专门设计的电子邮件,以操纵阈值,从而使某些垃圾邮件能够通过滤器。在这里,攻击者扮演的是老师的角色,而受害者则是毫无戒心的学生。
从编码的角度,老师有 \(\theta^*\) 的信息,解码者是一个固定的机器学习算法,它接受训练集,将其解码求得 \(A(D)=\hat{\theta}\) 。老师必须使用由训练集组成的码字对 \(\theta^*\) 编码,最合适的码字就是机器学习算法的逆。老师会在最小的训练集挑选数据。
老师假定需要知道学生的机器学习算法。例如,学生是线性回归最小二乘法,老师给的训练集也是按照符合该算法的数据,则可以训练。但如果学生是带正则项的岭回归,老师原来的训练集就不再适用了。
优化数据就是机器教学,而优化模型就是机器学习。
机器教学更正规的定义:

TeachingRisk:定义了老师的不满意程度, \(\theta^*\) 包含在该方程中。也可以被定义为 \(\hat{\theta}\) 在验证集上的泛化误差,这时不需要 \(\theta^*\) 。TeachingCost:与训练集大小有关。考虑训练集对学生的负担。
两种受限的机器教学问题模式:
1️⃣ 在充分学习的前提下,尽量减少 TeachingCost。
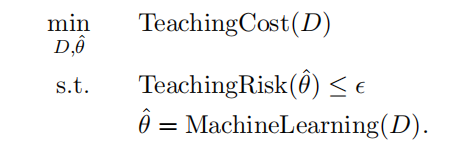
2️⃣ 优化学习,允许一定的 TeachingCost。

3 Characterizing the machine teaching space
3.1 The human vs. machine dimension: Who teaches whom?
机器教学空间的几个不同维度。
- 机器教机器。数据中毒攻击:老师的训练集给出细微的修改,可以避免被检测到,使得学生通过机器学习不断学习中毒样本。
- 机器教人。机器教学系统:类比之前的地理教学。
- 人教机器。人类领域专家用来快速训练文本分类器。学生也可以教老师如何教学。
- 人教人。增强教育学。
3.2 The teaching signal dimension: What can the teacher use?
监督学习中使用带标签的数据。
synthetic / constructive teaching:使用特征空间中的任意数据,并且对数据进行加工和构造。pool-based teaching:使用实际数据,比如图像和文档。从池子里面选择数据。hybrid teaching:从池子里选择数据,还可以对数据进行修改。
3.3 The batch vs. sequential dimension: Teaching with a set or a sequence?
batch teaching:给学生一批无序数据学习。sequential teaching:老师必须优化训练数据的顺序,使得学生学习有序数据(由易到难)。
3.4 The model-based vs. model-free dimension: How much does the teacher know about the student?
model-based approach:老师知道学生的学习算法、参数、版本空间,学生对老师完全透明。model-free approach:学生对老师是黑盒,老师给学生训练数据,只观察学生输出的TeachingRisk。gray box student:老师知道学生的学习算法的一部分,比如使用的什么模型,什么损失函数,但是可能不知道损失函数中的某些参数。老师可以probe学生,通过学生的结果推测参数值。
3.5 The student awareness dimension: Does the learner know it is being taught?
大多数机器教学场景是学生没有预料到被训练,学生认为的训练数据是独立同分布,而老师提供的训练数据一般不是独立同分布。
有一些场景中学生意识到了自己在被老师教
Recursive Teaching Dimension (RTD) and Preference-based Teaching Dimension (PBTD)- 学生可以提高老师的训练集水平
- 如果老师心中学生的模型与学生实际的模型不一样,学生意识到了这点,那么学生可以调整老师提供的训练数据使其符合自己的模型来实现最优化
- 在安全领域,受害者可以使用防御机制
3.6 The one vs. many dimension: how many students are simultaneously taught?
一个老师面对多个学生的情况,每个学生的学习算法可能都不一样,老师不可能对每个学生都进行最好的教学。
一个选择是优化最差的学生
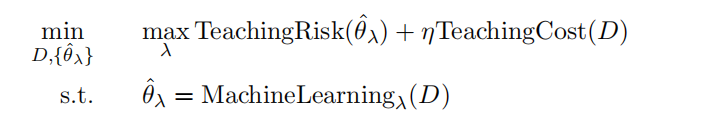
另一个选择是优化平均学生

3.7 The angelic vs. adversarial dimension: Is the teacher a friend or foe?
根据意图,机器教学有好有坏。
Reference
- Xiaojin Zhu, Adish Singla, Sandra Zilles, Anna N. Rafferty. An Overview of Machine Teaching. ArXiv 1801.05927, 2018.
- Xiaojin Zhu. Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education. In The Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI ``Blue Sky'' Senior Member Presentation Track), 2015. AAAI / Computing Community Consortium "Blue Sky Ideas" Track Prize.
An overview of machine teaching.
[pdf | talk slides]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号