【数据结构与算法】字符串匹配(后缀数组)
概念
简介
在计算机科学里, 后缀数组(英语:suffix array)是一个通过对字符串的所有后缀经过排序后得到的数组。此数据结构被运用于全文索引、数据压缩算法、以及生物信息学。
后缀字符串
- 后缀字符串:从后往前依次递增截取的字符串。长度为 n 的字符串有 n 个后缀
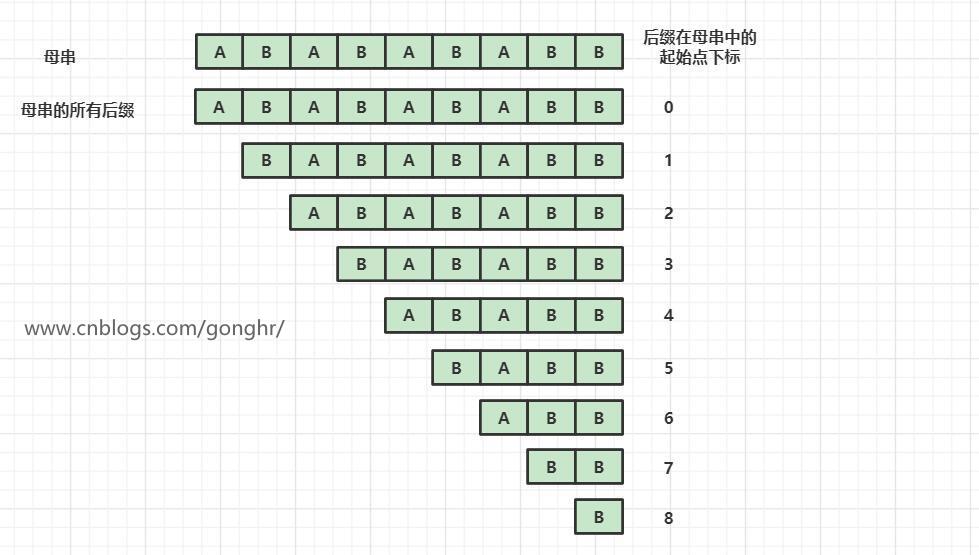
后缀数组和rank数组
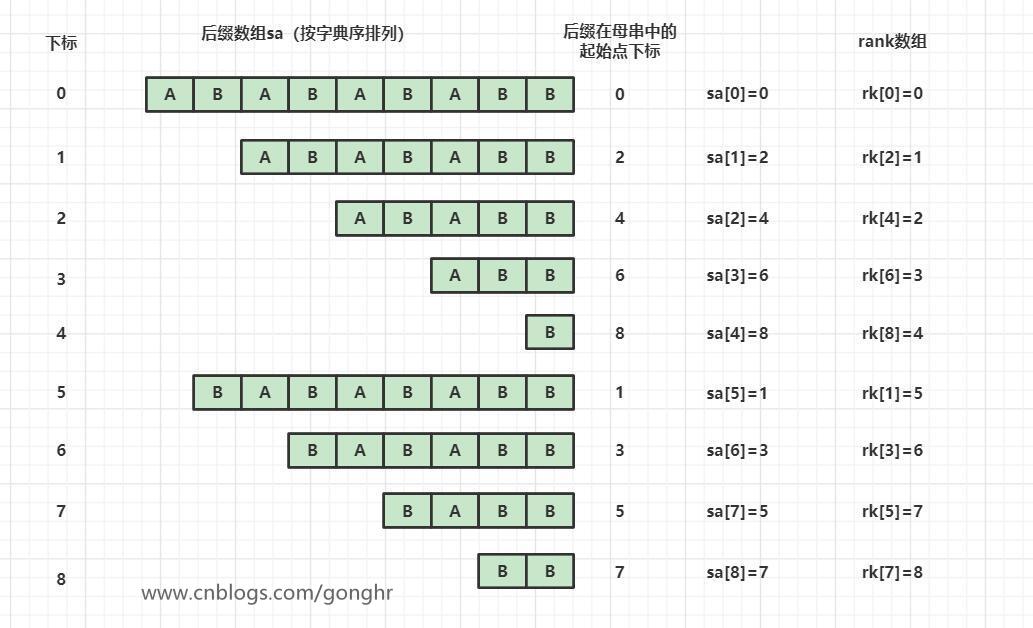
-
后缀数组:排名和原下标的映射。把字符串的n个后缀子串按照字典序从小到大排列,形成的数组,在数组中记录后缀的起始下标。是排名到下标的映射。
sa[m]=n表示排名是m的后缀字符串在原字符串的起点是n如:sa[0]=5 表示排名是0位的后缀字符串在原字符串的起点是5
-
rank数组:给定后缀的下标,返回其字典序。是下标到排名的映射。
rk[n]=m表示后缀在原字符串起点是n的字符串的排名是m如:rk[5]=0 表示后缀在原字符串起点是5的字符串排名为0位
-
显然,后缀数组和rank数组是互补的
sa[rk[i]] = rk[sa[i]] = i
思路分析
后缀数组主要用于字符串匹配的查询。
有一个显而易见的基本概念:字符串的子串一定是某个后缀的前缀
如果给定一个字符串,想看它是不是母串的子串,那么我们可以先构造母串的后缀数组,然后使用二分查找,根据字典序查找出与该字符串最匹配的后缀,然后遍历后缀,如果该字符串是该后缀的前缀,那么就说明该字符串是母串的子串;否则不是。
如何求后缀数组以及进行字符串匹配
朴素法
获取所有后缀放入数组,然后使用Arrays.sort() 按照字典序排序。
注意:不仅要获取后缀,后缀在母串的起点下标也需要获取,也就是说后缀和其在母串的起点下标是一体,不可分割的,为了解决这个问题,需要把后缀字符串和其起点下标封装成对象,并且实现Comparable接口。
//求后缀数组
public static Suff[] getSa(String src) {
int strLength = src.length();
/*sa是排名到下标的映射,即sa[i]=k说明排名为i的后缀是从k开始的*/
Suff[] suffixArray = new Suff[strLength];
for (int i = 0; i < strLength; i++) {
String suffI = src.substring(i);//截取后缀
suffixArray[i] = new Suff(i, suffI);
}
Arrays.sort(suffixArray);//依据Suff的比较规则进行排序
return suffixArray;
}
//封装后缀和起点下标
class Suff implements Comparable<Suff> {
String str; //后缀内容
int index;//后缀的起始下标
public Suff(int index, String str) {
this.index = index;
this.str = str;
}
@Override
public int compareTo(Suff o2) {
return this.str.compareTo(o2.str);
}
@Override
public String toString() {
return "Suff{" +
"str='" + str + '\'' +
", index=" + index +
'}';
}
}
- 时间复杂度:快排
O(nlogn),字符串一一匹配还需乘O(n),所以总的时间复杂度是O(n^2·logn)
倍增法
倍增算法的主要思路是:用倍增的方法对每个字符开始的长度为2^k的子字符串进行排序,求出排名,即rank值。k 从О开始,每次加1,当2^k大于n以后,每个字符开始的长度为2^k的子字符串便相当于所有的后缀。并且这些子字符串都一定已经比较出大小,即rank值中没有相同的值,那么此时的rank值就是最后的结果。每一次排序都利用上次长度为2^(k-1)的字符串的rank值,那么长度为2^k的字符串就可以用两个长度为2^(k-1)的字符串的排名作为关键字表示,然后进行快速排序,便得出了长度为2^k的字符串的rank值。
这里和罗穗骞论文里的排序思路略有不同,采用快速排序简化代码帮助理解。
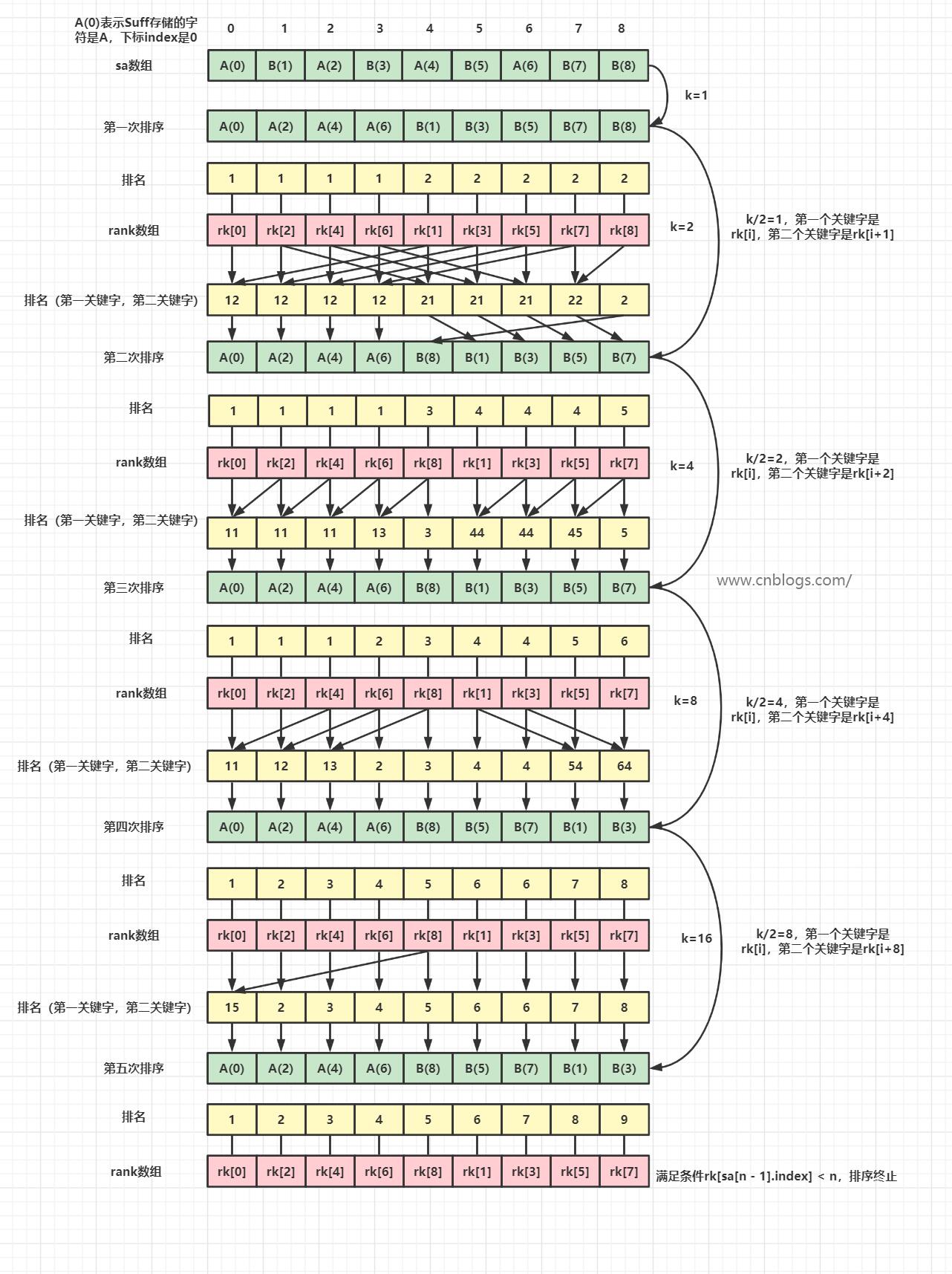
用rank数组记录sa数组中每个index的排名。
修改一下Suff类:
class Suff implements Comparable<Suff> {
public char c;//后缀内容
private String src;
public int index;//后缀的起始下标
public Suff(char c, int index, String src) {
this.c = c;
this.index = index;
this.src = src;
}
@Override
public int compareTo(Suff o2) {
return this.c - o2.c;
}
@Override
public String toString() {
return "Suff{" +
"char='" + src.substring(index) + '\'' +
", index=" + index +
'}';
}
}
改进的求后缀数组方法:
public static Suff[] getSa(String src) {
int n = src.length();
Suff[] sa = new Suff[n];
for (int i = 0; i < n; i++) {
sa[i] = new Suff(src.charAt(i), i, src);//存单个字符,接下来排序
}
Arrays.sort(sa); //单个字符使用快排
/*rk是下标到排名的映射*/
int[] rk = new int[n]; //rank数组
rk[sa[0].index] = 1; //排名从1开始
for (int i = 1; i < n; i++) {
rk[sa[i].index] = rk[sa[i - 1].index]; //下标所指字符相同则排名相同
if (sa[i].c != sa[i - 1].c) rk[sa[i].index]++; //字符不同,则排名加一
}
//倍增法
for (int k = 2; rk[sa[n - 1].index] < n; k *= 2) { //外层O(logn)
final int kk = k;
Arrays.sort(sa, (o1, o2) -> {
//不是基于字符串比较,而是利用之前的rank
int i = o1.index;
int j = o2.index;
if (rk[i] == rk[j]) {//如果第一关键字相同
if (i + kk / 2 >= n || j + kk / 2 >= n)
return -(i - j); //如果某个后缀不具有第二关键字,那肯定较小,索引靠后的更小
return rk[i + kk / 2] - rk[j + kk / 2];
} else {
return rk[i] - rk[j];
}
});
/*---排序 end---*/
// 更新rank
rk[sa[0].index] = 1;
for (int i = 1; i < n; i++) {
int i1 = sa[i].index;
int i2 = sa[i - 1].index;
rk[i1] = rk[i2];
try { //两个字符串不相同,排名加一
if (!src.substring(i1, i1 + kk).equals(src.substring(i2, i2 + kk)))
rk[i1]++;
} catch (Exception e) { //i1+kk越界了,则说明i1字符串比i2字符串短,且原先排名在i2之后,所以排名加一
rk[i1]++;
}
}
}
return sa;
}
- 时间复杂度:快排复杂度
O(nlogn),外层循环logn层,所以总的时间复杂度是O(n(logn)^2)
更好的优化
内部字符串比较的时候使用基数排序O(n)可以时总的时间复杂度降低到O(nlogn)
还有时间复杂度为O(n)级别的DC3和SA-IS方法,可自行查阅资料,已放在文末。
二分法匹配字符串
private static void match(String s, String p) { //s是母串,p是模式串
Suff[] sa = getSa(s); //获取后缀数组
int l = 0;
int r = s.length() - 1;
//二分查找,nlog(m)
while (r >= l) {
int mid = l + ((r - l) >> 1);
//居中的后缀
Suff midSuff = sa[mid];
String suffStr = s.substring(midSuff.index); //获取后缀
int compareRes;
//将后缀和模式串比较,O(n)
if (suffStr.length() >= p.length()) //后缀字符串长度大于等于模式串,截取后缀字符串的前缀与模式串比较
compareRes = suffStr.substring(0, p.length()).compareTo(p);
else //后缀字符串长度小于模式串,直接进行比较
compareRes = suffStr.compareTo(p);
//相等了,输出后缀的起始位置
if (compareRes == 0) {
System.out.println(midSuff.index);
break;
} else if (compareRes < 0) { //后缀小于模式串,左指针右移
l = mid + 1;
} else { //后缀大于模式串,右指针左移
r = mid - 1;
}
}
}
高度数组
概念
-
高度数组:(height)是后缀数组中每两个相邻字符串元素的最长公共前缀的长度的集合
-
LCP:(longestCommonSubString)最长公共前缀
-
height[i] = LCP(sa[i],sa[i-1])
思路和实现
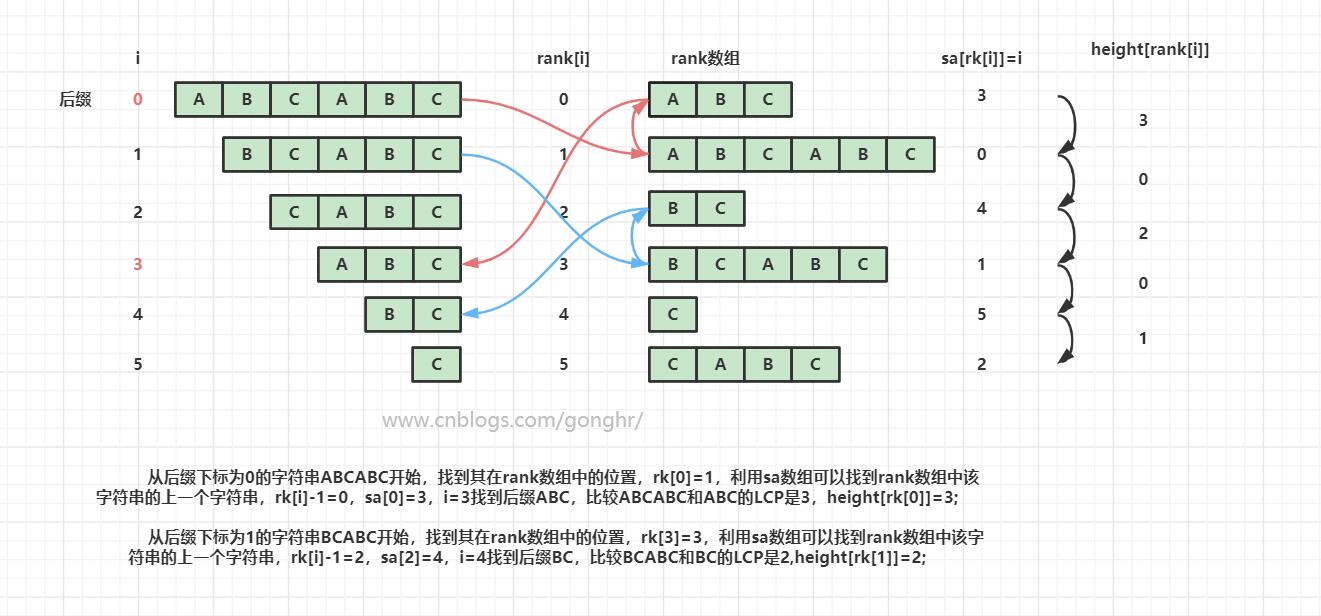
如果已经知道后缀数组中i与i+1的lcp为h,那么i代表的字符串与i+1代表的字符串去掉首字母后的lcp为h-1.
根据这个我们可以发现,如果知道i与后缀数组中在它后一个的lcp为k,那么它去掉首字母后的字符串与其在后缀数组中的后一个的lcp大于等于k-1.
即height[rk(i+1)] >= height[rk(i)]-1
例如对于字符串abcefabc,我们知道abcefabc与abc的lcp为3.
那么bcefabc与bc的lcp大于等于3-1.
利用这一点就可以O(n)求出高度数组。
public static int[] getHeight(String src, Suff[] sa) {
int strLength = src.length();
int[] rk = new int[strLength];
//将rank表示为不重复的排名即0~n-1
for (int i = 0; i < strLength; i++) {
rk[sa[i].index] = i;
}
int[] height = new int[strLength];
int k = 0;
for (int i = 0; i < strLength; i++) {
int rk_i = rk[i]; //i后缀的排名
if (rk_i == 0) {
height[0] = 0;
continue;
}
int rk_i_1 = rk_i - 1;
int j = sa[rk_i_1].index;//j是i串字典序靠前的串的下标
if (k > 0) k--;
for (; j + k < strLength && i + k < strLength; k++) {
if (src.charAt(j + k) != src.charAt(i + k))
break;
}
height[rk_i] = k;
}
return height;
}
参考资料
本文作者:gonghr
本文链接:https://www.cnblogs.com/gonghr/p/15121450.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步