201871010107-公海瑜 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 班级博客 |
| 这个作业要求链接 | 作业要求 |
| 我的课程学习目标 | 1.体验软件项目开发中的两人合作,练习结对编程(Pair programming)。 2.掌握Github协作开发程序的操作方法。 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.通过阅读《现代软件工程—构建之法》第3-4章内容,理解并掌 握了代码风格规范、代码设计规范、代码复审、结对编程概念。 2.通过结对进行软件项目合作开发,体会到了结对编程的真正益处。 |
| 结对方学号-姓名 | 201871010101-陈来弟 |
| 结对方本次博客作业链接 | 结对方本次博客作业链接 |
| 本项目Github的仓库链接地址 | Github仓库链接 |
-
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
“代码规范”可以分成两个部分:
(1)代码风格规范。主要是文字上的规定,看似表面文章,实际上非常重要。
-
代码风格的原则是:简明,易读,无二义性。
-
对于缩进、行宽、括号、分行、命名、下划线、注释、大小写以及断行与空白的{}行的处理。
-
有清晰的断行和分行;命名应该遵循规则,简洁易懂。
(2)代码设计规范。牵涉到程序设计、模块之间的关系、设计模式等方方面面,这里有不少与具体程序设计语言息息相关的内容(如C/C++/Java/C#),但是也有通用的原则,
这里主要讨论通用的原则。
代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计、模块之间的关系、设计模式等方方面面,这里有不少与具体程序设计语言息息相关的内容(如C、C++、Java、C#),但是也有通用的原则,这里主要讨论通用的原则。
-
函数。只做一件事,但是要做好。函数最好有单一的出口,为了达到这一目的,可以使用goto。
-
错误处理。参数都要验证其正确性及断言的正确使用等规范等。
代码复审:
- 复审的形式:

- 复审的目的:
(1)找出代码的错误。如:
a. 编码错误,比如一些能碰巧骗过编译器的错误。
b. 不符合项目组的代码规范的地方。
(2)发现逻辑错误,程序可以编译通过,但是代码的逻辑是错的。
(3)发现算法错误,比如使用的算法不够优化。
(4)发现潜在的错误和回归性错误——当前的修改导致以前修复的缺陷又重新出现。
(5)发现可能改进的地方。
(6)教育(互相教育)开发人员,传授经验,让更多的成员熟悉项目各部分的代码,同时熟悉和应用领域相关的实际知识。
(7)在代码复审中的提问与回应能帮助团队成员互相了解。在一个新成员加入一个团队的时候,代码复审能非常有效地帮助新成员了解团队的开发策略、编程风格及工作流程。
- 代码复审核查表:
1.概要部分
(1)代码能符合需求和规格说明么?
(2)代码设计是否有周全的考虑?
(3)代码可读性如何?
(4)代码容易维护么?
(5)代码的每一行都执行并检查过了吗?
2.设计规范部分
(1)设计是否遵从已知的设计模式或项目中常用的模式?
(2)有没有硬编码或字符串/数字等存在?
(3)代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到Win64)?
(4)开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现?
(5)有没有无用的代码可以清除?(很多人想保留尽可能多的代码,因为以后可能会用上,这样导致程序文件中有很多注释掉的代码,这些代码都可以删除,因为源代码控制已经保存了原来的老代码。)
3.代码规范部分
(1)修改的部分符合代码标准和风格么?
4.具体代码部分
(1)有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常?
(2)参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数?
(3)边界条件是如何处理的?Switch语句的Default是如何处理的?循环有没有可能出现死循环?
(4)有没有使用断言(Assert)来保证我们认为不变的条件真的满足?
(5)对资源的利用,是在哪里申请,在哪里释放的?有没有可能导致资源泄露(内存、文件、各种GUI资源、数据库访问的连接,等等)?有没有可能优化?
(6)数据结构中是否有无用的元素?
5.效能
(1)代码的效能(Performance)如何?最坏的情况是怎样的?
(2)代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C#中string 的操作是否能用StringBuilder来优化)?
(3)对于系统和网络调用是否会超时?如何处理?
6.可读性
代码可读性如何?有没有足够的注释?
7.可测试性
代码是否需要更新或创建新的单元测试?
还可以有针对特定领域开发(如数据库、网页、多线程等)的核查表。
结对编程:
角色:驾驶员:控制键盘输入; 领航员:起到领航、提醒的作用。
每人在各自独立设计、实现软件的过程中不免要犯这样那样的错误。在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。这样,程序中的错误就会少得多,程序的初始质量会高很多,这样会省下很多以后修改、测试的时间。具体地说,结对编程有如下的好处:
(1)在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。
(2)对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。
(3)在心理上, 当有另一个人在你身边和你紧密配合, 做同样一件事情的时候, 你不好意思开小差, 也不好意思糊弄。
(4)在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。
-
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价,具体要求如下:
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。

(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
-
任务3:采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
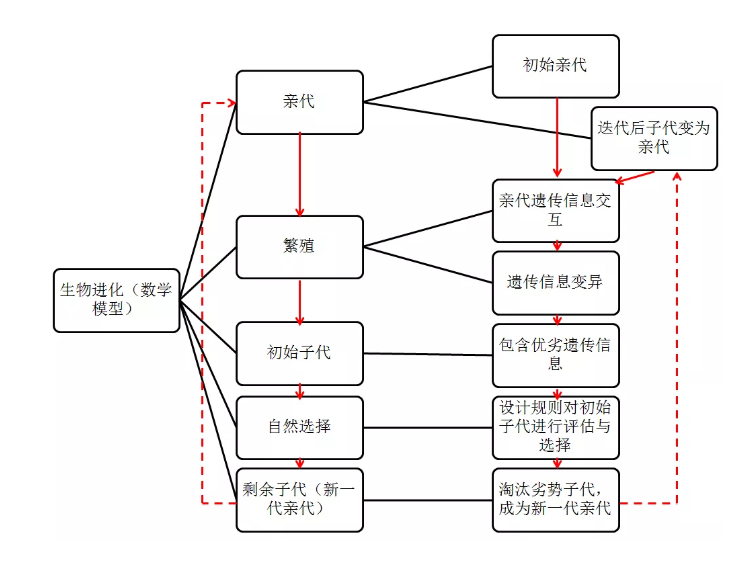
遗传算法:
- 定义:遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
- 执行过程:遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码。
初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
- 过程图解:

- 算法流程:
- 常用选择算子:
(1)轮盘赌选择(Roulette Wheel Selection):是一种回放式随机采样方法。每个个体进入下一代的概率等于它的适应度值与整个种群中个体适应度值和的比例。选择误差较大。
(2)随机竞争选择(Stochastic Tournament):每次按轮盘赌选择一对个体,然后让这两个个体进行竞争,适应度高的被选中,如此反复,直到选满为止。
(3)最佳保留选择:首先按轮盘赌选择方法执行遗传算法的选择操作,然后将当前群体中适应度最高的个体结构完整地复制到下一代群体中。
(4)无回放随机选择(也叫期望值选择Excepted Value Selection):根据每个个体在下一代群体中的生存期望来进行随机选择运算。方法如下:
1)计算群体中每个个体在下一代群体中的生存期望数目N。
2)若某一个体被选中参与交叉运算,则它在下一代中的生存期望数目减去0.5,若某一个体未 被选中参与交叉运算,则它在下一代中的生存期望数目减去1.0。
3)随着选择过程的进行,若某一个体的生存期望数目小于0时,则该个体就不再有机会被选中。
(5)确定式选择:按照一种确定的方式来进行选择操作。具体操作过程如下:
1)计算群体中各个个体在下一代群体中的期望生存数目N。
2)用N的整数部分确定各个对应个体在下一代群体中的生存数目。
3)用N的小数部分对个体进行降序排列,顺序取前M个个体加入到下一代群体中。至此可完全确定出下一代群体中M个个体。
(6)无回放余数随机选择:可确保适应度比平均适应度大的一些个体能够被遗传到下一代群体中,因而选择误差比较小。
(7)均匀排序:对群体中的所有个体按期适应度大小进行排序,基于这个排序来分配各个个体被选中的概率。
(8)最佳保存策略:当前群体中适应度最高的个体不参与交叉运算和变异运算,而是用它来代替掉本代群体中经过交叉、变异等操作后所产生的适应度最低的个体。
(9)随机联赛选择:每次选取几个个体中适应度最高的一个个体遗传到下一代群体中。
(10)排挤选择:新生成的子代将代替或排挤相似的旧父代个体,提高群体的多样性。
PSP流程:
| PSP | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 8 | 30 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 8 | 30 |
| Development | 开发 | 298 | --- |
| Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| Design Spec | 生成设计文档 | 15 | 25 |
| Design Review | 设计复审 (和同事审核设计文档) | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 5 |
| Design | 具体设计 | 35 | --- |
| Coding | 具体编码 | 155 | --- |
| Code Review | 代码复审 | 15 | --- |
| Test | 测试(自我测试,修改代码,提交修改) | 45 | --- |
| Reporting | 报告 | 9 | 11 |
| Test Report | 测试报告 | 3 | --- |
| Size Measuremen | 计算工作量 | 3 | 2 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 3 | 4 |
结对讨论照片:

实验总结:
通过这次实验理解和学习了代码的风格规范和设计规范,并对复审有了一定的了解。通过结对编程,我切实感受到了两人合作带来的1+1>2的效果,一如两个和尚挑水喝,远比一人担水效率高。在软件开发的过程中,两人一同进行设计前的需求分析等的意见和看法交换,就有了三种思路,大大提高了软件开发的效率。其次,结对还可以减少软件中的错误与漏洞。在测试过程中,和结对伙伴可以分饰两角:开发者和使用者,可有效发现软件存在的问题和漏洞,提高软件项目的人机交互体验。但是,由于我们编程能力都不好,所以,任务完成得不是很好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号