

Zookeeper学习(一) 概述
0. 前言
前段时间在工作中参与了一个分布式项目的开发,其中一个重要的模块就是Zookeeper。可以说这个项目及其之后的一段学习让我找到了自己的兴趣点,自己最近也学习了一些Zookeeper的知识,在这里也把自己学到的和一些思考写下来~
1. 分布式协调
分布式协调是用来解决分布式环境中多个进程(多机环境)中的同步控制问题的一门技术。通过分布式协调,可以让各个进程有序的访问部分资源,防止多个进程无序修改造成“脏数据”。这在某种程度上和实现线程安全有异曲同工之妙。
有一张非常经典的图如下可以解释为什么需要分布式协调服务:
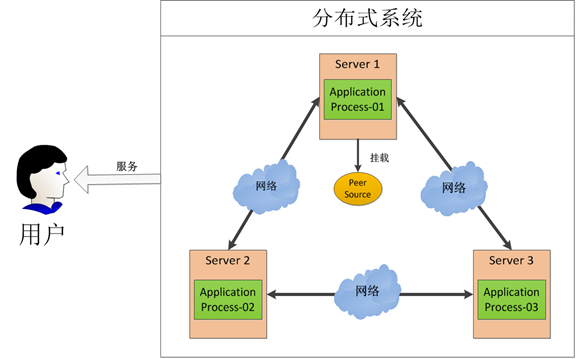
如果三台机器上的三个进程都要访问同一个资源,不同的任务在各个机器上单独处理,处理结束后给用户提供统一的接口,这是一个典型的简单的分布式系统。在分布式环境中,三台机器如何去访问公共资源,这时必须要有一个类似控制中心的地方给Peer source加上“锁”来保证同时只有一个进程在访问,当进程处理完相应的任务后就释放这个“锁”,这时其他的进程可以通过竞选机制获得对资源的使用。这个过程中核心的部分其实就是如何实现分布式环境下的锁,即分布式锁,而这个过程也是分布式协调技术的核心模块。
实现分布式锁的难点在于相比单机环境,分布式环境会有网络的依赖。在如上的环境中,假如1,2两台机器的进程同时发起了对资源的请求,这个时候谁能获得资源的使用权呢?假如1获得了使用权后,1上的进程出现了宕机等其他问题这时应该怎么处理呢?等等情况在分布式环境下都是非常容易出现的,所以分布式环境下的协调是很重要的。
2. Zookeeper介绍
Zookeeper官网上对其的介绍是:
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don't have to write them from scratch.
总的来说,zk是一个高性能的,简单的,有序的,可复制的分布式协调应用。它可以用在很多不同的服务像统一命名,配置管理,集群管理,共享锁等等场景。在真实的场景中,随着分布式系统中各个子系统的拆分,系统地复杂性也急剧增加,而为了让它们提供统一服务,必须利用独立的服务来协调它们,zk很适用于这种场景。
Zookeeper可以说是一个分布式的文件系统(作为文件系统功能稍弱,但是zookeeper设计之初就不是为了管理文件)。Zk内部又较复杂的选举算法,通过各个节点的选举可以避免单点故障。而且就算所有zk节点都挂掉,由于zk有文件系统的特点,在某种程度上可以保留数据,减小损失。且zk内部的版本的概念也可以帮助实现锁的一些功能。
根据Zookeeper的官网描述,zookeeper有以下几个特点:
-
简单:Zookeeper通过一个共享的命名空间(文件系统)将所有的分布式环境下的进程管理起来。在Zookeeper中,其文件系统由znode组成,每一个znode就类似操作系统中的目录,并且可以在znode中存储一些基础的信息(小于1M)。
-
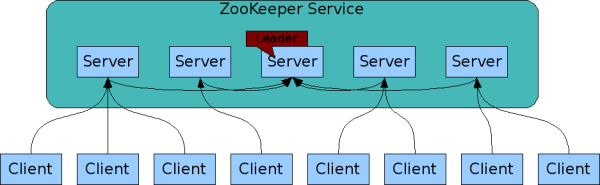
可复制:zookeeper可以部署在集群上,每个机器上的继承都知道互相的存在,并在内存db中维护状态表和一些日志等。只要有超过一半的机器可以使用,那么zookeeper的服务就是可用的。
如下图所示,zookeeper的客户端通过tcp连接到服务端之后会保持连接,通过这个连接来发送请求,获得watch的event,保持心跳等等,如果服务端挂了,客户端也能切换到其他server。
-
有序:Zookeeper会有一个数字来表示zookeeper的事务版本。通过这个版本可以保持操作的有序性。
-
高速:Zookeeper比较适合有大量读取的业务(读:写 10:1),针对这些业务zookeeper的速度是很快的。而且zookeeper可以部署在多台机器上。
Zookeeper适用的部分场景有:
- 统一命名:在分布式系统中,设计一套详细的命名规则是十分重要的。Zookeeper内部的结构(ZNode)能够满足生成唯一名称的任务,而且也不需要和任何实体资源绑定,非常灵活易用。并且,利用统一命名的特性,可以实现分布式锁。
- 配置管理:由于Zookeeper是一个独立的管理模块,所以可以把分布式系统的一些公用配置信息放在ZK上,并让子系统对ZK设置Watch(zk的消息通知机制),这样配置修改时所有模块可以获得即时通知并修改。
- 集群管理:就如同配置管理一样,集群中每个服务可以把各自的状态注册到ZK上。一旦某些机器失效或者增加了机器,那么其他机器可以及时获得通知,但是这个过程中也会有一些问题如羊群效应等,在设置集群管理的时候需要特别注意watch的设置。
- 共享锁:利用Zookeeper实现共享锁也是基于统一命名和集群管理的服务的,利用zk生成临时节点命名的特点在每次任务分配的时候可以让符合规则的节点获得对资源的使用权。
其实上面zookeeper的使用场景在绝大部分情况下都是混合使用的,各个场景其实会有一些依赖的关系。在后面会详细介绍zookeeper实现上面功能的姿势!
Zookeeper的数据模型
在之前有提到,zookeeper的基本数据模型是znode,由多个znode组成一个完成的文件系统。znode相比于普通操作系统中的文件系统来说兼具文件和目录的特点。首先,znode的标识是类似于文件系统中的路径组成的(由反斜杠和目录名组成),同时,znode中可以存储很多信息,例如原信息,ACL,时间戳,版本id等。总的来说,znode包含的信息有三类:
- 自己的状态(版本,创建时间等):
- Zxid:致使ZooKeeper节点状态改变的每一个操作都将使节点接收到一个Zxid格式的时间戳,并且这个时间戳全局有序且唯一。如果有两个zxid,且第一个小于第二个,则表明第二个zxid对应的操作晚于第一个发生。Zxid共有三种:cZxid:节点创建时间对应的zxid格式的时间戳;mZxid:最近一次修改时间对应的zxid格式的时间戳;pZxid:该节点或子结点最近一次修改时间对应的zxid格式的时间戳,与孙子节点无关!
- version:版本号也是一个数字id,每一个操作都会导致版本号增加。每个znode会有三个version: version:节点数据版本号;cversion:子节点版本号; aversion: 节点ACL版本号。
- time: ctime: 节点被创建的时间; mtime: 节点被修改的时间。
- ephemeralOwner: 临时节点独有的属性,值为节点拥有者的会话ID;非临时节点这个属性为0。
- datalength: 节点数的长度。
- numChildren: 子节点长度。
- 关联数据
- 孩子节点
但是对于znode来说,我们不能像普通的文件一样打开文件编辑这样的操作。具体znode命名系统如下:
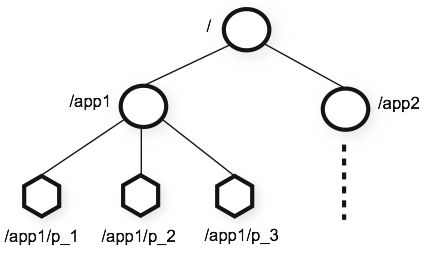
znode具有原子性操作,每个znode的数据将被原子性地读写,读操作会读取与znode相关的所有数据,写操作会一次性替换所有数据。
同时,在zookeeper中,共有两种类型的znode:
- 临时节点:
- 该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。
- 临时节点不可以有孩子节点。
- 临时节点可以是sequential和普通两种类型,如果是sequential的,那么在路径结尾会有一个递增的唯一的数字。数字总共有10位,且超过2^32-1时,计数器会溢出。
- 永久节点:
- 生命周期不依赖会话,一直存在。只有客户端显示地去删除时才会被删除。
ZNode的相关操作
和znode相关的操作主要有以下几种:
- create 创建znode,但是不能越级创建,例如zookeeper中只有“/”节点,那么不能直接创建“/A/B”这个节点,必须要先创建"/A",然后创建"/A/B"。
- delete 删除znode。同样的,删除znode不能删除有子节点的节点,必须要先删除完子节点才可以。
- exists 判断节点是否存在,若节点存在,会获得其数据。
- getACL/setACL 设置ACL
- getChildren 获取znode的所有节点
- getData/setData 获取/设置Znode相关数据
- sync 显示地同步客户端与服务期端的znode状态
更新ZooKeeper操作是有限制的。delete或setData必须明确要更新的Znode的版本号,我们可以调用exists找到。如果版本号不匹配,更新将会失败。
更新ZooKeeper操作是非阻塞式的。因此客户端如果失去了一个更新(由于另一个进程在同时更新这个Znode),他可以在不阻塞其他进程执行的情况下,选择重新尝试或进行其他操作。
Watch机制
zookeeper的watch机制是zookeeper里非常非常非常(重要的话说三遍!)重要的一个机制。大部分基于zk的工作都需要依赖watch机制。zookeeper可以为所有的读操作设置watch,在上面对应的操作有exists,getChildren和getData。
!!!Watch的触发是一次性的,当watch被触发后,如果不重新设置触发,那么下次这个znode发生变化时客户端是不会收到通知的。而Zookeeper中的所有watch都是异步发送到客户端,并且zookeeper本身会提供有序的一致性保证!理论上,客户端接收watch事件的时间要快于其看到watch对象状态变化的时间。
Zookeeper watch类型:
- data watch:getData和exists负责数据的watch,对这两个操作加watch可以获得节点数据变化的通知;
- child watch: getChildren负责孩子watch,对getChildren加watch可以获得子节点变化的通知。
znode的变化与对应操作的watch触发机制如下表中所示:

在实际的程序中,就算对每个操作都添加了watch,我们也可以通过表中所示的znode事件类型来知道究竟是哪一类的问题,从而针对znode不同类型的操作采取不同类型的解决方案。
在客户端从服务器断开连接时,watch理所当然会失效,但是当客户端重连时,客户端会重新注册watch。
p.s. 对于zookeeper客户端和服务器端的连接,有几点需要注意:
- zookeeper客户端和服务器端的连接状态很有多种情况,这个目前我还是有些模棱两可的地方,但是后面会补上这方面的具体解释。
- 对于节点的事件,一定要注意watch是一次性的,需要不断注册,特别是还有可能发生事件丢失的情况。
Reference
http://www.cnblogs.com/sunddenly/p/4033574.html
https://blog.csdn.net/tswisdom/article/details/41522069
https://zookeeper.apache.org/doc/current/index.html
https://zookeeper.apache.org/doc/current/zookeeperOver.html
