
宫立秋20200917-2 词频统计
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
词频统计 SPEC
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
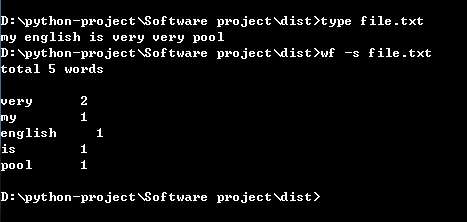
>type test.txt My English is very very pool. >wf -s test.txt total 5 very 2 my 1 english 1 is 1 pool 1
为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2
次的very计数1次。
因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
此功能完成后你的经验值+10.
git代码地址:https://github.com/gongbaby/gong
coding.net 代码:https://gongbaby.coding.net/public/wf/gong/git/files
难点:对文件的打开以及用到的参数不记得了,还有就是找到文件的位置,这个之前纠结了好久,最开始我是用相对路径做的,但是这样在功能二和功能三的时候就不知道怎么做了,在就是做到对单词的分割,不知道如何进行分割,然后请教了上届的师兄,了解到用到split函数。
重点:运用了collections模块中的counter字符串的统计
代码:
def texto(file_dir): total = 0 i = 0 patt = re.compile("\w+") count = collections.Counter(patt.findall( open(file_dir, 'rt').read())) for key, value in count.most_common(): if count[key] > 1: i = i + 1 file = open(file_dir, "r") for line in file.readlines(): word = line.split(" ") total += len(word) print("total", total - i) for key, value in count.most_common(): print(key,value)
难点:在功能一的基础上,只需稍加改进功能二
重点:利用了正则表达式对字母,数字,符号进行匹配,变成空字符串。把所有单词变成小写
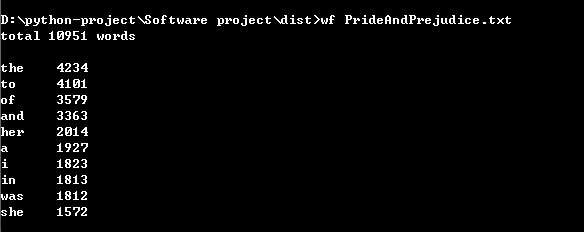
功能二代码:
def texttw(file_dir_name): file_dir = file_dir_name + ".txt" total = 0 i = 0 patt = re.compile("\w+") count = collections.Counter(patt.findall( open(file_dir, 'rt').read())) for key, value in count.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") word = re.findall(r'[a-z0-9^-]+', file.read().lower()) total = len(word) print("total", total - i,end="") print(" words") for key, value in count.most_common(10): print(key, value)
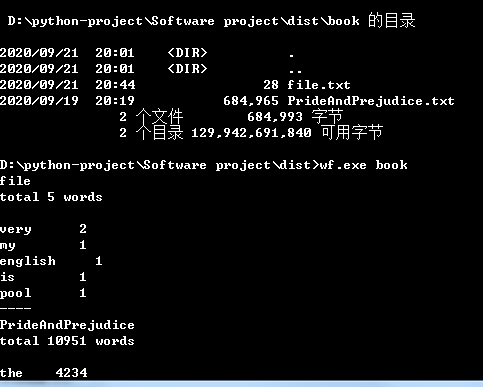
# 重点难点:利用os 显示出全部的文件夹,以及找到文件的目录file_dir = "failpath" + file_name。
功能三代码:
def textth(file_folder):
file_names = os.listdir(file_folder) for file_name in file_names: print(file_name) for file_name in file_names: file_dir = "failpath" + file_name total = 0 i = 0 patt = re.compile("\w+") count = collections.Counter(patt.findall( open(file_dir, 'rt').read())) for key, value in count.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") for line in file.readlines(): word = line.split(" ") total += len(word) print(file_dir) print("total", total - i) for key, value in counts.most_common(10): print(key, value) pass

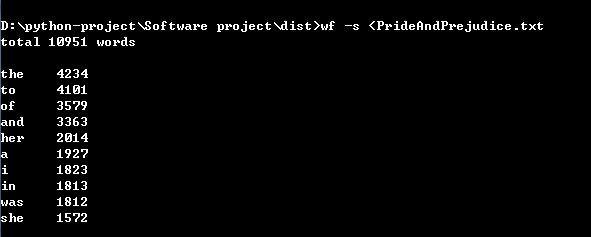
#重点,难点:重定向的理解
功能4代码:
def textf(strTxt): regEx = re.compile(u'\t|\n|\.|-|;|\)|\(|\?|"') txtStr = re.sub(regEx, '', strTxt).lower().split() printsort(txtStr) return def printsort(strList, isfile = True): strDict = { } for str in strList: strDict[str] = strDict.get(str, 0) + 1 strDictSort = sorted(strDict.items(), key = lambda item : item[1], reverse = True) print("total %d words \n" % len(strDictSort)) if(len(strDictSort) > 10): for i in range(10): print("{:5} {:5}".format(strDictSort[i][0], strDictSort[i][1])) if(isfile == False): print("----") else: for i in range(len(strDictSort)): print("{:5} {:5}".format(strDictSort[i][0], strDictSort[i][1])) if(isfile == False): print("----") return
psp
| 准备工作 | 预计花费时间/min | 实际花费时间/min | 时间差/min | 原因 |
| 安装pycharm | 30 | 40 | 10 | 总是让360不知道给我拦截到哪里去了,以为是病毒,在后续下载别的软件也有过这个情况,后来就给它卸载了,重新安了一个火绒 |
| 功能1 | 60 | 254 | 194 | 看了整体的题目,实在不懂什么意思,后来一步一步的做,在后期因为缩进吃了很多亏,因为最开始没注意这个问题,就很多错误。 |
| 功能2 | 60 | 45 | 15 | 在功能一的基础上,就相对好做了,因为我传入的数据不是很大,python也能够支持,只需要处理-s的命令 |
| 功能3 | 60 | 236 | 176 | 最开始没有理解目录是如何输入的,也没理解如何在控制台将目录显示出来,后来参考了同学的功能,也问了同学,理解了过程,前期浪费了时间,后期在文件目录在控制台的输入也浪费了很多时间。因为这两个不在同一文件夹中,总是显示找不到的错误。 |
| 功能4 | 60 | 126 | 66 | 对于重定向的概念完全不理解,后来问了好多同学。 |

