InternLM第四期实战-L1-LlamaIndex+InternLM RAG
LlamaIndex+InternLM RAG 实践
教程链接:https://github.com/InternLM/Tutorial/tree/camp4/docs/L1/LlamaIndex
RAG概述
正式介绍检索增强生成(Retrieval Augmented Generation,RAG)技术以前,大家不妨想想为什么会出现这样一个技术。 给模型注入新知识的方式,可以简单分为两种方式,一种是内部的,即更新模型的权重,另一个就是外部的方式,给模型注入格外的上下文或者说外部信息,不改变它的的权重。 第一种方式,改变了模型的权重即进行模型训练,这是一件代价比较大的事情,大语言模型具体的训练过程,可以参考InternLM2技术报告。 第二种方式,并不改变模型的权重,只是给模型引入格外的信息。类比人类编程的过程,第一种方式相当于你记住了某个函数的用法,第二种方式相当于你阅读函数文档然后短暂的记住了某个函数的用法。

对比两种注入知识方式,第二种更容易实现。RAG 正是这种方式。它能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用了 LlamaIndex 框架。LlamaIndex 是一个上下文增强的 LLM 框架,旨在通过将其与特定上下文数据集集成,增强大型语言模型(LLMs)的能力。它允许您构建应用程序,既利用 LLMs 的优势,又融入您的私有或领域特定信息。
环境配置
使用 Cuda12.0-conda 镜像。
创建新的conda环境,conda create -n llamaindex python=3.10,命名为 llamaindex。
安装python 依赖包:pip install einops==0.7.0 protobuf==5.26.1。
安装 Llamaindex
conda activate llamaindex
pip install llama-index==0.11.20
pip install llama-index-llms-replicate==0.3.0
pip install llama-index-llms-openai-like==0.2.0
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-embeddings-instructor==0.2.1
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
下载 Sentence Transformer 模型
源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型)
cd ~
mkdir llamaindex_demo
mkdir model
cd ~/llamaindex_demo
touch download_hf.py
打开download_hf.py 贴入以下代码:
download_hf.py
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
然后,在 /root/llamaindex_demo 目录下执行该脚本即可自动开始下载:
cd /root/llamaindex_demo
conda activate llamaindex
python download_hf.py
下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。
使用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
之后使用时服务器即会自动使用已有资源,无需再次下载.
是否使用 LlamaIndex 前后对比
不使用 LlamaIndex RAG(仅API)
浦语官网和硅基流动都提供了InternLM的类OpenAI接口格式的免费的 API,可以访问以下两个了解两个 API 的使用方法和 Key。
浦语官方 API:https://internlm.intern-ai.org.cn/api/document
硅基流动:https://cloud.siliconflow.cn/models?mfs=internlm
新建一个python文件:touch test_internlm.py.
打开test_internlm.py 贴入以下代码:
test_internlm
from openai import OpenAI
base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = "sk-请填写准确的 token!"
model="internlm2.5-latest"
# base_url = "https://api.siliconflow.cn/v1"
# api_key = "sk-请填写准确的 token!"
# model="internlm/internlm2_5-7b-chat"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "xtuner是什么?"}],
)
for choice in chat_rsp.choices:
print(choice.message.content)
之后运行
conda activate llamaindex
cd ~/llamaindex_demo/
python test_internlm.py
我们向大模型提问:“xtuner是什么?”,结果为:

回答的效果并不好,并不是我们想要的xtuner。
使用 API+LlamaIndex
运行以下命令,获取知识库:
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
新建一个python文件:touch llamaindex_RAG.py
打开llamaindex_RAG.py贴入以下代码:
touch llamaindex_RAG
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)
之后运行
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_RAG.py
结果为:

借助RAG技术后,就能获得我们想要的答案了。
LlamaIndex web
首先安装依赖:pip install streamlit==1.39.0
新建一个python文件:touch app.py
打开app.py贴入以下代码:
app.py
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformer"
)
Settings.embed_model = embed_model
#用初始化llm
Settings.llm = llm
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
之后运行streamlit run app.py
进入以下网页,然后就可以开始尝试问问题了。

再次添加新的知识库,对比前后回答的不同:
RAG之前:
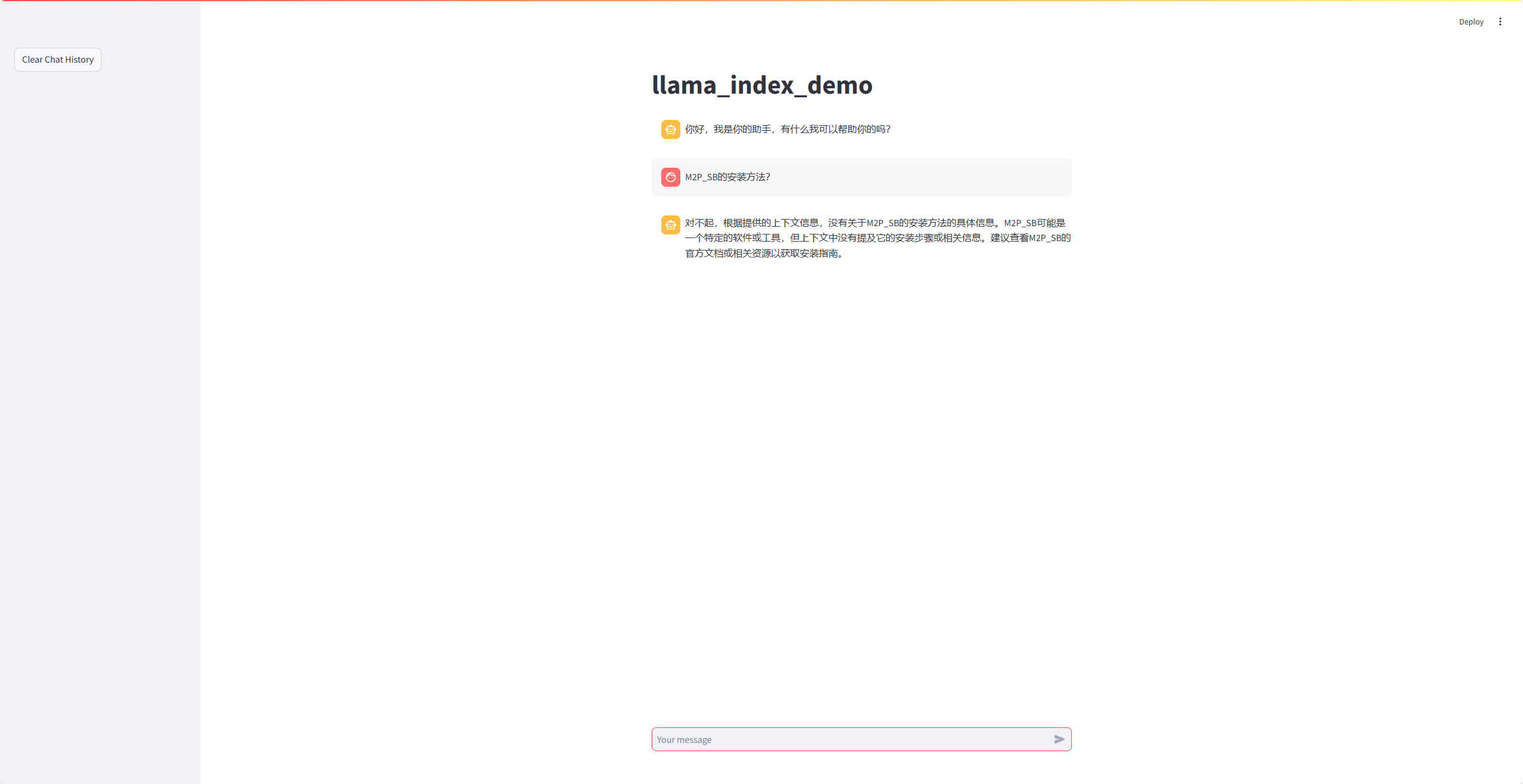
RAG之后:

将 Streamlit+LlamaIndex+浦语API的 Space 部署到 Hugging Face
首先在https://huggingface.co/上创建一个新的space,SDK选择streamlit,硬件就默认CPU。

创建好之后将它clone到本地:git clone https://huggingface.co/spaces/<user_name>/<repo_name>

按照上一小节的内容准备模型与数据集,并放在指定文件夹中。
通过pip freeze > requirments.txt记录所需的配置环境并写入txt文件中。
修改app.py文件中关于API_KEY的内容,最好是配置在space的环境中:

修改后的app.py为:
app.py
import os
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Get API_KEY in Env
api_key = os.getenv('INTERNLM_API_KEY')
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
# api_key = " your api_key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="./model/sentence-transformer"
)
Settings.embed_model = embed_model
#用初始化llm
Settings.llm = llm
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
huggingface会通过该文件启动应用。
完整的文件结构如下所示:
由于model文件较大,可以使用huggingface-cli lfs-enable-largefiles .将当前仓库配置为启用大文件上传功能。
注意,由于创建的space是cpu版本,配置文件requirment中有关于GPU版本的库需要修改或注释,如torch改为cpu版本,nvidia相关库不需要
model文件夹中onnx和openvino子文件夹也可以删除
使用git将本地仓库中的文件push到space。
git add .
git commit -m '...'
git push
space会根据requirments.txt自动下载所需的配置环境并启动应用:

对应的文件内容为:

最后实现对话。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号