
基于tf-idf的论文查重
基于tf-idf的论文查重
github地址:https://github.com/gomevie/gomevie/tree/main
| 这个作业属于哪个课程 | 广工计院计科34班软工 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 设计并实现一个论文查重算法,通过比较原文和抄袭版论文文件,计算并输出重复率。 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 700 | 730 |
| Development | 开发 | 200 | 150 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 60 | 60 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 40 | 30 |
| Test Repor | 测试报告 | 40 | 30 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 730 | 730 |
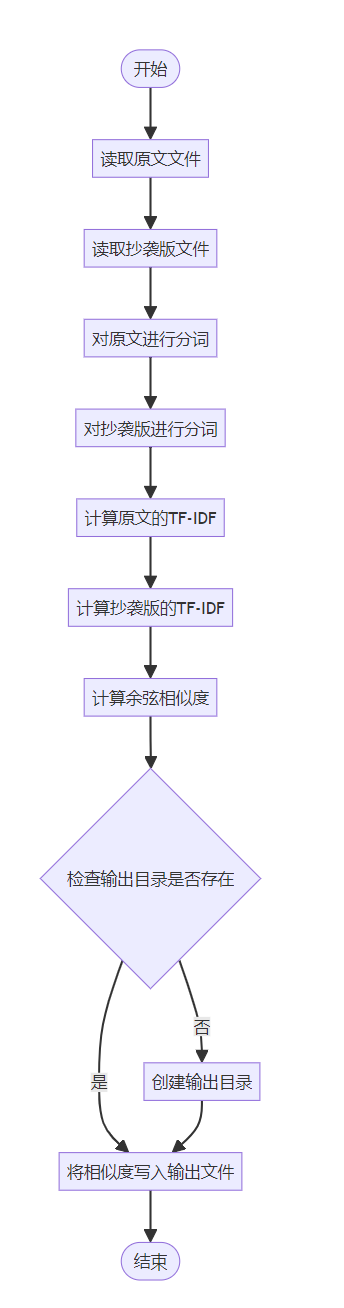
模块接口设计
数据处理模块
该模块负责处理输入和输出的文件。
read_file(file_path)函数
功能:读取文件内容。
输入:文件路径(字符串)。
输出:文件内容(字符串)。
异常处理:需要处理文件不存在或无法读取的异常。
write_output(file_path, similarity)函数
功能:将计算得到的相似度写入文件。
输入:文件路径(字符串),相似度(浮点数)。
输出:无(操作是写文件)。
异常处理:需要处理文件写入错误。
分析模块
该模块负责文本的分词和相似度计算。
tokenize(text)函数
功能:使用jieba进行中文分词。
输入:原始文本(字符串)。
输出:分词后的列表。
异常处理:处理文本为空或分词失败的情况。
calculate_similarity(original_tokens, plagiarized_tokens)函数
功能:计算两组分词的TF-IDF向量的余弦相似度。
输入:原文分词列表,抄袭版分词列表。
输出:相似度百分比(浮点数)。
异常处理:处理分词列表为空或TF-IDF计算失败的情况。
代码的独到之处
使用TF-IDF进行文本相似度计算:
利用TF-IDF(词频-逆文档频率)算法来转换文本数据为可以进行数学运算的向量形式,这是一种在文本挖掘中常用的技术,能够较好地反映文本的语义信息。
余弦相似度的应用:
通过计算两个向量之间的余弦相似度来评估文本间的相似性,这是一种有效衡量文本相似度的方法,特别是在处理高维数据时。
jieba分词的利用:
对中文文本进行有效分词,jieba是中文自然语言处理中广泛使用的库,其准确性和效率都经过了实践的检验。
异常处理和环境检查:
在写入输出文件之前检查目录是否存在,如果不存在则创建,这种对运行环境的检查可以避免常见的文件操作错误。
命令行参数的使用:
通过命令行参数接收文件路径,使得程序更加灵活,易于集成到其他系统或工作流中。
代码实现了一个结构清晰、模块化良好的论文查重系统。它使用了先进的文本处理技术(如TF-IDF和余弦相似度),并结合了有效的中文分词工具(jieba),这些都是文本相似度分析中的关键技术。代码的模块化和面向对象的设计提高了其可维护性和可扩展性,而异常处理和环境检查则增强了程序的健壮性。
流程图:
性能分析
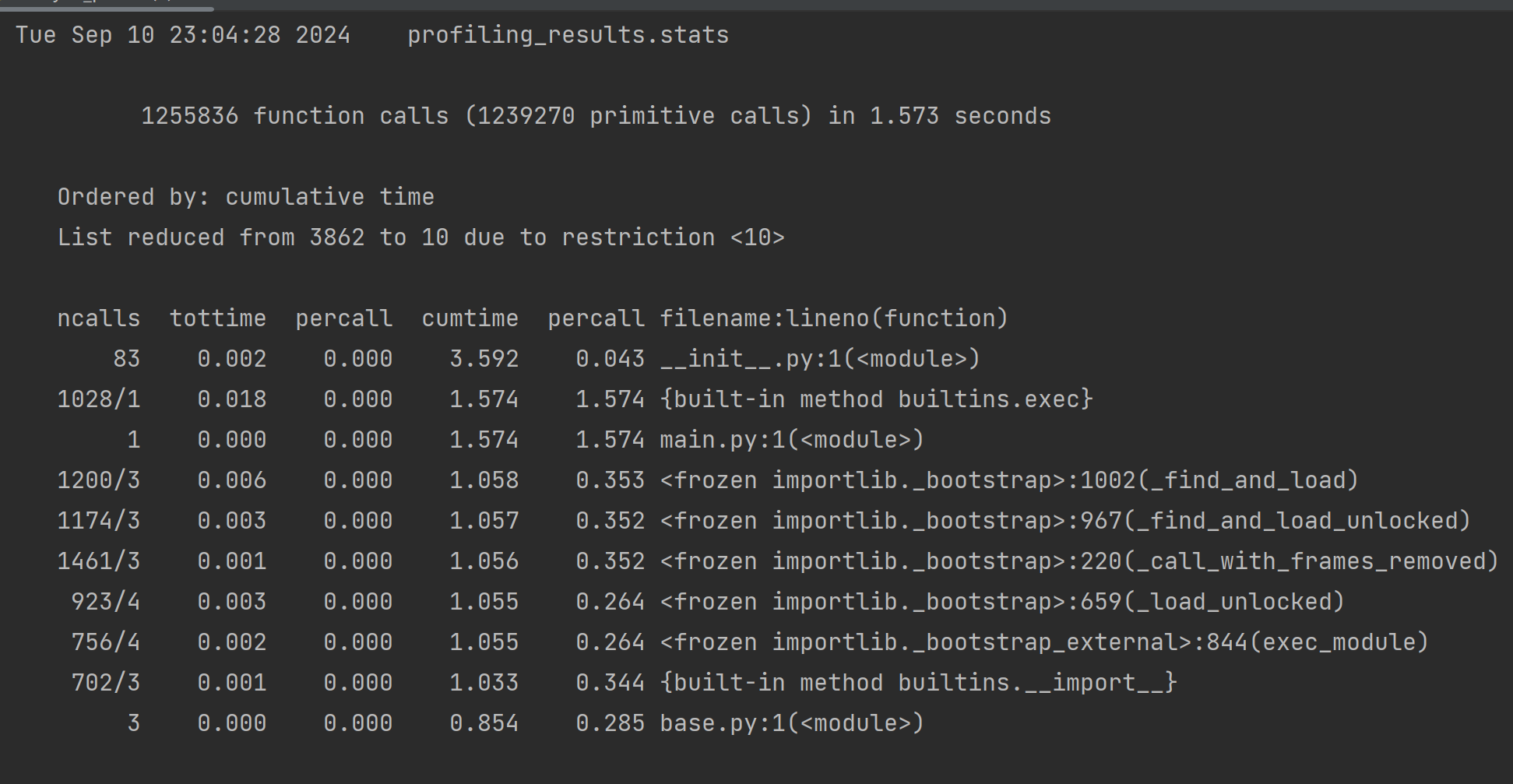
在运行了analye_pstats.py后可以获取累计时间前十的函数并打印详细信息。
终端运行 snakeviz profiling_results.stats后可以获取可视化结果:
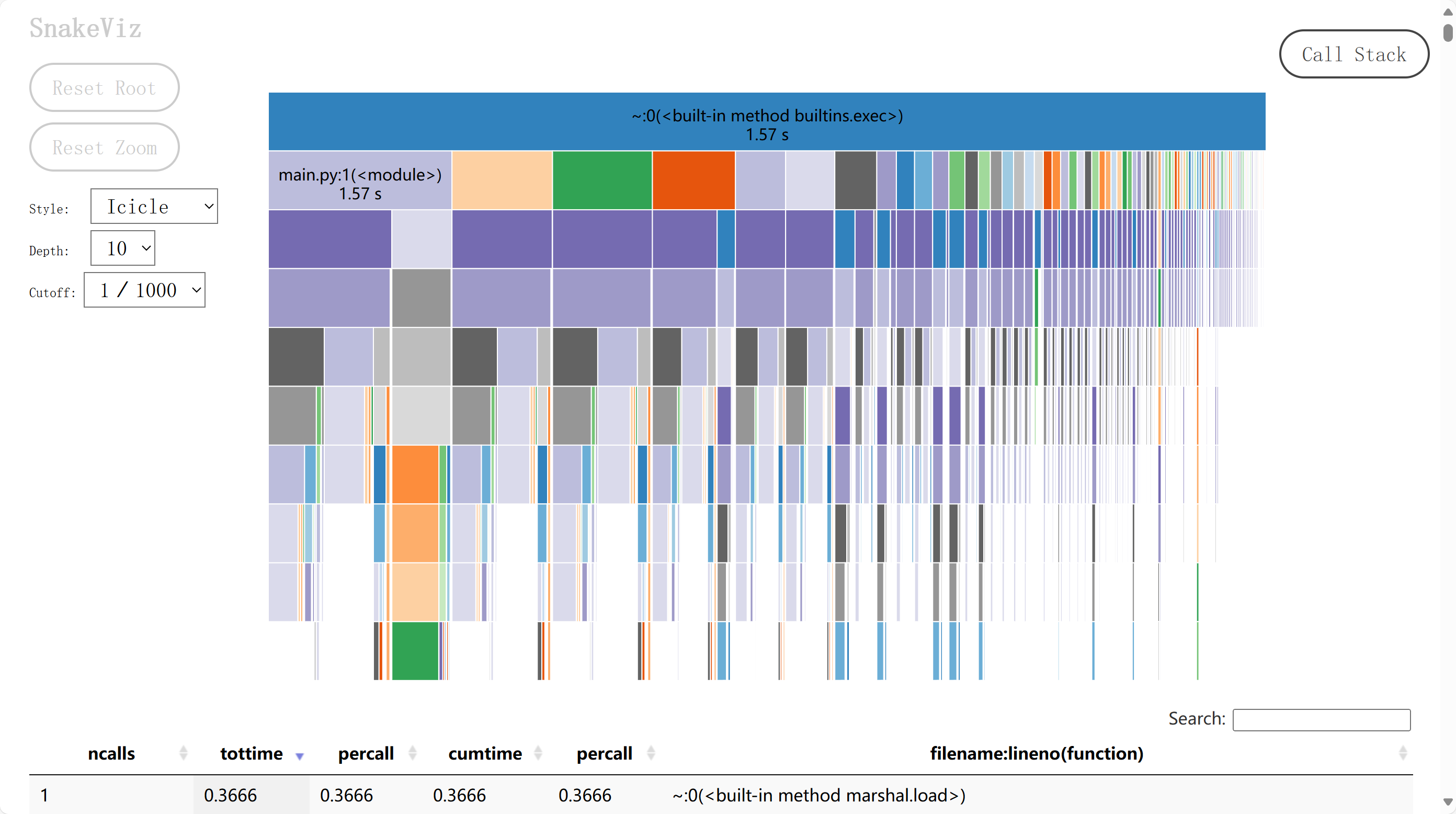
概览
总运行时间:程序的总运行时间为 1.57 秒。
调用栈深度:当前显示的调用栈深度为 10 层。
截止值:设置的截止值为 1/1000,这意味着只有超过总时间 0.1% 的函数才会显示。
性能数据
调用次数:1 次
总时间:0.3666 秒
每次调用时间:0.3666 秒
累计时间:0.3666 秒
这个内建方法的调用次数和每次调用时间表明它可能是一个性能热点。exec 方法通常用于执行动态的 Python 代码,这可能是在运行时编译和执行代码,这可能是一个耗时的操作。
main.py:1(
总时间:1.57 秒
这表示 main.py 的入口点(if name == "main":)的总运行时间。这个时间包括了所有从这个点开始的函数调用。
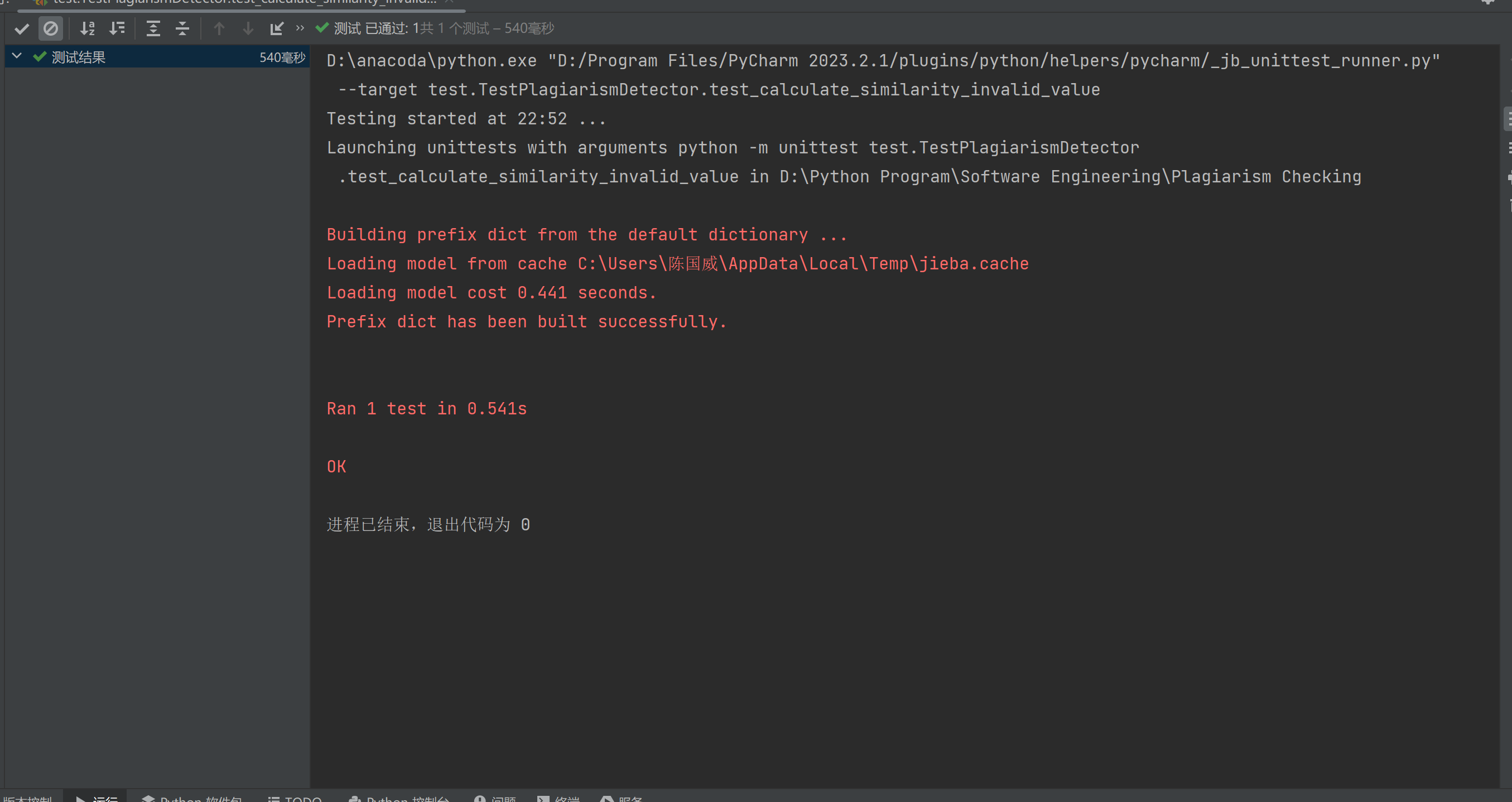
单元测试
测试用例名称:
test_calculate_similarity_invalid_value:这个测试用例的名称表明它旨在测试计算文本相似度时,对于非法或异常值的处理。
测试目标:
测试查重系统在遇到无效或非预期输入时的行为。这可能包括测试算法的鲁棒性,确保它能够处理异常情况,如非法的输入数据或计算过程中可能出现的错误。
测试方法:
使用了 unittest.mock.patch 来模拟 cosine_similarity 函数的行为。这是一种常见的测试技巧,用于在测试过程中控制和测试依赖项的行为,而不需要实际执行依赖项的代码。
测试执行:
测试通过模拟 cosine_similarity 函数返回一个固定的值(在这里是 np.array([[1.0]])),来测试当函数返回最大相似度(100%)时,查重系统是否能够正确处理并返回预期的结果。
测试结果:
测试运行成功,没有发现错误或异常,表明在模拟的条件下,查重系统能够正确处理输入并返回预期的输出。
异常处理
文件不存在(FileNotFoundError)
场景:当尝试读取一个不存在的文件时,会引发 FileNotFoundError。
原因:可能是因为文件路径错误、文件未创建或被删除。
处理:捕获此异常并提醒用户检查文件路径,可能需要提供正确的文件路径或创建文件。
文件读取权限问题(PermissionError)
场景:当程序尝试读取一个没有读取权限的文件时,会引发 PermissionError。
原因:可能是因为文件权限设置限制了当前用户的访问,或者文件正被另一个程序使用。
处理:捕获此异常并提醒用户检查文件权限或关闭占用文件的程序。
分词过程中的异常(如 jieba 内部错误)
场景:在使用 jieba 进行分词时,如果遇到无法处理的字符或内部错误,可能会引发异常。
原因:可能是因为输入文本包含特殊字符或编码问题。
处理:捕获异常并提醒用户检查输入文本,可能需要清洗数据或转换编码。
相似度计算中的异常
场景:在计算文本相似度时,如果输入数据格式不正确或存在其他问题,可能会引发异常。
原因:可能是因为向量数据不兼容或算法实现中的错误。
处理:捕获异常并检查输入数据的格式和有效性,确保数据适合进行计算。
写入文件时的权限问题(PermissionError)
场景:尝试写入一个没有写入权限的文件或目录时,会引发 PermissionError。
原因:可能是因为目录权限设置限制了当前用户的写入操作。
处理:捕获异常并提醒用户检查目录权限,可能需要更改权限或选择其他目录。
目录创建失败(OSError)
场景:当尝试创建一个目录,但因为路径错误、磁盘空间不足或其他系统错误而失败时,会引发 OSError。
原因:可能是因为路径无效、磁盘空间不足或文件系统错误。
处理:捕获异常并提醒用户检查路径和磁盘状态,可能需要清理磁盘空间或修复文件系统。
命令行参数不足(SystemExit)
场景:当程序期望的命令行参数数量不满足时,会引发 SystemExit。
原因:可能是因为用户忘记提供必要的参数。
处理:捕获异常并提醒用户检查命令行参数,提供正确的使用方法。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步