
深入浅出爬虫之道: Python、Golang与GraphQuery的对比
深入浅出爬虫之道: Python、Golang与GraphQuery的对比
本文将分别使用 Python ,Golang 以及 GraphQuery 来解析某网站的 素材详情页面 ,这个页面的特色是具有清晰的数据结构,但是DOM结构不够规范,无法通过单独的选择器定位页面元素,对页面的解析造成了一些曲折。通过这个页面的解析过程,深入浅出的了解爬虫的解析思想与这些语言之间的异同。
一、前言
在前言中,为了防止在后面的章节产生不必要的困扰,我们将会首先了解一些基本的编程理念。
1. 语义化的DOM结构
这里我们讲的语义化的DOM结构,不仅仅包括 语义化的html标签,也包括了语义化的选择器,在前端开发中应该注意的是,所有的动态文本都应该有单独的 html 标签包裹,并最好赋予其语义化的 class 属性或 id 属性,这在版本功能的迭代中,对前端和后端的开发都是大有裨益的,比如下面的HTML代码:
<div class="main-right fr">
<p>编号:32490230</p>
<p class="main-rightStage">模式:RGB</p>
<p class="main-rightStage">体积:16.659 MB</p>
<p class="main-rightStage">分辨率:72dpi</p>
</div>
这就是不够语义化的前端代码,32504070,RGB,16.659 MB,72dpi这些值都是动态属性, 会跟随编号的改变而改变,在规范的开发中,应该将这些 动态变化的属性,分别用 <span> 这类行内标签包裹起来,并赋予其一定的语义化选择器,在上面的HTML结构中大致可以推测出这是后端直接使用 foreach 渲染出的页面,这是不符合前后端分离的思想的,如果有一天他们决定使用 jsonp 或 Ajax 渲染这些属性, 由前端进行渲染,工作量无疑会上一个层次。语义化的DOM结构更倾向于下面这样:
<p class="main-rightStage property-mode">
模式:<span>RGB</span>
</p>
也可以将 property-mode 直接作为 span 的 class 属性,这样这些属性无论是后端渲染,还是前端动态渲染都减轻了产品迭代产生的负担。
2. 稳定的解析代码
在 语义化的DOM结构 之后,我们来谈谈稳定的解析代码, 对于下面的DOM结构:
<div class="main-right fr">
<p>编号:32490230</p>
<p class="main-rightStage">模式:RGB</p>
<p class="main-rightStage">体积:16.659 MB</p>
<p class="main-rightStage">分辨率:72dpi</p>
</div>
如果我们想要提取 模式 信息,当然可以采取下面的步骤:
- 选取
class属性中包含main-right的div - 选取这个
div中第二个p元素,取出其包含的文本 - 删除文本中的
模式:, 得到模式为RGB
虽然成功获取到了想要的结果,但是这样的解析方法,我们认为它是 不稳定的,这个不稳定是指 在其祖先元素、兄弟元素等自身以外的元素节点发生一定程度的结构改变时,导致解析错误或失败 的情况, 比如如果有一天在 模式 所在的节点之前增加了一个 尺寸 的属性:
<div class="main-right fr">
<p>编号:32490230</p>
<p class="main-rightStage">尺寸:4724×6299像素</p>
<p class="main-rightStage">模式:RGB</p>
<p class="main-rightStage">体积:16.659 MB</p>
<p class="main-rightStage">分辨率:72dpi</p>
</div>
那么我们之前的解析将会发生错误(什么?你觉得不可能发生这样的变动?请对比 Page1 和 Page2)。
那我们应该如何写出更稳定的解析代码呢,对于上面的DOM结构,我们可以有下面几种思路:
思路一: 遍历 class 属性为 main-rightStage的 p 节点,依次判断节点的文本是否以 模式 开头, 如果是, 取出其 : 后的内容,缺点是逻辑太多,不易维护且降低了代码可读性。
思路二: 使用正则表达式 模式:([A-Z]+) 进行匹配,缺点是使用不当可能造成效率问题。
思路三: 使用 CSS选择器中的 contains 方法,比如 .main-rightStage:contains(模式), 就可以选取文本中包含 模式,且 class 属性中包含 main-rightStage 的节点了。但缺点是不同语言和不同库对这种语法的支持程度各有不同,缺乏兼容性。
使用哪种方法,仁者见仁智者见智,不同的解析思路带来的解析的 稳定性、代码的 复杂程度、运行效率 和 兼容性 都是不同的, 开发者需要从各种因素中进行权衡, 来写出最优秀的解析代码。
二、进行页面的解析
在进行页面数据的抽取之前,首先要做的是明确我们需要哪些数据、页面上提供了哪些数据,然后设计出我们需要的数据结构。首先打开 待解析页面, 由于其最上方的 浏览量、收藏量、下载量等数据是动态加载的, 在我们的演示中暂时不需要,而这个页面右边的 尺寸、模式 等数据,通过上面 Page1 和 Page2 的对比,可以得知这些属性是不一定存在的,因此将它们一起归到 metainfo 中。因此我们需要获得的数据如下图所示:
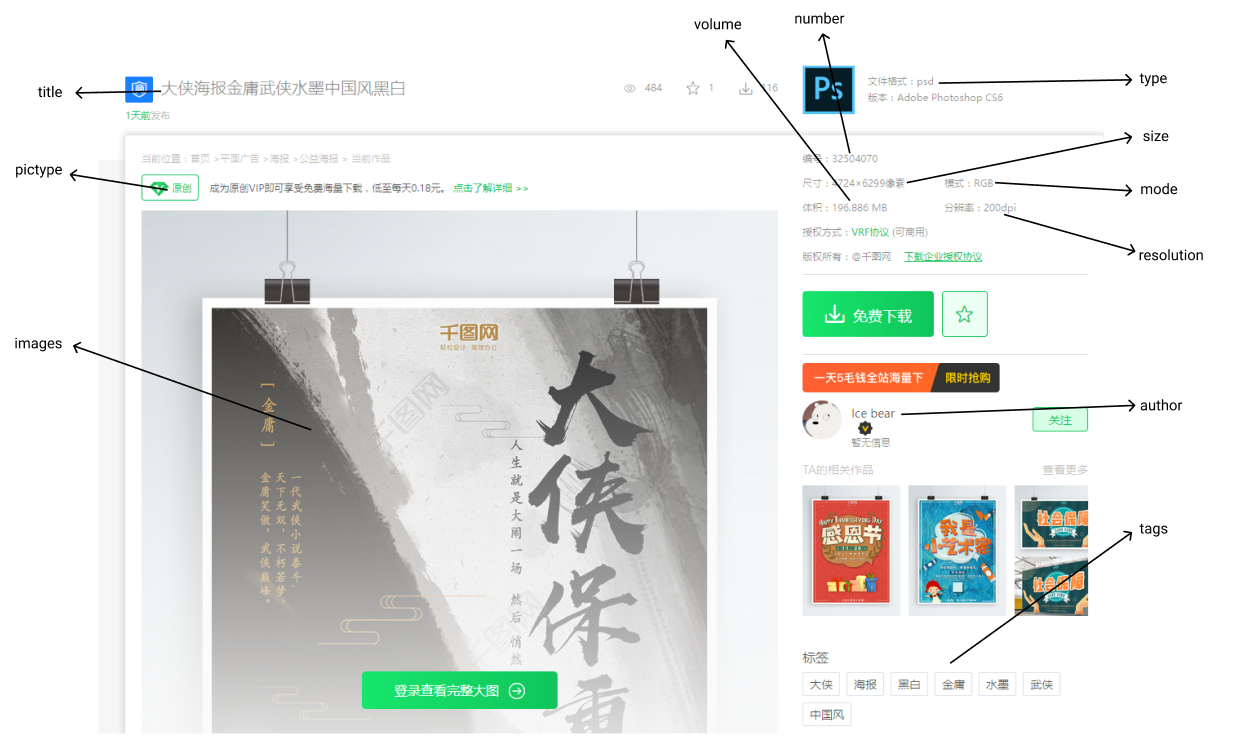
由此我们可以很快设计出我们的数据结构:
{
title
pictype
number
type
metadata {
size
volume
mode
resolution
}
author
images []
tags []
}
其中 size、volume、mode、resolution由于可能不存在,因此归入到了 metadata 下, images 是一个图片地址的数组,tags 是标签数组,在确定了要提取的数据结构,就可以开始进行解析。
使用Python进行页面的解析
Python库的数量非常庞大,有很多优秀的库可以帮助到我们,在使用Python进行页面的解析时,我们通常用到下面这些库:
- 提供
正则表达式支持的re库 - 提供
CSS选择器支持的pyquery和beautifulsoup4 - 提供
Xpath支持的lxml库 - 提供
JSON PATH支持的jsonpath_rw库
这些库在 Python 3 下获得支持的,可以通过 pip install 进行安装。
由于 CSS选择器 的语法比 Xpath 语法要更加简洁,而在方法的调用上,pyquery 比 beautifulsoup4 要更加方便,因此在 2 和 3 之间我们选择了 pyquery。
下面我们会以 title 和 type 属性的获取作为例子进行讲解, 其他节点的获取是同理的。首先我们先使用 requests 库下载这个页面的源文件:
import requests
from pyquery import PyQuery as pq
response = requests.get("http://www.58pic.com/newpic/32504070.html")
document = pq(response.content.decode('gb2312'))
下面使用Python进行的解析都将依次为前提进行。
1. 获取title节点
打开 待解析页面,在标题上右键, 点击 查看元素,可以看到它的DOM结构如下:
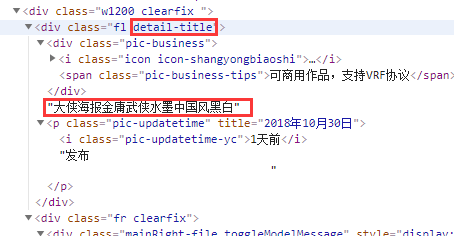
这时我们注意到, 我们想要提取出的标题文本 大侠海报金庸武侠水墨中国风黑白,并没有被html标签包裹,这是不符合我们上面提到的 语义化的dom结构 的。同时,使用CSS选择器,也是无法直接选取到这个文本节点的(可以使用Xpath直接选取到,本文略)。对于这样的节点,我们可以有下面两种思路:
思路一: 先选取其父元素节点, 获取其 HTML 内容,使用正则表达式, 匹配在 </div> 和 <p 之间的文本。
思路二: 先选取其父元素节点,然后删除文本节点之外的其他节点,再直接通过获取父元素节点的文本,得到想要的标题文本。
我们采取思路二,写出下面的Python代码:
title_node = document.find(".detail-title")
title_node.find("div").remove()
title_node.find("p").remove()
print(title_node.text())
输出结果与我们期望的相同, 为 大侠海报金庸武侠水墨中国风黑白。
2. 获取size节点
在 尺寸 上右键查看元素,可以看到下图所示的DOM结构:
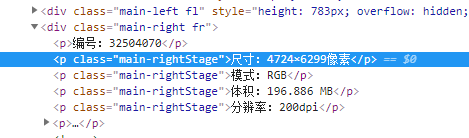
我们发现这些节点不具有语义化的选择器,并且这些属性不一定都存在(详见Page1 和 Page2 的对比)。在 稳定的解析代码 中我们也讲到了对于这种结构的文档可以采取的几种思路,这里我们采用正则解析的方法:
import re
context = document.find(".mainRight-file").text()
file_type_matches = re.compile("尺寸:(.*?像素)").findall(context)
filetype = ""
if len(file_type_matches) > 0:
filetype = file_type_matches[0]
print(filetype)
由于获取 size、volume、mode、resolution 这些属性,都可以采取类似的方法,因此我们可以归结出一个正则提取的函数:
def regex_get(text, expr):
matches = re.compile(expr).findall(text)
if len(matches) == 0:
return ""
return matches[0]
因此,在获取 size 节点时,我们的代码就可以精简为:
size = regex_get(context, r"尺寸:(.*?像素)")
3. 完整的Python代码
到这里,我们解析页面可能遇到的问题就已经解决了大半,整个Python代码如下:
import requests
import re
from pyquery import PyQuery as pq
def regex_get(text, expr):
matches = re.compile(expr).findall(text)
if len(matches) == 0:
return ""
return matches[0]
conseq = {}
## 下载文档
response = requests.get("http://www.58pic.com/newpic/32504070.html")
document = pq(response.text)
## 获取文件标题
title_node = document.find(".detail-title")
title_node.find("div").remove()
title_node.find("p").remove()
conseq["title"] = title_node.text()
## 获取素材类型
conseq["pictype"] = document.find(".pic-type").text()
## 获取文件格式
conseq["filetype"] = regex_get(document.find(".mainRight-file").text(), r"文件格式:([a-z]+)")
## 获取元数据
context = document.find(".main-right p").text()
conseq['metainfo'] = {
"size": regex_get(context, r"尺寸:(.*?像素)"),
"volume": regex_get(context, r"体积:(.*? MB)"),
"mode": regex_get(context, r"模式:([A-Z]+)"),
"resolution": regex_get(context, r"分辨率:(\d+dpi)"),
}
## 获取作者
conseq['author'] = document.find('.user-name').text()
## 获取图片
conseq['images'] = []
for node_image in document.find("#show-area-height img"):
conseq['images'].append(pq(node_image).attr("src"))
## 获取tag
conseq['tags'] = []
for node_image in document.find(".mainRight-tagBox .fl"):
conseq['tags'].append(pq(node_image).text())
print(conseq)
使用Golang进行页面的解析
在 Golang 中解析 html 和 xml 文档, 常用到的库有以下几种:
- 提供
正则表达式支持的regexp库 - 提供
CSS选择器支持的github.com/PuerkitoBio/goquery - 提供
Xpath支持的gopkg.in/xmlpath.v2库 - 提供
JSON PATH支持的github.com/tidwall/gjson库
这些库,你都可以通过 go get -u 来获取,由于在上面的Python解析中我们已经整理出了解析逻辑,在Golang中只需要复现即可,与 Python 不同的是,我们最好先为我们的数据结构定义一个 struct,像下面这样:
type Reuslt struct {
Title string
Pictype string
Number string
Type string
Metadata struct {
Size string
Volume string
Mode string
Resolution string
}
Author string
Images []string
Tags []string
}
同时,由于我们的 待解析页面 是非主流的 gbk 编码,所以在下载下来文档之后,需要手动将 utf-8 的编码转换为 gbk 的编码,这个过程虽然不在解析的范畴之内,但是也是必须要做的步骤之一, 我们使用了 github.com/axgle/mahonia 这个库进行编码的转换,并整理出了编码转换的函数 decoderConvert:
func decoderConvert(name string, body string) string {
return mahonia.NewDecoder(name).ConvertString(body)
}
因此, 最终的 golang 代码应该是下面这样的:
package main
import (
"encoding/json"
"log"
"regexp"
"strings"
"github.com/axgle/mahonia"
"github.com/parnurzeal/gorequest"
"github.com/PuerkitoBio/goquery"
)
type Reuslt struct {
Title string
Pictype string
Number string
Type string
Metadata struct {
Size string
Volume string
Mode string
Resolution string
}
Author string
Images []string
Tags []string
}
func RegexGet(text string, expr string) string {
regex, _ := regexp.Compile(expr)
return regex.FindString(text)
}
func decoderConvert(name string, body string) string {
return mahonia.NewDecoder(name).ConvertString(body)
}
func main() {
//下载文档
request := gorequest.New()
_, body, _ := request.Get("http://www.58pic.com/newpic/32504070.html").End()
document, err := goquery.NewDocumentFromReader(strings.NewReader(decoderConvert("gbk", body)))
if err != nil {
panic(err)
}
conseq := &Reuslt{}
//获取文件标题
titleNode := document.Find(".detail-title")
titleNode.Find("div").Remove()
titleNode.Find("p").Remove()
conseq.Title = titleNode.Text()
// 获取素材类型
conseq.Pictype = document.Find(".pic-type").Text()
// 获取文件格式
conseq.Type = document.Find(".mainRight-file").Text()
// 获取元数据
context := document.Find(".main-right p").Text()
conseq.Metadata.Mode = RegexGet(context, `尺寸:(.*?)像素`)
conseq.Metadata.Resolution = RegexGet(context, `体积:(.*? MB)`)
conseq.Metadata.Size = RegexGet(context, `模式:([A-Z]+)`)
conseq.Metadata.Volume = RegexGet(context, `分辨率:(\d+dpi)`)
// 获取作者
conseq.Author = document.Find(".user-name").Text()
// 获取图片
document.Find("#show-area-height img").Each(func(i int, element *goquery.Selection) {
if attribute, exists := element.Attr("src"); exists && attribute != "" {
conseq.Images = append(conseq.Images, attribute)
}
})
// 获取tag
document.Find(".mainRight-tagBox .fl").Each(func(i int, element *goquery.Selection) {
conseq.Tags = append(conseq.Tags, element.Text())
})
bytes, _ := json.Marshal(conseq)
log.Println(string(bytes))
}
解析逻辑完全相同,代码量和复杂程度相较 python版 差不多,下面我们来看一下新出现的 GraphQuery 是如何做的。
使用GraphQuery进行解析
已知我们想要得到的数据结构如下:
{
title
pictype
number
type
metadata {
size
volume
mode
resolution
}
author
images []
tags []
}
GraphQuery 的代码是下面这样的:
{
title `xpath("/html/body/div[4]/div[1]/div/div/div[1]/text()")`
pictype `css(".pic-type")`
number `css(".detailBtn-down");attr("data-id")`
type `regex("文件格式:([a-z]+)")`
metadata `css(".main-right p")` {
size `regex("尺寸:(.*?)像素")`
volume `regex("体积:(.*? MB)")`
mode `regex("模式:([A-Z]+)")`
resolution `regex("分辨率:(\d+dpi)")`
}
author `css(".user-name")`
images `css("#show-area-height img")` [
src `attr("src")`
]
tags `css(".mainRight-tagBox .fl")` [
tag `text()`
]
}
通过对比可以看出, 它只是在我们设计的数据结构之中添加了一些由反引号包裹起来的函数。惊艳的是,它能完全还原我们上面在 Python 和 Golang 中的解析逻辑,而且从它的语法结构上,更能清晰的读出返回的数据结构。这段 GraphQuery 的执行结果如下:
{
"data": {
"author": "Ice bear",
"images": [
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a0",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a1024",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a2048",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a3072"
],
"metadata": {
"mode": "RGB",
"resolution": "200dpi",
"size": "4724×6299",
"volume": "196.886 MB"
},
"number": "32504070",
"pictype": "原创",
"tags": ["大侠", "海报", "黑白", "金庸", "水墨", "武侠", "中国风"],
"title": "大侠海报金庸武侠水墨中国风黑白",
"type": "psd"
},
"error": "",
"timecost": 10997800
}
GraphQuery 是一个文本查询语言,它不依赖于任何后端语言,可以被任何后端语言调用,一段 GraphQuery 查询语句,在任何语言中可以得到相同的解析结果。
它内置了 xpath选择器,css选择器,jsonpath 选择器和 正则表达式 ,以及足量的文本处理函数,结构清晰易读,能够保证 数据结构、解析代码、返回结果 结构的一致性。
GraphQuery 的语法简洁易懂, 即使你是第一次接触它, 也能很快的上手, 它的语法设计理念之一就是 符合直觉, 我们应该如何执行它呢:
1. 在Golang中调用GraphQuery
在 golang 中,你只需要首先使用 go get -u github.com/storyicon/graphquery 获得 GraphQuery 并在代码中调用即可:
package main
import (
"log"
"github.com/axgle/mahonia"
"github.com/parnurzeal/gorequest"
"github.com/storyicon/graphquery"
)
func decoderConvert(name string, body string) string {
return mahonia.NewDecoder(name).ConvertString(body)
}
func main() {
request := gorequest.New()
_, body, _ := request.Get("http://www.58pic.com/newpic/32504070.html").End()
body = decoderConvert("gbk", body)
response := graphquery.ParseFromString(body, "{ title `xpath(\"/html/body/div[4]/div[1]/div/div/div[1]/text()\")` pictype `css(\".pic-type\")` number `css(\".detailBtn-down\");attr(\"data-id\")` type `regex(\"文件格式:([a-z]+)\")` metadata `css(\".main-right p\")` { size `regex(\"尺寸:(.*?)像素\")` volume `regex(\"体积:(.*? MB)\")` mode `regex(\"模式:([A-Z]+)\")` resolution `regex(\"分辨率:(\\d+dpi)\")` } author `css(\".user-name\")` images `css(\"#show-area-height img\")` [ src `attr(\"src\")` ] tags `css(\".mainRight-tagBox .fl\")` [ tag `text()` ] }")
log.Println(response)
}
我们的 GraphQuery 表达式以 单行 的形式, 作为函数 graphquery.ParseFromString 的第二个参数传入,得到的结果与预期完全相同。
2. 在Python中调用GraphQuery
在 Python 等其他后端语言中,调用 GraphQuery 需要首先启动其服务,服务已经为 windows、mac 和 linux 编译好,到 GraphQuery-http 中下载即可。
在解压并启动服务后,我们就可以愉快的使用 GraphQuery 在任何后端语言中对任何文档以图形的方式进行解析了。Python调用的示例代码如下:
import requests
def GraphQuery(document, expr):
response = requests.post("http://127.0.0.1:8559", data={
"document": document,
"expression": expr,
})
return response.text
response = requests.get("http://www.58pic.com/newpic/32504070.html")
conseq = GraphQuery(response.text, r"""
{
title `xpath("/html/body/div[4]/div[1]/div/div/div[1]/text()")`
pictype `css(".pic-type")`
number `css(".detailBtn-down");attr("data-id")`
type `regex("文件格式:([a-z]+)")`
metadata `css(".main-right p")` {
size `regex("尺寸:(.*?)像素")`
volume `regex("体积:(.*? MB)")`
mode `regex("模式:([A-Z]+)")`
resolution `regex("分辨率:(\d+dpi)")`
}
author `css(".user-name")`
images `css("#show-area-height img")` [
src `attr("src")`
]
tags `css(".mainRight-tagBox .fl")` [
tag `text()`
]
}
""")
print(conseq)
输出结果为:
{
"data": {
"author": "Ice bear",
"images": [
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a0",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a1024",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a2048",
"http://pic.qiantucdn.com/58pic/32/50/40/70d58PICZfkRTfbnM2UVe_PIC2018.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvZGF0dS5wbmc=/repeat/true/crop/0x1024a0a3072"
],
"metadata": {
"mode": "RGB",
"resolution": "200dpi",
"size": "4724×6299",
"volume": "196.886 MB"
},
"number": "32504070",
"pictype": "原创",
"tags": ["大侠", "海报", "黑白", "金庸", "水墨", "武侠", "中国风"],
"title": "大侠海报金庸武侠水墨中国风黑白",
"type": "psd"
},
"error": "",
"timecost": 10997800
}
三、后记
复杂的解析逻辑带来的不仅仅是代码可读性的问题,在代码的维护和移植上也会造成很大的困扰,不同的语言和不同的库也为代码的解析结果造成了差异,GraphQuery 是一个全新的开源项目,它的主旨就是让开发者从这些重复繁琐的解析逻辑中解脱出来,写出高可读性、高可移植性、高可维护性的代码。欢迎实践、持续关注与代码贡献,一起见证 GraphQuery 与开源社区的发展!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号