
浅析前端依赖知识体系:依赖是什么(可执行代码与声明)、npm i 的依赖机制、node应用如何使用依赖(声明)、web应用的模块化导致依赖复杂、webpack如何把依赖打包(代码与声明)、组件开发如何更好的被依赖
一、依赖是什么
先说结论:有时候,依赖是一堆 可执行的代码 ;有时候,依赖只是 一句声明。怎么理解以上这句话呢?
1、它可以是一堆代码
前端也好、后端也罢,开发的最终目的永远是实现功能,让代码成功地操作机器执行相关的任务。
想象一下,你要使用 vue.js 开发,但你不用自己实现一遍vue.js的核心逻辑,只需要依赖它、引入它。
import vue from 'vue'
// 或者
<script src="https://unpkg.com/vue@next"></script>
然后,你就可以开始专心撰写业务逻辑。当用户访问你的网站时,他们的浏览器里实际上已经开始运行起了vue.js的代码。
通过依赖vue.js,我们成功地获得了 一堆代码 。依赖就是获取一堆可用的代码。这很好理解。
2、它可以是一个声明
另外一个场景:你正在开发一个基于 vue.js 的组件库,因此,你不可避免的会用到 vue.js 的 api,如:import { ref } from 'vue'
因此,你可以认为你开发的组件是 “依赖 vue” 的,但思考一下,vue 应该被打包到你封装的组件内吗?当然不应该!
如果 vue.js 被打包到组件代码里,那势必导致各种问题,例如 “实例不一致” 、 “版本难统一” 、 “包体积臃肿” 等诸多问题。
因此,在这种场景下,组件所使用的 vue.js 实际上是宿主环境所依赖的 vue。(至于具体怎么依赖,后面会细说)
在这种情况下,依赖仅仅是一种声明 ,它并不会实际引入哪怕一行代码。
看到上面的两种依赖形式,你可能已经有点方了: 为啥有时候依赖是代码,有时候又是声明?我要怎么选择?不卖关子,我简单捋了几条简单的原则:
- 开发 web 应用时,大部分情况下,你的依赖是 “一堆代码”
- 如果你的 web 应用使用 CDN 单独引入了一些代码,那这部分你写代码时依赖的是 声明
- 开发组件时,你依赖的大部分依赖是 声明,但如果你希望这些代码成为组件不可分割的一部分,那你需要将它们变成 代码。
二、npm install 的依赖机制
前端引入依赖最常用的方式是 npm install。那么,npm install 时究竟是如何运作的呢?它有哪些 特别关键的细节?
1、依赖从哪里来的?我们应该从哪里获取依赖?
我认为简单归类的话,应该主要分为几类:
(1)从 npm 源安装
这里的 “源” 是泛指,并不仅限于 npm registry,而是泛指那些能通过 npm install 行为被下载的代码。应该包含以下几类:
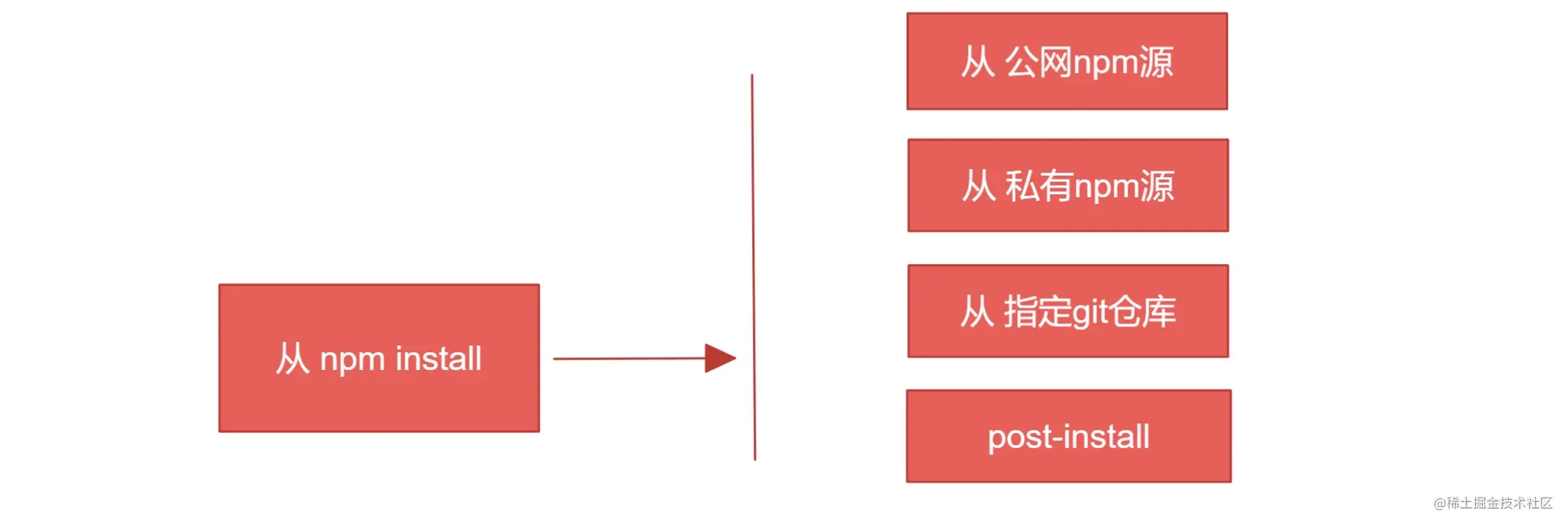
1.1、公网 npm registry
执行 npm install 时,npm 的默认行为是通过版本号,向 https://registry.npmjs.org/ 问询版本、下载版本。但因为众所知周的原因,我们有时候需要切换到 taobao 源等国内源进行加速,通过 nrm、npm config、.npmrc、--registry=xxx 等各种手段,都可以轻松完成切源操作。
1.2、私有 npm registry
并不是所有的代码都适合发布到公网上,因此很多企业选择了自行搭建 npm 源,其本质和 “公网 npm 源” 并无差别。但这其中存在一些技巧,比如通过 .npmrc 里的相关配置,可以选择性让 某些命名空间的库 从指定源下载。
registry = https://registry.npm.taobao.org/
@chunge:registry = https://registry.npm.chunge.cn/
这样一来,就能 公网的归公网、私有的归私有 了。
1.3、指定 git 仓库
除了从 npm registry 下载代码,npm 还支持多种协议,比如:

{
"name": "foo",
"version": "0.0.0",
"dependencies": {
"express": "git+ssh://git@github.com:npm/cli.git#v1.0.27"
}
}
通过指定 协议、仓库地址 以及 tag/commit-hash 等信息,可以精准指定到某个版本的代码。
1.4、post-install 玩法
从命名上能够看出,post-install 的意思是指 install 之后之后会主动触发的一个钩子。通过在这个钩子内执行脚本,你可以去下载任何你想要的内容,包括但不限于:.exe、.avi、.pdf 等等
(2)仓库级引用
通过 git submodule 、git subtree 和其他一些类似的方式,你可以在仓库内创建其他仓库的软连接,从而达到 仓库套仓库 的效果
(3)从 CDN 加载
所谓 cdn 引入,其实就是通过 html 标签,直接向某个资源请求数据。通常情况下这个资源是跨域的、且会动态均衡加速的。
通过 cdn 在 index.html 的标签内引入资源,有诸多好处:多域复用、就近传输、通过跨域达到 突破浏览器并发限制 的效果。在国内 to C 项目中,这是常见的玩法。但贸然引入公共免费 CDN 可能需要谨慎评估政策风险,比如 jsdeliver 的域名就经常被污染,一旦 CDN 陷落,你的网站可能就挂了。
(4)类 CDN 方式
xxx.min.js 文件 copy 到静态目录中,跟着制品一起打包,然后通过 cdn 类似的方式,在 html 中引入文件。这样当然就无法达到 多域复用、就近传输、突破并发 等效果了。但胜在稳定,而且对于 to B、to G 那种需要网络隔离的项目,更具优势。2、版本号标准:semver 语义化版本规范
版本是依赖的核心之一,没有明确的版本号规范,依赖将变得毫无意义。简单来说
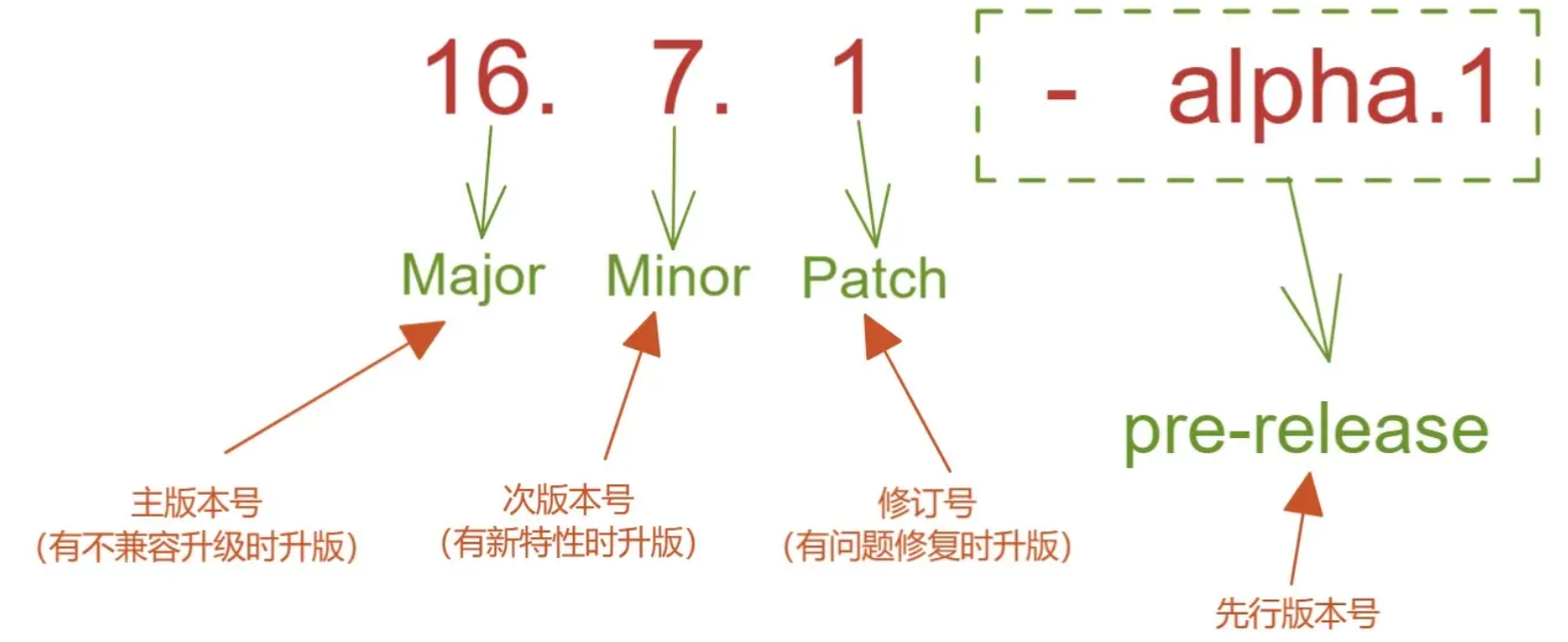
semver 版本号标准通常由三个数字组成,如 16.7.1,但可以通过增加类似 -alpha.1 这样的后缀来形成 先行版 。学习 版本号标准 的意义在于:
(1)它能帮助你理解,npm install 时需要安装哪个版本的包,以及为什么是这样
(2)当你试图写一个 web应用 或 npm包 时,能准确分析出自己应该如何合理地声明依赖
3、哪些依赖要装、哪些不装?
你能一口气说清楚项目里 node_modules 里的那些依赖都是怎么来的吗?为什么下载了它们,以及为什么只下载了它们?
其实,这只和你项目的 package.json 里两个重要的属性相关:dependencies 以及 devDependencies。
关于这两个属性,大部分人只能说出 “dependencies是生产要用的依赖,devDependencies是开发期用的” 。从语义上来说,这是对的,但从代码执行上来讲,这并不完全正确。假设一个最简单的场景:
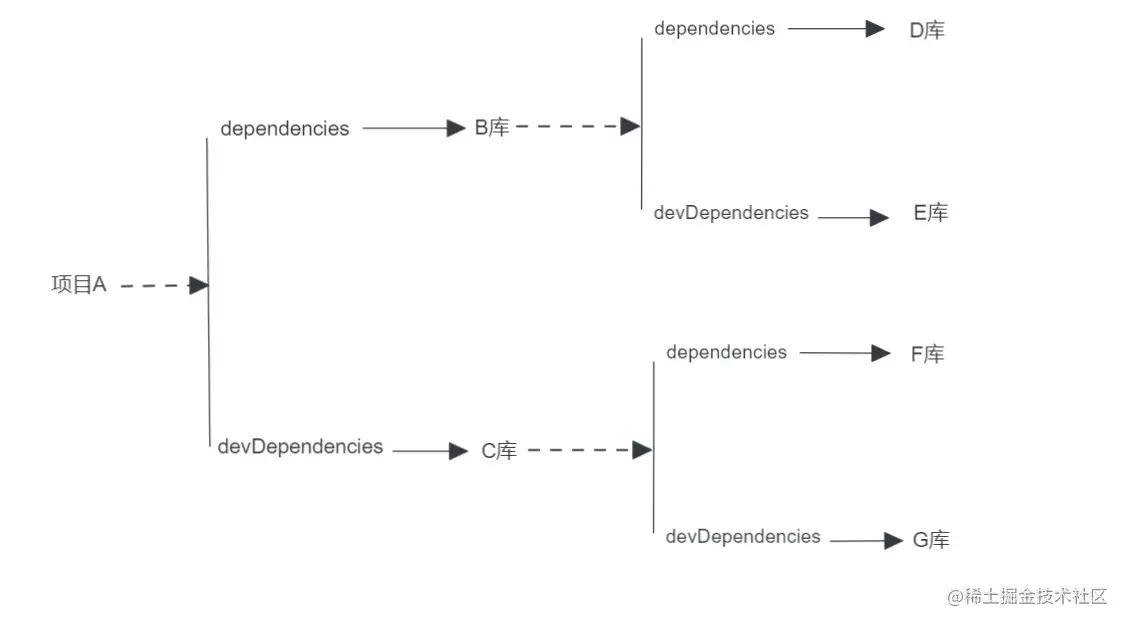
你正在开发 项目A,你 dependencies 了 B库,并 devDependencies 了 C库。同时 B 和 C 也都有自己的 dependencies 及 devDependencies。
请问:当你执行 npm install 时,图中的哪些库会被安装? 答案是:B、C、D、F
简单来说,在整个依赖树中,只有第一层的 devDependencies 是会被安装的。而从第二层开始的所有 devDependencies 都是不会被安装的。也就是说 G库、E库 以及它们所有依赖的库类都会在依赖分析时被剔除掉。
之所以说 “dependencies是生产要用的依赖,devDependencies是开发期用的” 这句话不全对的原因,就在于你其实是可以依赖 devDependencies 的,可惜的是,这并不安全。
4、依赖装在哪呢?
npm install 时,那些原本存储在 npm registry 源中的资源,被下载下来之后,都安装在什么位置呢?node_modules ? 当然!但并不准确。
我们先定义一种语法 A{B,C} 代表 A 包依赖了 B 包和 C 包。接下来,我们会详细分析 npm install 时安装文件的全逻辑。
假设:存在依赖关系
A{B,C}, B{C}, C{D},当在A包下执行npm install时:
安装后
A
`-- node_modules
+-- B
+-- C
+-- D
之所以这样,是因为 C 和 B 都会被默认安装 @latest 版本,因而版本一致,只用在 node_modules 根目录下铺平安装即可。但总会出现版本不一致的情况,比如:
假设:存在一连关系:
A{B,C}, B{C,D@1}, C{D@2}
安装后,目录则为:
A
`-- node_modules
+-- B
+-- C
`-- node_modules
+-- D@2
+-- D@1
依赖分析时,首先将 B 依赖的 D@1 安装到了 node_modules 根目录下,然后发现 C 依赖了 D@2,此时,就无法在 node_modules 根目录下安装两个 D 了,因此,D@2 被安装在了 node_modules/C/node_modules 文件夹下。
在这个安装机制下, 模糊版本匹配的正确使用 对安装效率、依赖体积的帮助是巨大的。
三、NodeJS应用是如何使用依赖的
依赖下载下来了,下一步是使用它们。最简单的场景,是你写一个 Node.js 的应用,比如脚本,这种情况下你不用操心 打包 和 浏览器,你只需要写下如下代码:const lodash = require('lodash'); 当你运行脚本时,lodash 就成功作为你的 依赖 被引入了。
当然,如果你想使用 Esm,.mjs格式的文件也是个不错的选择。
在大多数的 NodeJS 应用中,依赖是一种声明,按照本文 第二节 的描述,被声明在 dependencies 里的依然就会被安装,因此无需担心作为组件被使用时,无法获取依赖。
四、web应用的依赖为什么更复杂
为了模块化。以前刀耕火种的年代,前端先贤们都经历了什么:
- 使用对象作为宿主存储变量、避免全局污染;
IIFE自执行函数AMD和requirejsUmd!Esm!
如果你已经了解了上述内容,那一定知道,在 ESM 规范之前,浏览器上根本就没有 “模块化” 的概念,JS 脚本被加载到页面上,按时序执行,全局变量互相污染。虽然前端人依靠劳动者的智慧发明了 IIFE、AMD、UMD 等模块化解决方案,但确实是无奈之举。
而在兼容模块化这条路上,Web 应用 和 前端组件 却有着两套并不相同的处理方案。因此,当我们在代码里写下 import 和 require 时,我们需要认识到:
在浏览器中,它们不是被
import的,有人替我们抗下了所有,比如webpack。
五、web应用:webpack如何把依赖打包?
webpack 是一个打包器。它是如何让浏览器支持 模块化 的呢?
当你在 webpack 项目里写下 import * from '某个依赖' 时,webpack 所需要面对的依然是两个场景:
- 一堆代码
- 一个声明
1、webpack 如何处理一堆代码
第一节介绍过,一堆代码 的意思就是:import 的内容会被打包到制品中。这也是最为常见的一种方式。它会把所有的依赖视作 模块( module ),然后把多个 module 组合成一个 块 chunk。
当页面加载时,会将 chunk 解开,利用 moduleId 作为 key,将所有的 module 存储到 modules 中,大概如下:
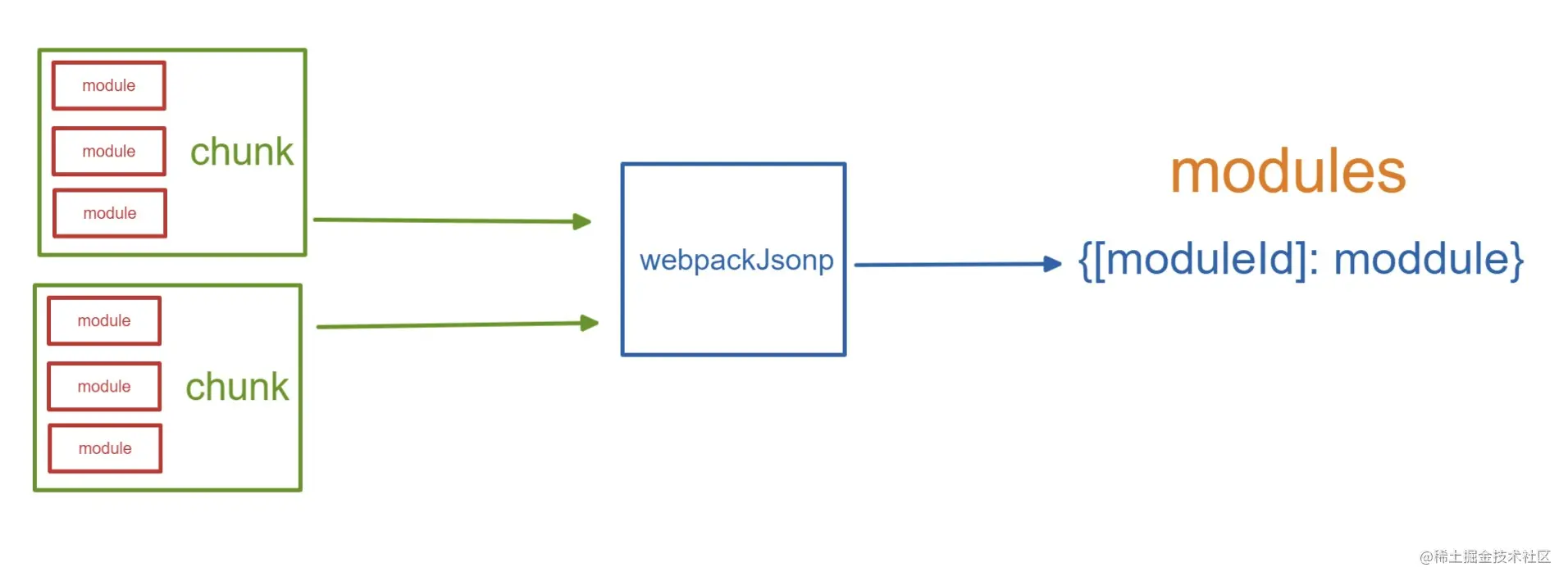
当然,这中间还包含一些 共同模块、已安装过的模块 等简化,不做赘述。
当实际当你的代码执行 import 时,它们实际已经不再是 import 了,而是被转换过的 __webpack_require__ 方法,通过这个方法就能达到 模块化的效果,从 modules 里取到所需要的依赖。正因为如此,webpack 的构建结果通常显得较为冗余,也是常常被人所诟病的点。不过与相比于它提供的价值,这几乎算是吹毛求疵。
2、webpack 如何处理一个声明
并不是所有情况下我们都需要把 依赖构建到制品 中。最典型的场景,便是利用CDN加速页面的加载效率。如UI库 Element Plus,它就推荐了CDN加载方式:
<head>
<!-- 导入样式 -->
<link rel="stylesheet" href="//unpkg.com/element-plus/dist/index.css" />
<!-- 导入 Vue 3 -->
<script src="//unpkg.com/vue@next"></script>
<!-- 导入组件库 -->
<script src="//unpkg.com/element-plus"></script>
</head>
那么,导入的CDN应该如何和 webpack 构建配合使用呢?
答案是: externals。此属性的作用是:指定某些包不打包到制品中,而是在运行时从外部获取。而获取的方式,就是 UMD 那套,当CDN被加载后,会将其 name 挂载到 window 上,而 webpack 也正是通过这个在全局上获取依赖。
module.exports = {
//...
externals: {
jquery: 'jQuery',
},
};
你在代码中写的 import * from jquery,并不会让 node_modules/jquery 被打包到制品中,而是在浏览器加载后的运行时,从 window.jQuery 中获取依赖。
六、vite/rollup怎么把依赖打包?
vite 构建的核心工具是 rollup.js。同样的,rollup 也是个打包器。它也不得不面对 webpack 面对的那两个问题:(1)怎么打包 一堆代码(2)怎么打包 一个声明
1、vite/rollup怎么处理一堆代码?
相比于 webpack 所设计的复杂的 chunk、module 等加载体系,rollup 显然纯粹的多,它默认只提供了 6种文件输出结构。而 vite 在这一点上显然更加激进,它最低以 es2015 作为自己的兼容标准,也就是构建输出的乃是 ESM 模块。
参考 vite 官网的描述:https://cn.vitejs.dev/guide/build.html#browser-compatibility
因而,在兼容性上,vite 比 webpack 要弱,带来的好处也是显而易见的:
- 制品结构清晰、不冗余、体积小。
- 好理解(
ESM),不用去学webpackJsonp是啥了。
当然,官方也给出了更低版本浏览器兼容的法门,按需要使用吧。
2、vite/rollup怎么处理一个声明?
vite 没有直接提供类似加载 CDN 依赖的配置。但社区提供了类似的插件,比如: vite-plugin-cdn-import。
而 rollup,如果你的目标构建格式是 umd,那么它的 globals 配置,正是用来处理这个问题的。
七、从组件开发思考:如何更好地被依赖
上面两节我们从 webpack、vite 大致了解了 web 应用构建过程中对依赖的处理。那么,当我们开发组件时,要怎么做才能更好地扮演自己作为 被依赖者 的角色呢?
1、组件应该输出什么格式?
大多数情况下:ESM、UMD 就够了,如果你的组件需要在 node.js 环境运行,那可能还需要加上 CommonJS 格式。
按照本文之前的说法,两种格式分别应对两种场景:
ESM: 作为 一堆代码 被引用。UMD: 作为 一个声明 的实际支撑,被用作CDN引入页面。
因为 rollup.js/vite 默认支持输出 ESM、UMD,所以 rollup/vite 实在是开发组件的利器。
值得一提的是,rollup.js 默认行为会把所有的模块打包到一个 js 文件里,这行为显然不符合当下 按需加载 的思路。
因此,通过 preserveModules: true 配置选项,可以让 rollup 只编译,不打包,输出完美的散装 esm 文件格式。
2、在组件内如何 只声明、不打包 ?
这是组件开发者永远无法绕开的问题,因为你必须想清楚。你开发 Element Plus,不可能内置一套 vue3 吧?按照本文【第二节】的描述,作为一个组件,你应该正确地 声明自己的依赖
(1)输出 ESM:通过 rollup external 配置和 package.json dependencies
rollup 的 external,和 webpack 的 externals 的作用类似,但存在差异。
rollup external 的作用是:指定部分依赖不打包到制品中,但是在代码中保留 import xxx from 'bar' 这样的语句。为了配合这个语法,我们应该把实际依赖声明到 package.json 的 dependencies 中。
这样当其他应用依赖组件时,会按照【本文第二节】的内容进行安装,并从 node_modules 中去寻找依赖。
(2)输出 UMD:通过 rollup output.globals 配置。
rollup 的 output.globals,和 webpack 的 externals 是真的像!
// 这是webpack的externals
module.exports = {
//...
externals: {
jquery: 'jQuery',
},
};
// 这是rollup的globals
export default {
output: {
globals: {
jquery: 'jQuery'
}
}
};
不仅写法像,它们的作用也像:
(1)被声明 globals 的库,不会被打包到制品中
(2)被引用时会去浏览器的 window 上通过别名寻找
通过以上两个思路,可以成功解决组件内 只声明、不打包 的需求。
八、总结
通过上面的总结,我们对 前端依赖 有了一个 较为体系的认识 。不妨试试回答这几个问题:
1、什么是依赖?是一堆代码,还是一个声明?
2、semver 是什么?
3、npm install 时,是怎么处理不同版本号的?都安装在哪?
4、dependencies 和 devDependencies 在表现上有什么本质区别?
5、为什么 web 端的依赖更加复杂?
6、webpack 和 vite 在制品格式上有啥区别?都是怎么处理依赖的?
7、开发组件时应该如何正确处理依赖?
最后声明一个原则:复杂的问题简单化、简单的问题体系化。
学习文章:《拿来吧您!把“前端依赖”纳入知识体系》- https://juejin.cn/post/7124102653407297550


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-07-31 ORDER BY 高级用法之CASE WHEN继续研究
2020-07-31 浅析Vue中的2种错误处理方式、源码分析及2种错误捕获流程
2019-07-31 CSS Variables:css自定义属性的使用
2019-07-31 async、await总结
2018-07-31 浅析.env文件的工作原理以及它是如何实现的
2017-07-31 JavaScript事件代理和事件委托
2017-07-31 JavaScript事件冒泡机制和阻止事件冒泡及默认事件