浅析Node.js的宏任务与微任务、本轮与次轮循环、事件循环概念及其6个阶段解析以及代码分析nodejs与浏览器的Event Loop差异
JavaScript 是单线程运行,异步操作特别重要。
只要用到引擎之外的功能,就需要跟外部交互,从而形成异步操作。由于异步操作实在太多,JavaScript 不得不提供很多异步语法。这就好比,有些人老是受打击, 他的抗打击能力必须变得很强,否则他就完蛋了。
Node 的异步语法比浏览器更复杂,因为它可以跟内核对话,不得不搞了一个专门的库 libuv 做这件事。这个库负责各种回调函数的执行时间,毕竟异步任务最后还是要回到主线程,一个个排队执行。
为了协调异步任务,Node 居然提供了四个定时器,让任务可以在指定的时间运行。
- setTimeout()
- setInterval()
- setImmediate()
- process.nextTick()
前两个是语言的标准,后两个是 Node 独有的。它们的写法差不多,作用也差不多,不太容易区别。你能说出下面代码的运行结果吗?
// test.js
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
process.nextTick(() => console.log(3));
Promise.resolve().then(() => console.log(4));
(() => console.log(5))();
// 运行结果如下:node test.js 5 3 4 1 2
如果你能一口说对,可能就不需要再看下去了。本文详细解释,Node 怎么处理各种定时器,或者更广义地说,libuv 库怎么安排异步任务在主线程上执行。
一、同步任务和异步任务
首先,同步任务总是比异步任务更早执行。
前面的那段代码,只有最后一行是同步任务,因此最早执行。
(() => console.log(5))();
二、本轮循环和次轮循环
异步任务可以分成两种:
- 追加在本轮循环的异步任务
- 追加在次轮循环的异步任务
所谓"循环",指的是事件循环(event loop)。这是 JavaScript 引擎处理异步任务的方式,后文会详细解释。这里只要理解,本轮循环一定早于次轮循环执行即可。
Node 规定,process.nextTick和Promise的回调函数,追加在本轮循环,即同步任务一旦执行完成,就开始执行它们。而setTimeout、setInterval、setImmediate的回调函数,追加在次轮循环。
这就是说,文首那段代码的第三行和第四行,一定比第一行和第二行更早执行。
// 下面两行,次轮循环执行
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
// 下面两行,本轮循环执行
process.nextTick(() => console.log(3));
Promise.resolve().then(() => console.log(4));
三、process.nextTick()
process.nextTick这个名字有点误导,它是在本轮循环执行的,而且是所有异步任务里面最快执行的。
Node 执行完所有同步任务,接下来就会执行process.nextTick的任务队列。所以,下面这行代码是第二个输出结果。
process.nextTick(() => console.log(3));
基本上,如果你希望异步任务尽可能快地执行,那就使用process.nextTick。
四、微任务
根据语言规格,Promise对象的回调函数,会进入异步任务里面的"微任务"(microtask)队列。
微任务队列追加在process.nextTick队列的后面,也属于本轮循环。所以,下面的代码总是先输出3,再输出4。
process.nextTick(() => console.log(3));
Promise.resolve().then(() => console.log(4));
// 3 // 4
也就是说Node里面微任务有2个队列:nextTickQuene 和 microTaskQuene
而且需要注意的是,只有前一个队列全部清空以后,才会执行下一个队列。
process.nextTick(() => console.log(1));
Promise.resolve().then(() => console.log(2));
process.nextTick(() => console.log(3));
Promise.resolve().then(() => console.log(4));
// 1 // 3 // 2 // 4
上面代码中,全部process.nextTick的回调函数,执行都会早于Promise的。
至此,本轮循环的执行顺序就讲完了:(1)同步任务(2)process.nextTick()(3)微任务
五、事件循环的概念
下面开始介绍次轮循环的执行顺序,这就必须理解什么是事件循环(event loop)了。Node 的官方文档是这样介绍的。
"When Node.js starts, it initializes the event loop, processes the provided input script which may make async API calls, schedule timers, or call process.nextTick(), then begins processing the event loop."
这段话很重要,需要仔细读。它表达了三层意思。
首先,有些人以为,除了主线程,还存在一个单独的事件循环线程。不是这样的,只有一个主线程,事件循环是在主线程上完成的。
其次,Node 开始执行脚本时,会先进行事件循环的初始化,但是这时事件循环还没有开始,会先完成下面的事情。
- 同步任务
- 发出异步请求
- 规划定时器生效的时间
- 执行
process.nextTick()等等
最后,上面这些事情都干完了,事件循环就正式开始了。
六、事件循环的六个阶段
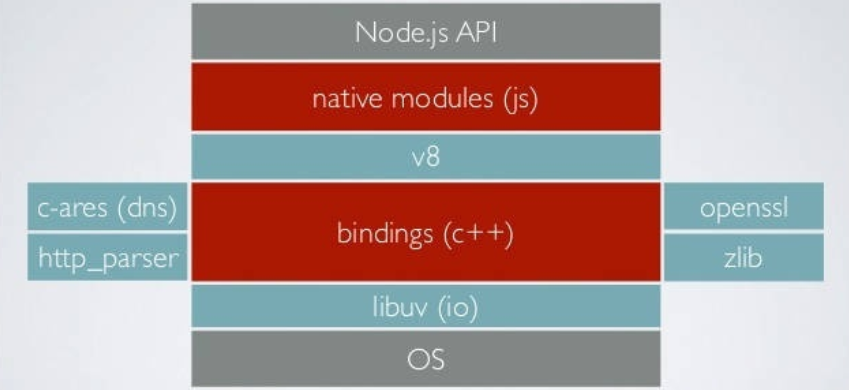
Node 中的 Event Loop 和浏览器中的是完全不相同的东西。Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现
Node.js的运行机制如下:
- V8引擎解析JavaScript脚本
- 解析后的代码,调用Node API
- libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户
其中libuv引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
事件循环会无限次地执行,一轮又一轮。只有异步任务的回调函数队列清空了,才会停止执行。
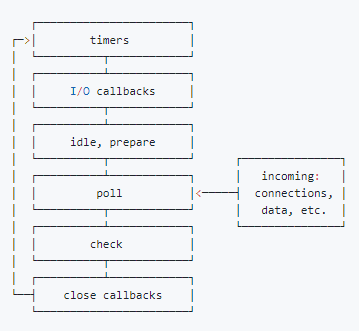
从上图中,大致看出node中的事件循环的顺序:
外部输入数据 --> 轮询阶段(poll) -->检 查阶段(check) --> 关闭事件回调阶段(close callback) --> 定时器检测阶段(timer) --> I/O事件回调阶段(I/O callbacks) --> 闲置阶段(idle, prepare) --> 轮询阶段(按照该顺序反复运行)...
下面简单介绍一下每个阶段的含义,详细介绍可以看官方文档,也可以参考 libuv 的源码解读。
1、timers
这个是定时器阶段,处理setTimeout()和setInterval()的回调函数。进入这个阶段后,主线程会检查一下当前时间,是否满足定时器的条件。如果满足就执行回调函数,否则就离开这个阶段。
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。 同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
2、I/O callbacks
处理一些上一轮循环中的少数未执行的 I/O 回调。除了以下操作的回调函数,其他的回调函数都在这个阶段执行。
setTimeout()和setInterval()的回调函数setImmediate()的回调函数- 用于关闭请求的回调函数,比如
socket.on('close', ...)
该阶段只供 libuv 内部调用,这里可以忽略。
4、Poll
这个阶段是轮询时间,用于等待还未返回的 I/O 事件,比如服务器的回应、用户移动鼠标等等。
获取新的I/O事件, 适当的条件下node将阻塞在这里。这个阶段的时间会比较长。如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 I/O 请求返回结果。
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情:(1)回到 timer 阶段执行回调(2)执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情:
(1)如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
(2)如果 poll 队列为空时,会有两件事发生:
1.如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
2.如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调
5、check
该阶段执行setImmediate()的回调函数。
6、close callbacks
该阶段执行关闭请求的回调函数,比如socket.on('close', ...)。
七、注意点
1、setTimeout 和 setImmediate
二者非常相似,区别主要在于调用时机不同。
- setImmediate 设计在poll阶段完成时执行,即check阶段;
- setTimeout 设计在poll阶段为空闲时,且设定时间到达后执行,但它在timer阶段执行
setTimeout(function timeout () {
console.log('timeout');
},0);
setImmediate(function immediate () {
console.log('immediate');
});
- 对于以上代码来说,setTimeout 可能执行在前,也可能执行在后。
- 首先 setTimeout(fn, 0) === setTimeout(fn, 1),这是由源码决定的 进入事件循环也是需要成本的,如果在准备时候花费了大于 1ms 的时间,那么在 timer 阶段就会直接执行 setTimeout 回调
- 如果准备时间花费小于 1ms,那么就是 setImmediate 回调先执行了
但当二者在异步i/o callback内部调用时,总是先执行setImmediate,再执行setTimeout
const fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0)
setImmediate(() => {
console.log('immediate')
})
})
// immediate
// timeout
在上述代码中,setImmediate 永远先执行。因为两个代码写在 IO 回调中,IO 回调是在 poll 阶段执行,当回调执行完毕后队列为空,发现存在 setImmediate 回调,所以就直接跳转到 check 阶段去执行回调了。
2、process.nextTick
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
})
})
})
})
// nextTick=>nextTick=>nextTick=>nextTick=>timer1=>promise1
八、Node与浏览器的 Event Loop 差异
浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务。
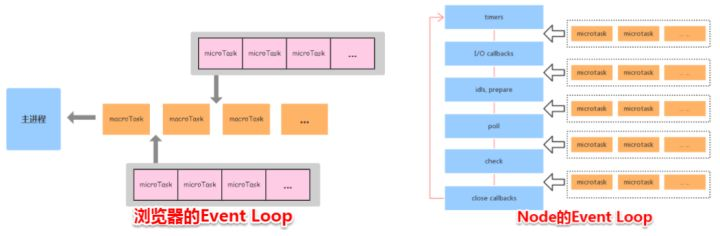
接下我们通过一个例子来说明两者区别:
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
浏览器端运行结果:timer1=>promise1=>timer2=>promise2,浏览器端的处理过程如下:
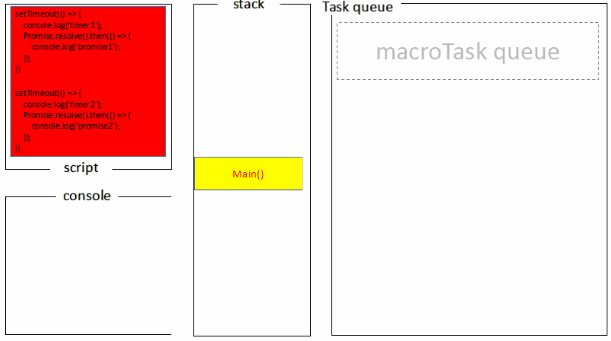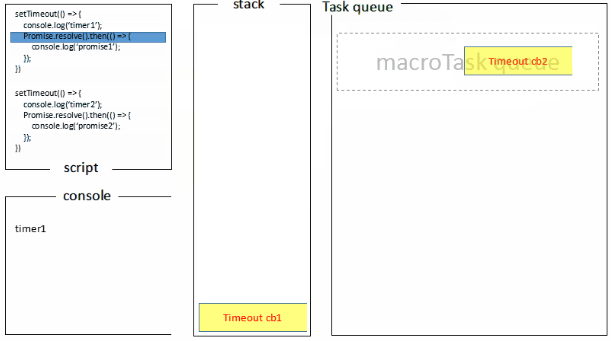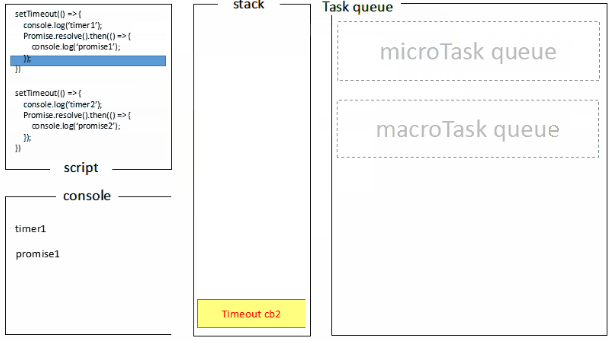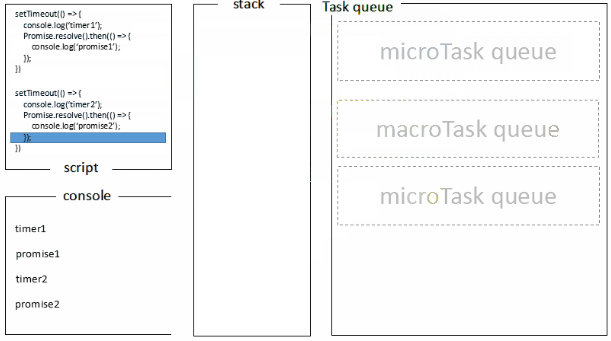
而Node端运行结果分两种情况:
(1)如果是node11以上版本,一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这就跟浏览器端运行一致,最后的结果为timer1=>promise1=>timer2=>promise2
(2)如果是node10及其之前版本:要看第一个定时器执行完,第二个定时器是否在完成队列中。
- 如果是第二个定时器还未在完成队列中,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是第二个定时器已经在完成队列中,则最后的结果为
timer1=>timer2=>promise1=>promise2(下文过程解释基于这种情况下)
1.全局脚本(main())执行,将2个timer依次放入timer队列,main()执行完毕,调用栈空闲,任务队列开始执行;
2.首先进入timers阶段,执行timer1的回调函数,打印timer1,并将promise1.then回调放入microtask队列,同样的步骤执行timer2,打印timer2;
3.至此,timer阶段执行结束,event loop进入下一个阶段之前,执行microtask队列的所有任务,依次打印promise1、promise2
Node端的处理过程如下:
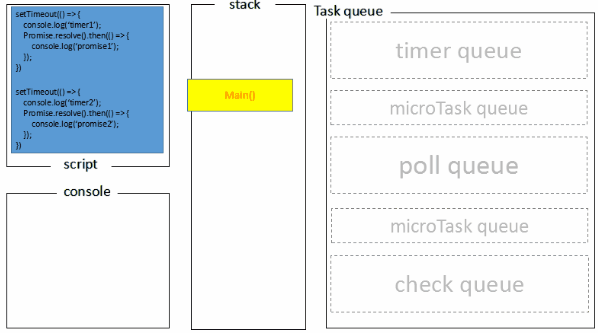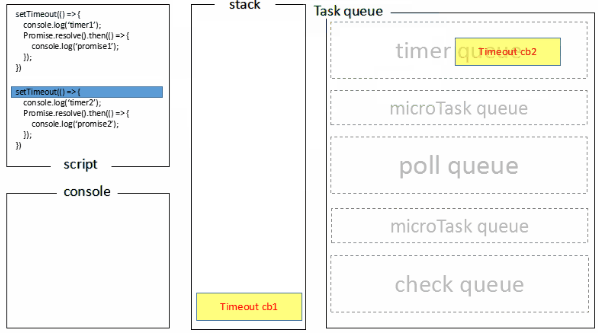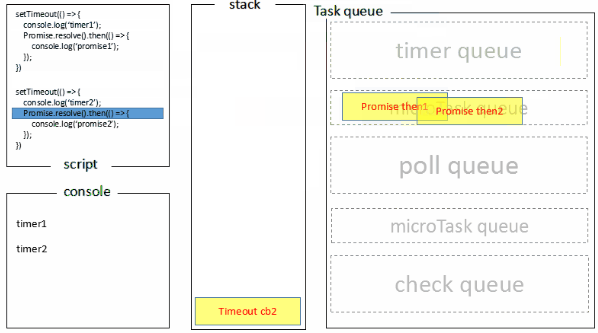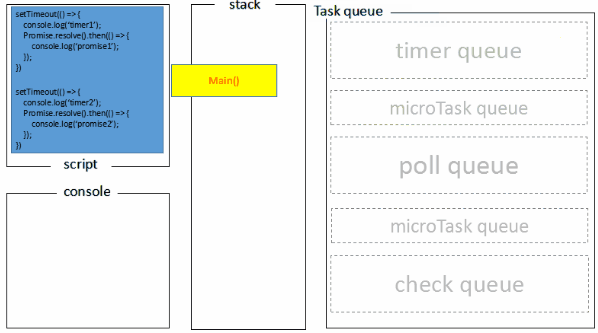
node10及之前版本的结果表现随机(取决于第二个定时器是否在完成队列中),但是node11就跟浏览器类似了(具体可以查看node的pr:https://github.com/nodejs/node/pull/22842)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号