pagehelper踩坑:不分页的情况及解决
一、问题背景
Java 后端使用了 PageHelper 分页插件来进行分页查询,但是发现有个方法分页不生效,总是返回的是全部数据。
后来查了相关文档找到了问题原因如下。
二、不分页的几种情况
1、版本过低的问题
问题:pagehelper没有效果,一直不能分页问题
解决方法:引用其他博主的博客的解决:http://blog.csdn.net/linxingliang/article/details/52566881
这个版本太老了,我的肯定不是这个原因
2、业务顺序问题
问题:PageHelper 有的时候有效果,有时候没有效果。我在项目中就遇到了这个问题,我用管理员角色的时候就可以正常分页,用其他角色的时候就不行。
三、问题具体原因
PageHelper 里面的 PageHelper.startPage(1,10); 只对该语句以后的第一个查询语句得到的数据进行分页,就算你在 PageInfo pa = new PageInfo("", 对象); 语句里面的对象是写的最终得到的数据,该插件还是只会对第一个查询语句所查询出来的数据进行分页。
第一个查询语句是指什么呢?
举个例子吧:比如你有一个查询数据的方法,写在了 PageHelper.startPage(1, 10); 下面。但是这个查询方法里面包含两个查询语句的话,该插件就只会对第一查询语句查询的数据进行分页,而不是对返回最终数据的查询与基础查询出来的数据进行分页。
所以解决方法就是:改变一下自己的代码结构,让最终需要的数据所需要的查询语句放在 PageHelper.startPage(1, 10) 下面就行。
四、项目踩坑参考
1、问题思路:
排查问题的时候看日志打印的 sql,发现猫腻:PageHelper 拼接的 limit ? 怎么是加在 这个角色判断的sql语句上,而不是下面的具体数据查询语句上。

再看代码里是这样写的:所以我们可以知道了,管理员的判断无需执行 sql 查询,故分页正常;其他角色判断会执行一个角色判断的sql,所以 limit ? 就加在了这条“第一条语句”上,后面的第二条数据查询语句就没有加上 limit。
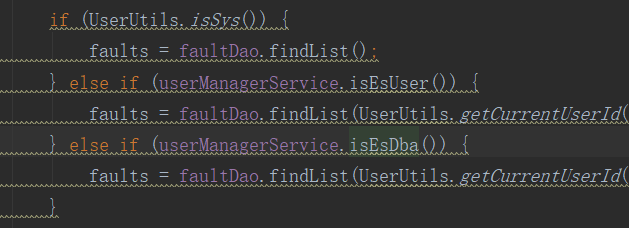
2、解决方案:
改变一下自己的代码结构,让最终查询数据的查询语句放在 PageHelper.startPage(1, 10) 下面就行。
我们就这样改咯,把 角色的判断前置即可
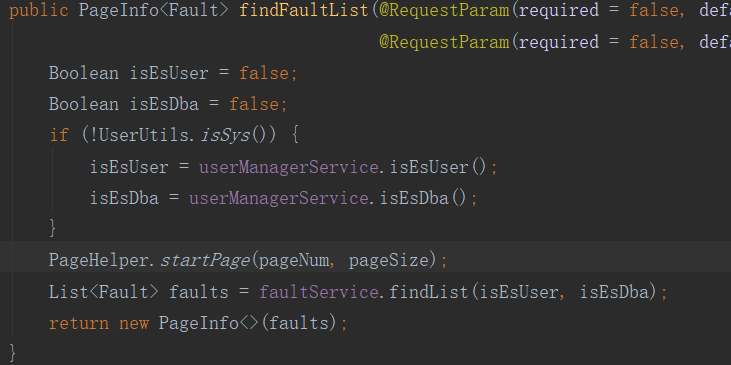
顺便优化一下之前的 service 实现类代码:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号