浅析PostgreSQL序列(SEQUENCE)、常用序列操作、数据迁移后更新序列流程
序列是什么?序列对象(也叫序列生成器)就是用CREATE SEQUENCE 创建的特殊的单行表。一个序列对象通常用于为行或者表生成唯一的标识符。
在持久层框架如Hibernate(JPA)、Mybatis中经常会用到Sequences(函数)去创建主键值,PostgreSQL中,用serial数据类型的主键,数据库会自动创建Sequences,那么我们自己设置的integer主键,如何设置添加Sequences呢?
一、常用序列操作:
1、创建序列(从1开始,递增幅度1,最大值无上限):
create sequence fl_user_seq increment by 1 minvalue 1 no maxvalue start with 1;
2、更改序列值(方法中两个参数分别是1.序列名字,2.序列修改后值):
select setval('fl_user_seq ', 88);
3、创建序列
CREATE SEQUENCE if not exists test_mergetable_id_seq
INCREMENT 1
MINVALUE 1
MAXVALUE 999999999
START 1
CACHE 1;
-- 或者:
create sequence if not exists test_mergetable_id_seq increment by 1 minvalue 1 no maxvalue start with 1;
4、指定序列(给表的主键指定创建好的序列)
alter table test_mergetable alter column "i_id" set default nextval('test_mergetable_id_seq');
5、设置序列自增长从当前最大值开始
SELECT setval('test_mergetable_id_seq', (SELECT MAX(i_id) FROM test_mergetable));
alter sequence test_mergetable_id_seq start with 12;
6、删除序列
drop sequence IF EXISTS test_mergetable_id_seq
7、查看序列
SELECT nextval('test_mergetable_id_seq')
二、创建Sequences
(一)创建序列方法一:直接在表中指定字段类型为serial 类型
create table tbl_xulie (id serial,name text);
-- NOTICE: CREATE TABLE will create implicit sequence "tbl_xulie_id_seq" for serial column "tbl_xulie.id"
-- CREATE TABLE
(二)方法二:先创建序列名称,然后在新建的表中列属性指定序列就可以了,该列需int 类型
创建序列的语法:
CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
[ OWNED BY { table.column | NONE } ]
实例:
create sequence tbl_xulie2_id_seq increment by 1 minvalue 1 no maxvalue start with 1;
-- CREATE SEQUENCE
create table tbl_xulie2 (id int4 not null default nextval('tbl_xulie2_id_seq'),name text);
-- CREATE TABLE
(三)方法三:图形pgadmin管理
1、Sequences 名称: mytable_myid_seq
2、主键名 myid
3、模式名 gys
图形pgadmin管理:在pgadmin中,我们可以在sequences上右键,create -> sequences



OK了,生成的SQL
CREATE SEQUENCE gys.mytable_myid_seq
INCREMENT 1
START 1
MINVALUE 1
MAXVALUE 99999999
CACHE 1;
ALTER SEQUENCE gys.mytable_myid_seq
OWNER TO postgres;
4、为主键设置Sequences:
alter table gys.mytable alter column myid set default nextval('gys.mytable_myid_seq');
三、序列应用
1、查看序列
\d tbl_xulie
Table "public.tbl_xulie"
Column | Type | Modifiers
--------+---------+--------------------------------------------------------
id | integer | not null default nextval('tbl_xulie_id_seq'::regclass)
name | text |
查看序列属性
select * from tbl_xulie2_id_seq;
sequence_name | last_value | start_value | increment_by | max_value | min_value | cache_value | log_cnt | is_cycled | is_called
-------------------+------------+-------------+--------------+---------------------+-----------+-------------+---------+-----------+-----------
tbl_xulie2_id_seq | 1 | 1 | 1 | 9223372036854775807 | 1 | 1 | 0 | f | f
(1 row)
2、序列应用
(1)在INSERT 命令中使用序列
insert into tbl_xulie values (nextval('tbl_xulie_id_seq'), 'David');
(2)数据迁移后更新序列
数据迁移后更新序列,一般是需要跨库的,所以流程是我们先需要到 原来的库里去拿到序列的下一个值,然后在新库里去设置为序列的当前值。
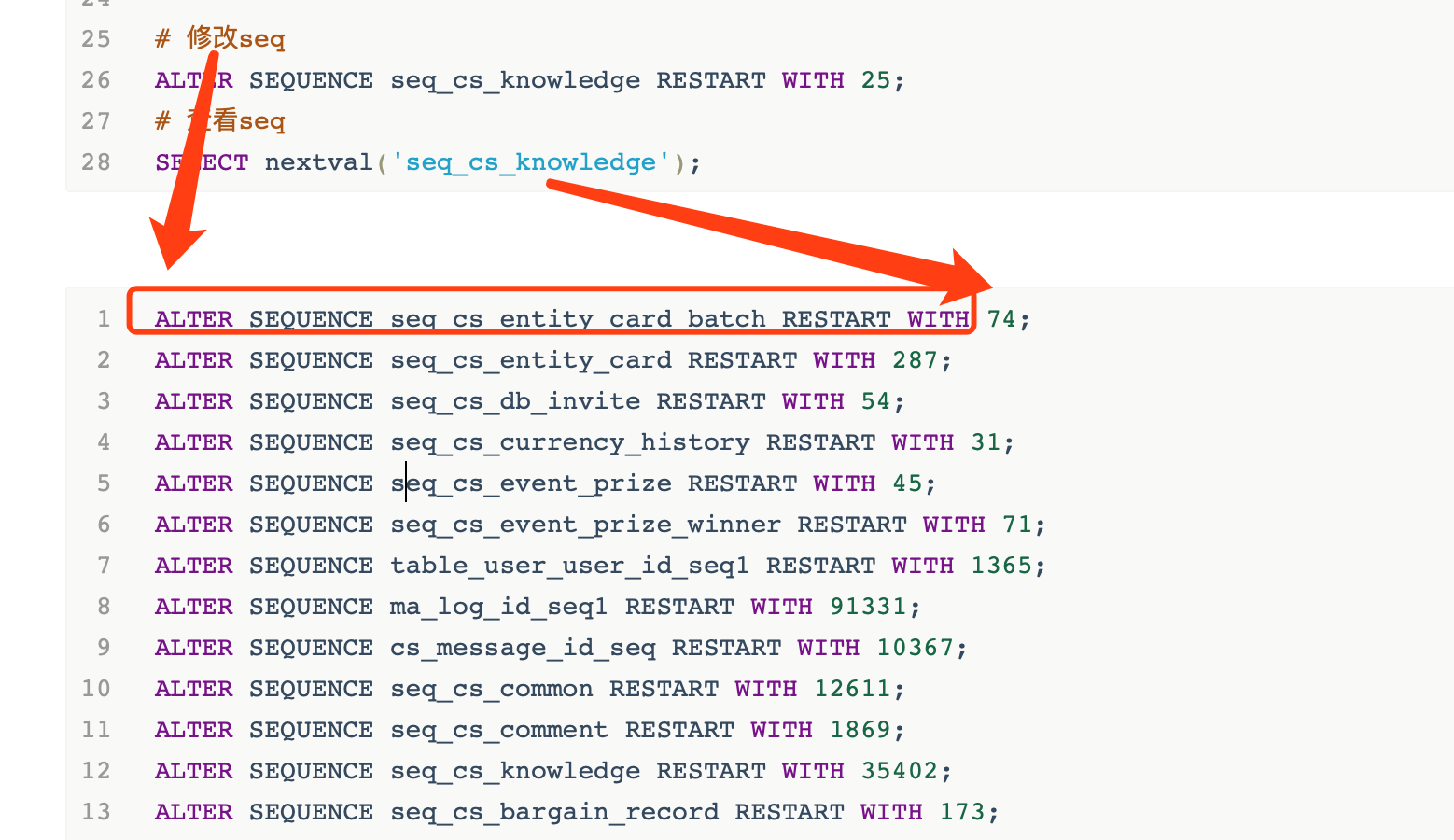
一条一条设置显然不现实,那就需要依赖去跑脚本啦。
四、序列函数
下面序列函数,为我们从序列对象中获取最新的序列值提供了简单和并发读取安全的方法。
| 函数 | 返回类型 | 描述 |
| nextval(regclass) | bigint | 递增序列对象到它的下一个数值并且返回该值。这个动作是自动完成的。即使多个会话并发运行nextval,每个进程也会安全地收到一个唯一的序列值。 |
| currval(regclass) | bigint | 在当前会话中返回最近一次nextval抓到的该序列的数值。(如果在本会话中从未在该序列上调用过 nextval,那么会报告一个错误。)请注意因为此函数返回一个会话范围的数值,而且也能给出一个可预计的结果,因此可以用于判断其它会话是否执行过nextval。 |
| lastval() | bigint | 返回当前会话里最近一次nextval返回的数值。这个函数等效于currval,只是它不用序列名为参数,它抓取当前会话里面最近一次nextval使用的序列。如果当前会话还没有调用过nextval,那么调用lastval将会报错。 |
| setval(regclass, bigint) | bigint | 重置序列对象的计数器数值。设置序列的last_value字段为指定数值并且将其is_called字段设置为true,表示下一次nextval将在返回数值之前递增该序列。 |
| setval(regclass, bigint, boolean) | bigint | 重置序列对象的计数器数值。功能等同于上面的setval函数,只是is_called可以设置为true或false。如果将其设置为false,那么下一次nextval将返回该数值,随后的nextval才开始递增该序列。 |
1、查看下一个序列值
nextval
---------
3
(1 row)
2、查看序列最近使用值
currval
---------
4
(1 row)
3、重置序列
方法一:使用序列函数:setval(regclass, bigint)
select setval('tbl_xulie_id_seq', 1);
setval
--------
1
(1 row)
使用序列函数:setval(regclass, bigint, boolean)
select setval('tbl_xulie_id_seq', 1, true);
setval
--------
1
(1 row)
方法二:修改序列
修改序列的语法:
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ]
[ RESTART [ [ WITH ] restart ] ]
[ CACHE cache ] [ [ NO ] CYCLE ]
[ OWNED BY { table.column | NONE } ]
ALTER SEQUENCE name OWNER TO new_owner
ALTER SEQUENCE name RENAME TO new_name
ALTER SEQUENCE name SET SCHEMA new_schema
修改序列实例
alter sequence tbl_xulie_id_seq restart with 0;
-- ERROR: RESTART value (0) cannot be less than MINVALUE (1)
alter sequence tbl_xulie_id_seq restart with 1;
-- ALTER SEQUENCE
4、删除序列
语法:
DROP SEQUENCE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
当有表字段使用到PG序列时,不能直接删除。
david=# drop sequence tbl_xulie2_id_seq;
ERROR: cannot drop sequence tbl_xulie2_id_seq because other objects depend on it
DETAIL: default for table tbl_xulie2 column id depends on sequence tbl_xulie2_id_seq
HINT: Use DROP ... CASCADE to drop the dependent objects too.
david=# drop table tbl_xulie2;
DROP TABLE
david=# drop sequence tbl_xulie2_id_seq;
DROP SEQUENCE
david=#
对于序列是由建表时指定serial 创建的,删除该表的同时,对应的序列也会被删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号