浅析Tree-Shaking实现原理、了解DCE与tree-shaking各自着重点、摇树实现的基本条件以及代码编程中的最佳实践
一、什么是Tree-shaking
Tree-Shaking 是一种基于 ES Module 规范的 Dead Code Elimination 技术,它会在运行过程中静态分析模块之间的导入导出,确定 ESM 模块中哪些导出值未被其它模块使用,并将其删除,以此实现打包产物的优化。
前端中的 tree-shaking 可以理解为通过工具"摇"我们的JS文件,将其中用不到的代码"摇"掉,是一个性能优化的范畴。
具体来说,在 webpack 项目中,有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树枝。实际情况中,虽然依赖了某个模块,但其实只使用其中的某些功能。通过 tree-shaking,将没有使用的模块摇掉,这样来达到删除无用代码的目的。
二、了解编译器的 DCE 与 tree-shaking
Tree-shaking 的本质是消除无用的 JS 代码。无用代码消除在广泛存在于传统的编程语言编译器中,编译器可以判断出某些代码根本不影响输出,然后消除这些代码,这个称之为 DCE(dead code elimination)
Tree-shaking 是 DCE 的一种新的实现,JS 同传统的编程语言不同的是,JS 绝大多数情况需要通过网络进行加载,然后执行,加载的文件大小越小,整体执行时间更短,所以去除无用代码以减少文件体积,对JS来说更有意义。
Tree-shaking 和传统的 DCE 的方法又不太一样,传统的 DCE 消灭不可能执行的代码,而 Tree-shaking 更关注于消除没有用到的代码。下面详细介绍一下DCE 和 Tree-shaking。
1、先来看一下DCE消除大法
Dead Code 一般具有以下几个特征
(1)代码不会被执行,不可到达
(2)代码执行的结果不会被用到
(3)代码只会影响死变量(只写不读)
传统编译型的语言中,都是由编译器将Dead Code从AST(抽象语法树)中删除,那 JS 中是由谁做DCE呢?
首先,肯定不是浏览器做DCE,因为当我们的代码送到浏览器,那还谈什么消除无法执行的代码来优化呢,所以肯定是送到浏览器之前的步骤进行优化。其实也不是 rollup,webpack 做的,而是著名的代码压缩优化工具 uglify。uglify 完成了 JS 的 DCE,下面通过一个实验来验证一下。
如何实验见这篇文章:https://blog.csdn.net/qq_34629352/article/details/104256311,这里主要说下实验结论:
(1)rollup将无用的代码foo函数和unused函数消除了,但是仍然保留了不会执行到的代码,而webpack完整的保留了所有的无用代码和不会执行到的代码。
(2)分别用 rollup + uglify 和 webpack + uglify 进行打包,打包结果中都去除了无法执行到的代码
2、 再来看一下Tree-shaking消除大法
前面提到了tree-shaking更关注于无用模块的消除,消除那些引用了但并没有被使用的模块。
先思考一个问题,为什么tree-shaking是最近几年流行起来了?而前端模块化概念已经有很多年历史了,其实 tree-shaking 的消除原理是依赖于ES6的模块特性。
ES6 module 特点:
(1)只能作为模块顶层的语句出现
(2)import 的模块名只能是字符串常量
(3)import binding 是 immutable 的
ES6模块依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,这就是tree-shaking的基础。
所谓静态分析就是不执行代码,从字面量上对代码进行分析,ES6之前的模块化,比如我们可以动态require一个模块,只有执行后才知道引用的什么模块,这个就不能通过静态分析去做优化。
这是 ES6 modules 在设计时的一个重要考量,也是为什么没有直接采用 CommonJS,正是基于这个基础上,才使得 tree-shaking 成为可能,这也是为什么 rollup 和 webpack 2 都要用 ES6 module syntax 才能 tree-shaking。
三、webpack 实现 tree-shaking 的基础条件
1、理论基础
在 CommonJs、AMD、CMD 等旧版本的 JavaScript 模块化方案中,导入导出行为是高度动态,难以预测的,例如:
if(process.env.NODE_ENV === 'development'){
require('./bar');
exports.foo = 'foo';
}
而 ESM 方案则从规范层面规避这一行为,它要求所有的导入导出语句只能出现在模块顶层,且导入导出的模块名必须为字符串常量,这意味着下述代码在 ESM 方案下是非法的:
if(process.env.NODE_ENV === 'development'){
import bar from 'bar';
export const foo = 'foo';
}
所以,ESM 下模块之间的依赖关系是高度确定的,与运行状态无关,编译工具只需要对 ESM 模块做静态分析,就可以从代码字面量中推断出哪些模块值未曾被其它模块使用,这是实现 Tree Shaking 技术的必要条件。
2、示例
// index.js
import {bar} from './bar';
console.log(bar);
// bar.js
export const bar = 'bar';
export const foo = 'foo';
示例中,bar.js 模块导出了 bar 、foo ,但只有 bar 导出值被其它模块使用,经过 Tree Shaking 处理后,foo 变量会被视作无用代码删除。
四、webpack 摇树的实现原理
Webpack 中,Tree-shaking 的实现一是先「标记」出模块导出值中哪些没有被用过,二是使用 Terser 删掉这些没被用到的导出语句。标记过程大致可划分为三个步骤:
-
Make 阶段,收集模块导出变量并记录到模块依赖关系图 ModuleGraph 变量中
-
Seal 阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用
-
生成产物时,若变量没有被其它模块使用则删除对应的导出语句
标记功能需要配置 optimization.usedExports = true 开启
也就是说,标记的效果就是删除没有被其它模块使用的导出语句,比如:
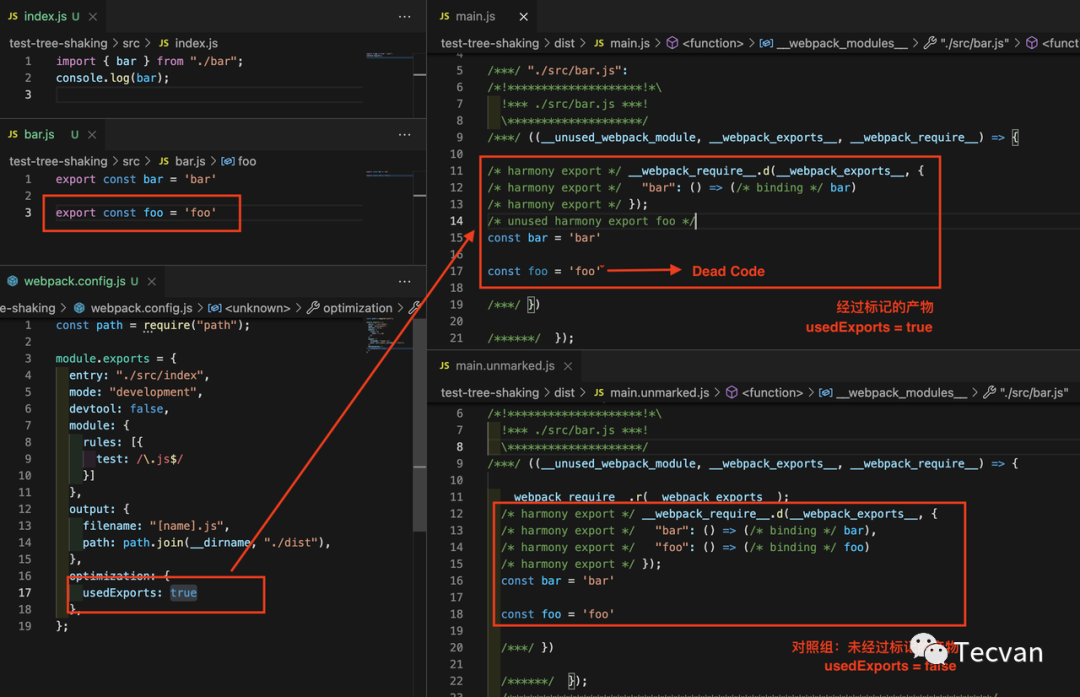
示例中,bar.js 模块(左二)导出了两个变量:bar 与 foo,其中 foo 没有被其它模块用到,所以经过标记后,构建产物(右一)中 foo 变量对应的导出语句就被删除了。
作为对比,如果没有启动标记功能(optimization.usedExports = false 时),则变量无论有没有被用到都会保留导出语句,如上图右二的产物代码所示。
注意,这个时候 foo 变量对应的代码 const foo='foo' 都还保留完整,这是因为标记功能只会影响到模块的导出语句,真正执行“「Shaking」”操作的是 Terser 插件。例如在上例中 foo 变量经过标记后,已经变成一段 Dead Code —— 不可能被执行到的代码,
这个时候只需要用 Terser、UglifyJS 等 DCE 工具“摇”掉这部分无效代码就可以删除这一段定义语句,以此实现完整的 Tree Shaking 效果。
详细见这篇文章:https://blog.csdn.net/frontend_frank/article/details/120073004
总结下具体步骤
1、收集模块导出:首先 Webpack 需要弄清楚每个模块分别有什么导出值,这一过程发生在 make 阶段
2、标记模块导出:模块导出信息收集完毕后,Webpack 需要标记出各个模块的导出列表中,哪些导出值有被其它模块用到,哪些没有,这一过程发生在 Seal 阶段
3、生成代码:经过前面的收集与标记步骤后,Webpack 已经在 ModuleGraph 体系中清楚地记录了每个模块都导出了哪些值,每个导出值又没那块模块所使用。接下来,Webpack 会根据导出值的使用情况生成不同的代码
4、删除 Dead Code:经过前面几步操作后,模块导出列表中未被使用的值都不会定义在 __webpack_exports__ 对象中,形成一段不可能被执行的 Dead Code 效果,最后将由 Terser、UglifyJS 等 DCE 工具“摇”掉这部分无效代码,构成完整的 Tree Shaking 操作。
五、最佳实践
虽然 Webpack 自 2.x 开始就原生支持 Tree Shaking 功能,但受限于 JS 的动态特性与模块的复杂性,直至最新的 5.0 版本依然没有解决许多代码副作用带来的问题,使得优化效果并不如 Tree Shaking 原本设想的那么完美,所以需要使用者有意识地优化代码结构,或使用一些补丁技术帮助 Webpack 更精确地检测无效代码,完成 Tree Shaking 操作。
1、避免无意义的赋值
使用 Webpack 时,需要有意识规避一些不必要的赋值操作,观察下面这段示例代码:
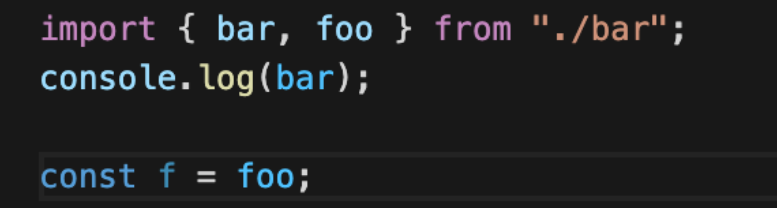
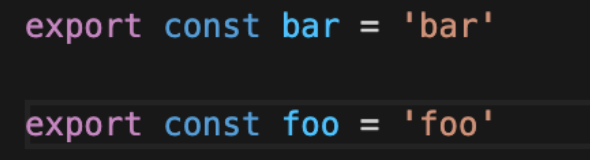
示例中 index.js 模块引用了 bar.js 模块的 foo 并赋值给 f 变量,但后续并没有继续用到 foo 或 f 变量,这种场景下 bar.js 模块导出的 foo 值实际上并没有被使用,理应被删除,但 Webpack 的 Tree Shaking 操作并没有生效,产物中依然保留 foo 导出:
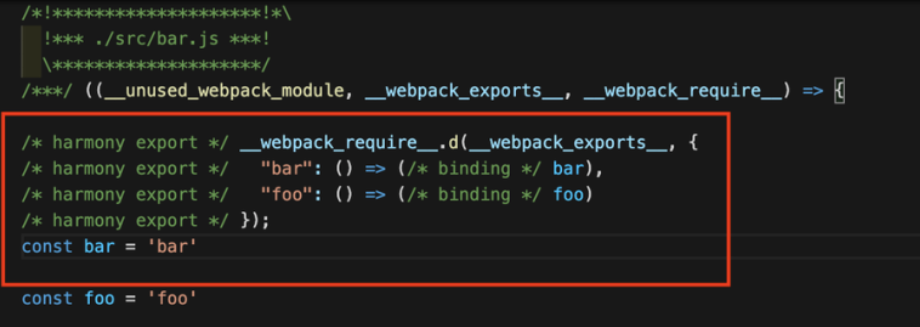
造成这一结果,浅层原因是 Webpack 的 Tree Shaking 逻辑停留在代码静态分析层面,只是浅显地判断:
-
模块导出变量是否被其它模块引用
-
引用模块的主体代码中有没有出现这个变量
没有进一步,从语义上分析模块导出值是不是真的被有效使用。
更深层次的原因则是 JavaScript 的赋值语句并不「纯」,视具体场景有可能产生意料之外的副作用,例如:
import { bar, foo } from "./bar";
let count = 0;
const mock = {}
Object.defineProperty(mock, 'f', {
set(v) {
mock._f = v;
count += 1;
}
})
mock.f = foo;
console.log(count);
示例中,对 mock 对象施加的 Object.defineProperty 调用,导致 mock.f = foo 赋值语句对 count 变量产生了副作用,这种场景下即使用复杂的动态语义分析也很难在确保正确副作用的前提下,完美地 Shaking 掉所有无用的代码枝叶。
因此,在使用 Webpack 时开发者需要有意识地规避这些无意义的重复赋值操作。
2、使用 #pure 标注纯函数调用
与赋值语句类似,JavaScript 中的函数调用语句也可能产生副作用,因此默认情况下 Webpack 并不会对函数调用做 Tree Shaking 操作。不过,开发者可以在调用语句前添加 /*#__PURE__*/ 备注,明确告诉 Webpack 该次函数调用并不会对上下文环境产生副作用
3、禁止 Babel 转译模块导入导出语句
Babel 是一个非常流行的 JavaScript 代码转换器,它能够将高版本的 JS 代码等价转译为兼容性更佳的低版本代码,使得前端开发者能够使用最新的语言特性开发出兼容旧版本浏览器的代码。
但 Babel 提供的部分功能特性会致使 Tree Shaking 功能失效,例如 Babel 可以将 import/export 风格的 ESM 语句等价转译为 CommonJS 风格的模块化语句,但该功能却导致 Webpack 无法对转译后的模块导入导出内容做静态分析
所以,在 Webpack 中使用 babel-loader 时,建议将 babel-preset-env 的 moduels 配置项设置为 false,关闭模块导入导出语句的转译。
4、优化导出值的粒度
Tree Shaking 逻辑作用在 ESM 的 export 语句上,因此对于下面这种导出场景:
export default {
bar: 'bar',
foo: 'foo'
}
即使实际上只用到 default 导出值的其中一个属性,整个 default 对象依然会被完整保留。所以实际开发中,应该尽量保持导出值颗粒度和原子性,上例代码的优化版本:
const bar = 'bar'
const foo = 'foo'
export {
bar,
foo
}
5、使用支持 Tree Shaking 的包
如果可以的话,应尽量使用支持 Tree Shaking 的 npm 包,例如:使用 lodash-es 替代 lodash ,或者使用 babel-plugin-lodash 实现类似效果
不过,并不是所有 npm 包都存在 Tree Shaking 的空间,诸如 React、Vue2 一类的框架原本已经对生产版本做了足够极致的优化,此时业务代码需要整个代码包提供的完整功能,基本上不太需要进行 Tree Shaking。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号