浅析从Diff策略及源码角度剖析diff算法
一般啥面试之类的都会问到循环加key值的作用,虽然一般都知道key的作用就是提高虚拟dom diff算法的效率,但是你知道它是怎样提升的吗?下面从diff策略及代码角度总结一下虚拟dom diff算法的全过程。
一、Diff算法简析
DIFF算法基于三个策略:
(1)Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。(tree diff)
(2)拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。(component diff)
(3)对于同一层级的一组子节点,它们可以通过唯一ID进行区分。(element diff)
DIFF算法在执行时有三个维度,分别是Tree DIFF、Component DIFF 和 Element DIFF,执行时按顺序依次执行,它们的差异仅仅因为DIFF粒度不同、执行先后顺序不同。
对于以上三个策略,diff算法分别对tree diff、component diff、element diff进行算法优化。
1、Tree DIFF
基于策略一,WebUI中DOM节点跨层级的移动操作少的可以忽略不计,vue对Virtual DOM树进行层级控制,只会对相同层级的DOM节点进行比较,即同一个父元素下的所有子节点,当发现节点已经不存在了,则会删除掉该节点下所有的子节点,不会再进行比较。这样只需要对DOM树进行一次遍历,就可以完成整个树的比较。复杂度变为O(n);
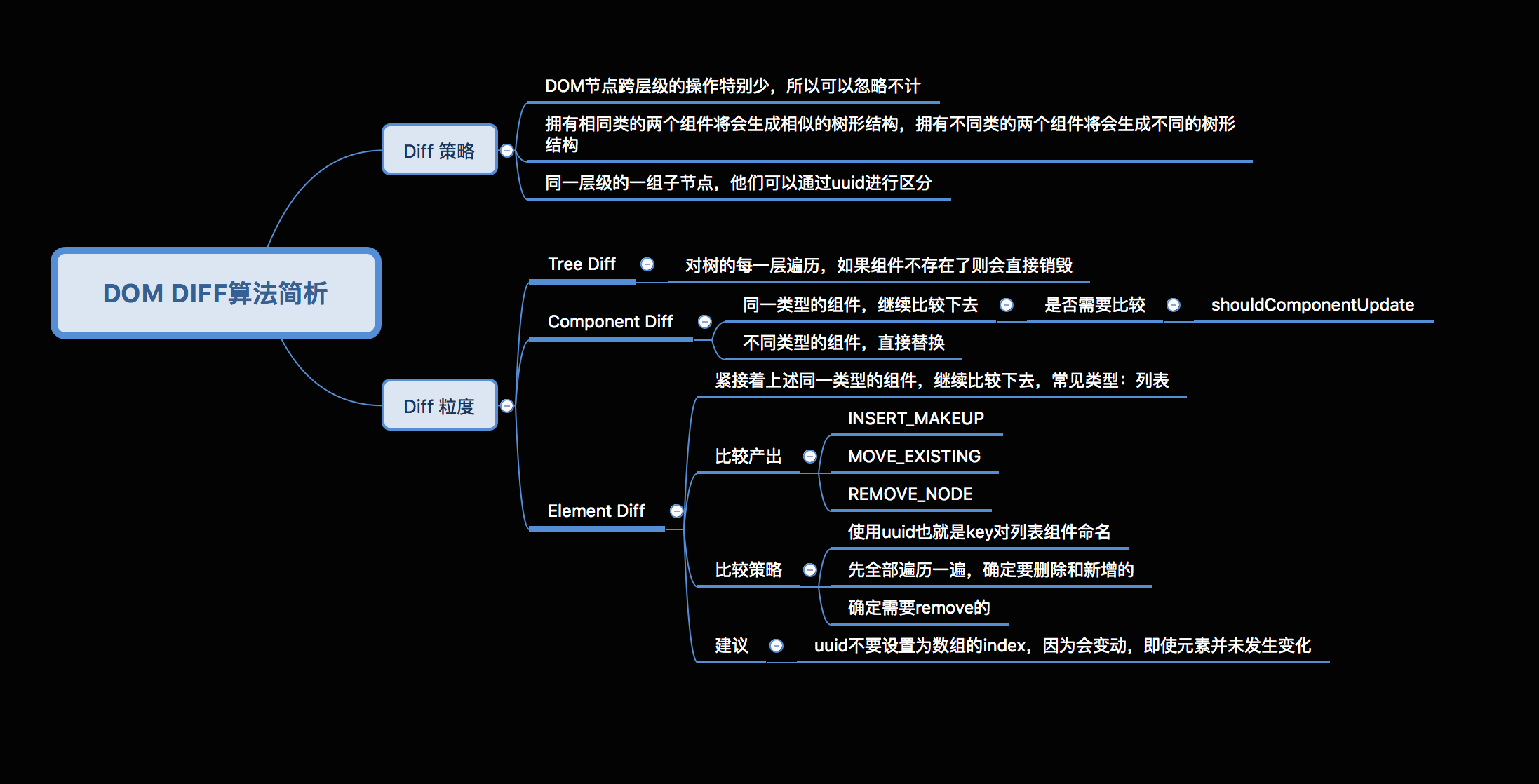
疑问:当我们的DOM节点进行跨层级操作时,diff会有怎么样的表现呢?
如下图所示,A节点及其子节点被整个移动到D节点下面去,由于diff算法只会简单的考虑同级节点的位置变换,而对于不同层级的节点,只有创建和删除操作。所以当根节点发现A节点消失了,就会删除A节点及其子节点,当D发现多了一个子节点A,就会创建新的A作为其子节点。
此时,diff的执行情况是:createA-->createB-->createC-->deleteA

Tree DIFF是对树的每一层进行遍历,如果某组件不存在了,则会直接销毁。如图所示,左边是旧属,右边是新属,第一层是R组件,一模一样,不会发生变化;第二层进入Component DIFF,同一类型组件继续比较下去,发现A组件没有,所以直接删掉A、B、C组件;继续第三层,重新创建A、B、C组件。
由此可以发现,当出现节点跨层级移动时,并不会出现想象中的移动操作,而是会进行删除,重新创建的动作,这是一种很影响性能的操作。因此官方也不建议进行DOM节点跨层级的操作。
2、Component DIFF
VUE、React之类的框架是基于组件构建应用的,对于组件间的比较所采用的策略也是非常简洁和高效的。
-
如果是同一个类型的组件,则按照原策略进行Virtual DOM比较。
-
如果不是同一类型的组件,则将其判断为dirty component,从而替换整个组价下的所有子节点。
-
如果是同一个类型的组件,有可能经过一轮Virtual DOM比较下来,并没有发生变化。如果我们能够提前确切知道这一点,那么就可以省下大量的diff运算时间。因此,React允许用户通过shouldComponentUpdate()来判断该组件是否需要进行diff算法分析。
如下图所示,当组件D变为组件G时,即使这两个组件结构相似,一旦diff算法判断D和G是不同类型的组件,就不会比较两者的结构,而是直接删除组件D,然后重新创建组件G及其子节点。
虽然当两个组件是不同类型但是结构相似时,进行diff算法分析会影响性能,但是比较不同类型的组件存在相似DOM树的情况在实际开发过程中很少出现,因此这种极端因素很难在实际开发过程中造成重大影响。
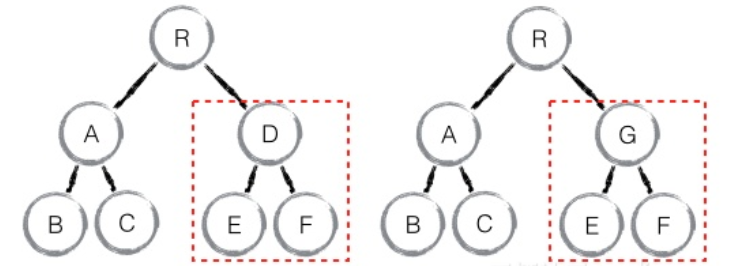
如图所示,第一层遍历完,进行第二层遍历时,D和G组件是不同类型的组件,不同类型组件直接进行替换,将D删掉,再将G重建。
3、Element DIFF
当节点属于同一层级时,diff提供了3种节点操作,分别为INSERT_MARKUP(插入),MOVE_EXISTING(移动),REMOVE_NODE(删除)。
- INSERT_MARKUP:新的组件类型不在旧集合中,即全新的节点,需要对新节点进行插入操作。
- MOVE_EXISTING:旧集合中有新组件类型,且element是可更新的类型,这时候就需要做移动操作,可以复用以前的DOM节点。
- REMOVE_NODE:旧组件类型,在新集合里也有,但对应的element不同则不能直接复用和更新,需要执行删除操作,或者旧组件不在新集合里的,也需要执行删除操作。
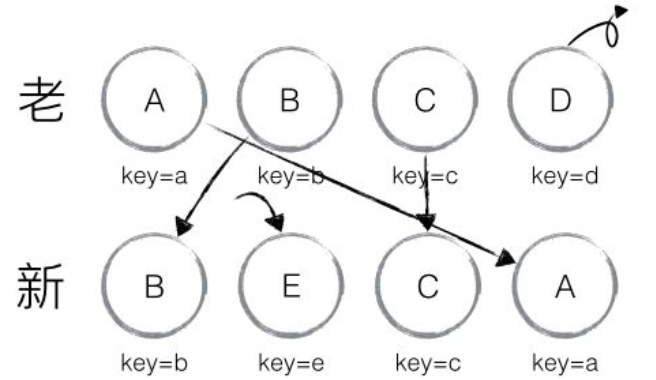
Element DIFF紧接着以上同一类型组件继续比较下去,常见类型就是列表。同一个列表由旧变新有三种行为,插入、移动和删除,它的比较策略是对于每一个列表指定key,先将所有列表遍历一遍,确定要新增和删除的,再确定需要移动的。如图所示,第一步将D删掉,第二步增加E,再次执行时A和B只需要移动位置即可。
二、当数据发生变化时,vue是怎么更新节点的?
要知道渲染真实DOM的开销是很大的,比如有时候我们修改了某个数据,如果直接渲染到真实dom上会引起整个dom树的重绘和重排,有没有可能我们只更新我们修改的那一小块dom而不要更新整个dom呢?diff算法能够帮助我们。
我们先根据真实DOM生成一颗virtual DOM,当virtual DOM某个节点的数据改变后会生成一个新的Vnode,然后Vnode和oldVnode作对比,发现有不一样的地方就直接修改在真实的DOM上,然后使oldVnode的值为Vnode。
diff的过程就是调用名为patch的函数,比较新旧节点,一边比较一边给真实的DOM打补丁。
三、virtual DOM和真实DOM的区别?
virtual DOM是将真实的DOM的数据抽取出来,以对象的形式模拟树形结构。比如dom是这样的:
<div>
<p>123</p>
</div>
对应的virtual DOM(伪代码):
var Vnode = {
tag: 'div',
children: [
{ tag: 'p', text: '123' }
]
};
注意:VNode和oldVNode都是对象,一定要记住。
四、diff的比较方式?
在采取diff算法比较新旧节点的时候,比较只会在同层级进行, 不会跨层级比较。
<div>
<p>123</p>
</div>
<div>
<span>456</span>
</div>
上面的代码会分别比较同一层的两个div以及第二层的p和span,但是不会拿不同层级的div和span作比较。
详情可看之前的博客:图解vue中 v-for 的 :key 的作用,虚拟dom Diff算法
五、diff流程图
当数据发生改变时,set方法会调用Dep.notify通知所有订阅者Watcher,订阅者就会调用patch给真实的DOM打补丁,更新相应的视图。下面是流程图:
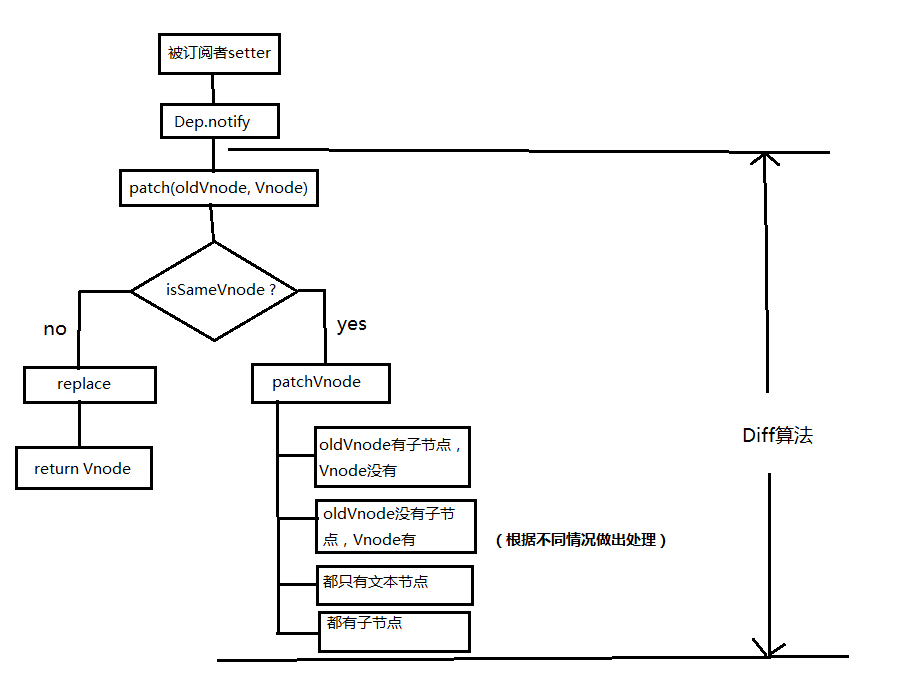
具体分析patch是怎么打补丁的(代码只保留核心部分)
function patch (oldVnode, vnode) {
// some code
if (sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode)
} else {
const oEl = oldVnode.el // 当前oldVnode对应的真实元素节点
let parentEle = api.parentNode(oEl) // 父元素
createEle(vnode) // 根据Vnode生成新元素
if (parentEle !== null) {
api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)) // 将新元素添加进父元素
api.removeChild(parentEle, oldVnode.el) // 移除以前的旧元素节点
oldVnode = null
}
}
// some code
return vnode
}
patch函数接收两个参数oldVnode和Vnode分别代表新的节点和之前的旧节点。先判断2个节点是否值得比较,如果不值得比较,那么就:
(1)获取真实dom元素节点及其父元素;
(2)根据vNode创建新的dom元素
(3)如果父元素存在,那么将vNode生成的元素插入到老元素后面
(4)然后再删除old老元素
如果值得比较,那么就执行下面一套复杂的逻辑处理:
1、判断两节点是否值得比较,值得比较则执行patchVnode(下面就可以看到key值的作用啦)
function sameVnode (a, b) {
return (
a.key === b.key && // key值
a.tag === b.tag && // 标签名
a.isComment === b.isComment && // 是否为注释节点
// 是否都定义了data,data包含一些具体信息,例如onclick , style
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b) // 当标签是<input>的时候,type必须相同
)
}
2、不值得比较则用Vnode替换oldVnode
如果两个节点都是一样的,那么就深入检查他们的子节点。如果两个节点不一样那就说明Vnode完全被改变了,就可以直接替换oldVnode。
虽然这两个节点不一样但是他们的子节点一样怎么办?别忘了,diff可是逐层比较的,如果第一层不一样那么就不会继续深入比较第二层了。(我在想这算是一个缺点吗?相同子节点不能重复利用了...)
3、值得比较时patchVnode的执行逻辑
当我们确定两个节点值得比较之后我们会对两个节点指定patchVnode方法。那么这个方法做了什么呢?
patchVnode (oldVnode, vnode) {
const el = vnode.el = oldVnode.el
let i, oldCh = oldVnode.children, ch = vnode.children
if (oldVnode === vnode) return
if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) {
api.setTextContent(el, vnode.text)
}else {
updateEle(el, vnode, oldVnode)
if (oldCh && ch && oldCh !== ch) {
updateChildren(el, oldCh, ch)
}else if (ch){
createEle(vnode) //create el's children dom
}else if (oldCh){
api.removeChildren(el)
}
}
}
这个函数做了以下事情:
- 找到对应的真实dom,称为
el - 判断
Vnode和oldVnode是否指向同一个对象,如果是,那么直接return - 如果他们都有文本节点并且不相等,那么将
el的文本节点设置为Vnode的文本节点。 - 如果
oldVnode有子节点而Vnode没有,则删除el的子节点 - 如果
oldVnode没有子节点而Vnode有,则将Vnode的子节点真实化之后添加到el - 如果两者都有子节点,则执行
updateChildren函数比较子节点,这一步很重要
其他几个点都很好理解,我们详细来讲一下updateChildren
4、updateChildren
代码量很大,不方便一行一行的讲解,所以下面结合一些示例图来描述一下。
updateChildren (parentElm, oldCh, newCh) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) { // 对于vnode.key的比较,会把oldVnode = null
oldStartVnode = oldCh[++oldStartIdx]
}else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
}else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
}else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
api.insertBefore(parentElm, oldStartVnode.el, api.nextSibling(oldEndVnode.el))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
api.insertBefore(parentElm, oldEndVnode.el, oldStartVnode.el)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}else {
// 使用key时的比较
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) // 有key生成index表
}
idxInOld = oldKeyToIdx[newStartVnode.key]
if (!idxInOld) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
newStartVnode = newCh[++newStartIdx]
}
else {
elmToMove = oldCh[idxInOld]
if (elmToMove.sel !== newStartVnode.sel) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
}else {
patchVnode(elmToMove, newStartVnode)
oldCh[idxInOld] = null
api.insertBefore(parentElm, elmToMove.el, oldStartVnode.el)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].el
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx)
}else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
先说一下这个函数做了什么
- 将
Vnode的子节点Vch和oldVnode的子节点oldCh提取出来 oldCh和vCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和vCh至少有一个已经遍历完了,就会结束比较。
5、图解updateChildren
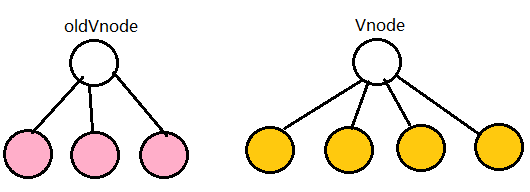
我们将它们取出来并分别用s和e指针指向它们的头child和尾child
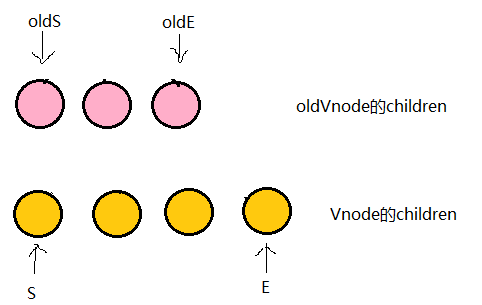
现在分别对oldS、oldE、S、E两两做sameVnode比较,有四种比较方式,当其中两个能匹配上那么真实dom中的相应节点会移到Vnode相应的位置,这句话有点绕,打个比方
- 如果是oldS和E匹配上了,那么真实dom中的第一个节点会移到最后
- 如果是oldE和S匹配上了,那么真实dom中的最后一个节点会移到最前,匹配上的两个指针向中间移动
- 如果四种匹配没有一对是成功的,那么遍历
oldChild,S挨个和他们匹配,匹配成功就在真实dom中将成功的节点移到最前面,如果依旧没有成功的,那么将S对应的节点插入到dom中对应的oldS位置,oldS和S指针向中间移动。
如下图:

(1)第一步
oldS = a, oldE = d;
S = a, E = b;
oldS和S匹配,则将dom中的a节点放到第一个,已经是第一个了就不管了,此时dom的位置为:a b d
此时继续比较的:old: b d ;new:c d b
(2)第二步
oldS = b, oldE = d;
S = c, E = b;
oldS和E匹配,就将原本的b节点移动到最后,因为E是最后一个节点,他们位置要一致,这就是上面说的:当其中两个能匹配上那么真实dom中的相应节点会移到Vnode相应的位置,此时dom的位置为:a d b
此时继续比较的:old: d ;new:c d
(3)第三步
oldS = d, oldE = d;
S = c, E = d;
oldE和E匹配,位置不变此时dom的位置为:a d b
此时继续比较的:old 已比较完;new仅剩下c
(4)第四步
oldS++;
oldE--;
oldS > oldE;
遍历结束,说明oldCh先遍历完。就将剩余的vCh节点根据自己的的index插入到真实dom中去,此时dom位置为:a c d b。
一次模拟完成,这个匹配过程的结束有两个条件:
oldS > oldE表示oldCh先遍历完,那么就将多余的vCh根据index添加到dom中去(如上图)S > E表示vCh先遍历完,那么就在真实dom中将区间为[oldS, oldE]的多余节点删掉
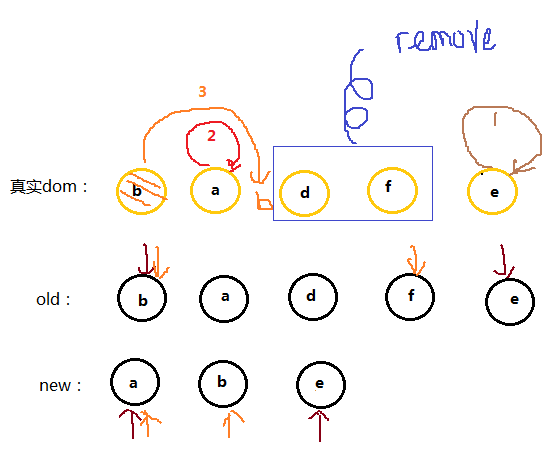
再比如:

当这些节点sameVnode成功后就会紧接着执行patchVnode了,可以看一下上面的代码
if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
}
就这样层层递归下去,直到将oldVnode和Vnode中的所有子节点比对完。也将dom的所有补丁都打好啦。那么现在再回过去看updateChildren的代码会不会容易很多呢。
六、基于Diff的开发建议
1、基于tree diff:
(1)开发组件时,注意保持DOM结构的稳定;即尽可能少地动态操作DOM结构,尤其是移动操作。
(2)当节点数过大或者页面更新次数过多时,页面卡顿的现象会比较明显。这时可以通过 CSS 隐藏或显示节点,而不是真的移除或添加 DOM 节点。
2、基于component diff:
(1)注意使用 shouldComponentUpdate() 来减少组件不必要的更新。
(2)对于类似的结构应该尽量封装成组件,既减少代码量,又能减少component diff的性能消耗。
3、基于element diff:
(1)对于列表结构,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,在一定程度上会影响渲染性能。
(2)循环渲染的必须加上key值,并且保证key是唯一不可变的值。不建议使用数组的index,因为数组变化了,index会变,但是这时候node list 的dom元素可能并没有变。
其他欢迎补充。
虚拟DOM、DIFF算法在前端领域如雷贯耳,以前研究过,但是理论性的东西确实容易记不清,只记得一个标识一个标识比对看是否更新,其他详细好像有点似懂非懂,所以今天又好好查了下,主要参考这篇:
详解vue的diff算法:https://juejin.cn/post/6844903607913938951

 浙公网安备 33010602011771号
浙公网安备 33010602011771号