浅析AST抽象语法树及如何利用AST转换JS代码
在学习AST之前,可以结合此篇博客(浅析代码编译过程 )一起看。
抽象语法树(Abstract Syntax Tree)也称为AST语法树,指的是源代码语法所对应的树状结构。也就是说,对于一种具体编程语言下的源代码,通过构建语法树的形式将源代码中的语句映射到树中的每一个节点上。
如果你查看目前任何主流的项目中的 devDependencies,会发现前些年的不计其数的插件诞生。我们归纳一下有:javascript转译、代码压缩、css预处理器、elint、pretiier,等。有很多js模块我们不会在生产环境用到,但是它们在我们的开发过程中充当着重要的角色。所有的上述工具,不管怎样,都建立在了AST这个巨人的肩膀上。

所有的上述工具,不管怎样,都建立在了AST这个巨人的肩膀上。
一、JavaScript语法解析
1、什么是AST抽象语法树
It is a hierarchical program representation that presents source code structure according to the grammar of a programming language, each AST node corresponds to an item of a source code.
估计很多同学看完这段官方的定义一脸懵逼,可以通过一个简单的例子来看语法树具体长什么样子。有如下代码:
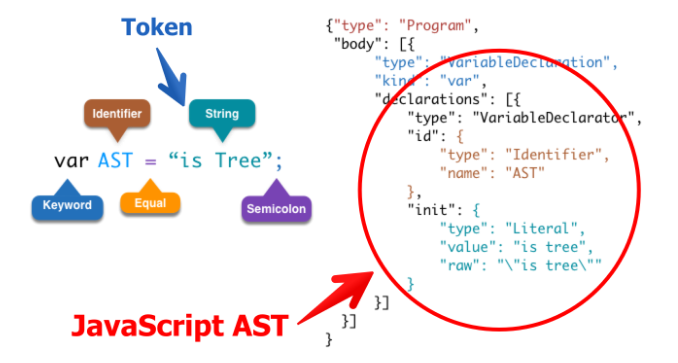
我们可以发现,程序代码本身可以被映射成为一棵语法树(实际上,真正AST每个节点会有更多的信息。但是,这是大体思想。从纯文本中,我们将得到树形结构的数据,每个条目和树中的节点一一对应。),而通过操纵语法树,我们能够精准的获得程序代码中的某个节点。例如声明语句,赋值语句,而这是用正则表达式所不能准确体现的地方。
JavaScript的语法解析器Espsrima提供了一个在线解析的工具,你可以借助于这个工具,将JavaScript代码解析为一个JSON文件表示的树状结构。
2、有什么用
聊到AST的用途,其应用非常广泛,下面我简单罗列了一些:
IDE的错误提示、代码格式化、代码高亮、代码自动补全等JSLint、JSHint对代码错误或风格的检查等webpack、rollup进行代码打包等CoffeeScript、TypeScript、JSX等转化为原生Javascript
其实它的用途,还不止这些,如果说你已经不满足于实现枯燥的业务功能,想写出类似react、vue这样的牛逼框架,或者想自己搞一套类似webpack、rollup这样的前端自动化打包工具,那你就必须弄懂AST。
抽象语法树的作用非常的多,比如编译器、IDE、压缩优化代码等。在JavaScript中,虽然我们并不会常常与AST直接打交道,但却也会经常的涉及到它。例如使用UglifyJS来压缩代码,实际这背后就是在对JavaScript的抽象语法树进行操作。 在一些实际开发过程中,我们也会用到抽象语法树,下面通过一个小例子来看看怎么进行JavaScript的语法解析以及对节点的遍历与操纵。
二、如何生成AST?
在了解如何生成AST之前,有必要了解一下Parser(常见的Parser有esprima、traceur、acorn、shift等)。JS Parser其实是一个解析器,它是将js源码转化为抽象语法树(AST)的解析器。整个解析过程主要分为以下两个步骤:
- 分词(也就是词法分析):将整个代码字符串分割成最小语法单元数组
- 语法分析:在分词基础上建立分析语法单元之间的关系
语法单元是被解析语法当中具备实际意义的最小单元,简单的来理解就是自然语言中的词语。举个例子来说,下面这段话:“2019年是祖国70周年”,我们可以把这句话拆分成最小单元,即:2019年、是、祖国、70、周年。
这就是我们所说的分词,也是最小单元,因为如果我们把它再拆分出去的话,那就没有什么实际意义了。
Javascript 代码中的语法单元主要包括以下这么几种:
- 关键字:例如
var、let、const等 - 标识符:没有被引号括起来的连续字符,可能是一个变量,也可能是
if、else这些关键字,又或者是true、false这些内置常量 - 运算符:
+、-、*、/等 - 数字:像十六进制,十进制,八进制以及科学表达式等语法
- 字符串:因为对计算机而言,字符串的内容会参与计算或显示
- 空格:连续的空格,换行,缩进等
- 注释:行注释或块注释都是一个不可拆分的最小语法单元
- 其他:大括号、小括号、分号、冒号等
如果我们以最简单的复制语句为例的话,如下:
var a = 1
通过分词,我们可以得到如下结果:
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": ";"
}
]
2、什么是语法分析?
上面我们已经得到了我们分词的结果,需要将词汇进行一个立体的组合,确定词语之间的关系,确定词语最终的表达含义。
简单来说语法分析是对语句和表达式识别,确定之前的关系,这是个递归过程。
上面我们通过语法分析,可以得到如下结果:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
这就是 var a = 1 所转换的 AST;(这里推荐一下astexplorer AST的可视化工具,astexplorer,可以直接进行对代码进行AST转换~)
三、示例代码解析AST如何用
小需求 :我们将构建一个简单的静态分析器,它可以从命令行进行运行。它能够识别下面几部分内容:
- 已声明但没有被调用的函数
- 调用了未声明的函数
- 被调用多次的函数
现在我们已经知道了可以将代码映射为AST进行语法解析,从而找到这些节点。但是,我们仍然需要一个语法解析器才能顺利的进行工作,在JavaScript的语法解析领域,一个流行的开源项目是Esprima,我们可以利用这个工具来完成任务。此外,我们需要借助Node来构建能够在命令行运行的JS代码。
1、准备工作
为了能够完成后面的工作,你需要确保安装了Node环境。首先创建项目的基本目录结构,以及初始化NPM。
mkdir esprima-tutorial
cd esprima-tutorial
npm install esprima --save
在根目录新建index.js文件,初试代码如下
var fs = require('fs'),
esprima = require('esprima');
function analyzeCode(code) {
// 1
}
// 2
if (process.argv.length < 3) {
console.log('Usage: index.js file.js');
process.exit(1);
}
// 3
var filename = process.argv[2];
console.log('Reading ' + filename);
var code = fs.readFileSync(filename);
analyzeCode(code);
console.log('Done');
在上面的代码中:
(1)函数analyzeCode用于执行主要的代码分析工作,这里我们暂时预留下来这部分工作待后面去解决。
(2)我们需要确保用户在命令行中指定了分析文件的具体位置,这可以通过查看process.argv的长度来得到。为什么?你可以参考Node的官方文档:
The first element will be ‘node’, the second element will be the name of the JavaScript file. The next elements will be any additional command line arguments.
(3)获取文件,并将文件传入到analyzeCode函数中进行处理
2、解析代码和遍历AST
借助Esprima解析代码非常简单,只要使用一个方法即可:
var ast = esprima.parse(code);
esprima.parse()方法接收两种类型的参数:字符串或Node的Buffer对象,它也可以收附加的选项作为参数。解析后返回结果即为抽象语法树(AST),AST遵守Mozilla SpiderMonkey的解析器API。例如代码:
var answer = 6 * 7;
解析后的结果为:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "answer"
},
"init": {
"type": "BinaryExpression",
"operator": "*",
"left": {
"type": "Literal",
"value": 6,
"raw": "6"
},
"right": {
"type": "Literal",
"value": 7,
"raw": "7"
}
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
代码:6*7,解析结果为:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "BinaryExpression",
"operator": "*",
"left": {
"type": "Literal",
"value": 6,
"raw": "6"
},
"right": {
"type": "Literal",
"value": 7,
"raw": "7"
}
}
}
],
"sourceType": "script"
}
可以自行在此解析工具里试试:https://esprima.org/demo/parse.html#
我们可以发现每个节点都有一个type,根节点的type为Program。type也是所有节点都共有的,其他的属性依赖于节点的type。例如上面实例的程序中,我们可以发现根节点下面的子节点的类型为EspressionStatement,依此类推。
为了能够分析代码,我们需要对得到的AST进行遍历,我们可以借助Estraverse进行节点的遍历。执行如下命令进行安装该NPM包:
npm install estraverse --save
基本用法如下:
function analyzeCode(code) {
var ast = esprima.parse(code);
estraverse.traverse(ast, {
enter: function (node) {
console.log(node.type);
}
});
}
上面的代码会输出遇到的语法树上每个节点的类型。
3、获取分析数据
为了完成需求,我们需要遍历语法树,并统计每个函数调用和声明的次数。因此,我们需要知道两种节点类型。首先是函数声明:
{
"type": "FunctionDeclaration",
"id": {
"type": "Identifier",
"name": "myAwesomeFunction"
},
"params": [
...
],
"body": {
"type": "BlockStatement",
"body": [
...
]
}
}
对函数声明而言,其节点类型为FunctionDeclaration,函数的标识符(即函数名)存放在id节点中,其中name子属性即为函数名。params和body分别为函数的参数列表和函数体。
我们再来看函数调用:
"expression": {
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "myAwesomeFunction"
},
"arguments": []
}
对函数调用而言,即节点类型为CallExpression,callee指向被调用的函数。有了上面的了解,我们可以继续完成我们的程序如下:
function analyzeCode(code) {
var ast = esprima.parse(code);
var functionsStats = {}; //1
var addStatsEntry = function (funcName) { //2
if (!functionsStats[funcName]) {
functionsStats[funcName] = { calls: 0, declarations: 0 };
}
};
// 3
estraverse.traverse(ast, {
enter: function (node) {
if (node.type === 'FunctionDeclaration') {
addStatsEntry(node.id.name); //4
functionsStats[node.id.name].declarations++;
} else if (node.type === 'CallExpression' && node.callee.type === 'Identifier') {
addStatsEntry(node.callee.name);
functionsStats[node.callee.name].calls++; //5
}
}
});
}
(1)我们创建了一个对象functionStats用来存放函数的调用和声明的统计信息,函数名作为key。
(2)函数addStatsEntry用于实现存放统计信息。
(3)遍历AST
(4)如果发现了函数声明,增加一次函数声明
(5)如果发现了函数调用,增加一次函数调用
4、处理结果
最后进行结果的处理,我们只需要遍历查看functionStats中的信息就可以得到结果。创建结果处理函数如下:
function processResults(results) {
for (var name in results) {
if (results.hasOwnProperty(name)) {
var stats = results[name];
if (stats.declarations === 0) {
console.log('Function', name, 'undeclared');
} else if (stats.declarations > 1) {
console.log('Function', name, 'decalred multiple times');
} else if (stats.calls === 0) {
console.log('Function', name, 'declared but not called');
}
}
}
}
然后,在analyzeCode函数的末尾调用该函数即可,如下:processResults(functionsStats);
5、测试
创建测试文件demo.js如下:
function declaredTwice() {}
function main() {
undeclared();
}
function unused() {}
function declaredTwice() {}
main();
我们看到declaredTwice声明了2次,undeclared未声明,unused声明了但未调用。执行如下命令:
node index.js demo.js
你将得到如下的处理结果:
Reading demo.js
Function declaredTwice decalred multiple times
Function undeclared undeclared
Function unused declared but not called
Done
四、babel如何利用AST转换JS代码的
我相信大部分同学对 babel 这个库不陌生,现在的做前端模块化开发过程中中一定少不了它,因为它可以帮你将 ECMAScript 2015+ 版本的代码转换为向后兼容的 JavaScript 语法,以便能够运行在当前和旧版本的浏览器或其他环境中,你不用为新语法的兼容性考虑~
而实际上呢,babel 中的很多功能都是靠修改 AST 实现的。
首先,我们来看一个简单的例子,我们如何将 es6 中的 箭头函数 转换成 es5 中的 普通函数,即:
const sum=(a,b)=>a+b;
// 我们如何将上面简单的 sum 箭头函数转换成下面的形式:
const sum = function(a,b){
return a+b;
}
想想看,有什么思路?如果说你不了解 AST 的话,这无疑是一个很困难的问题,根本无从下手,如果你了解 AST 的话,这将是一个非常 easy 的例子。接下来我们看看如何实现:
1、安装依赖
需要操作 AST 代码,这里,我们需要借助两个库,分别是 @babel/core 和 babel-types。其中 @babel/core 是 babel 的核心库,用来实现核心转换引擎,babel-types 类型判断,用于生成AST零部件。
cd 到一个你喜欢的目录,通过 npm -y init 初始化操作后,通过 npm i @babel/core babel-types -D 安装依赖。
2、目标分析
要进行转换之前,我们需要进行分析,首先我们先通过 astexplorer 查看目标代码跟我们现在的代码有什么区别。
源代码的 AST 结构如下:
// 源代码的 AST
{
"type": "Program",
"start": 0,
"end": 21,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 21,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 20,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "sum"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 10,
"end": 20,
"id": null,
"expression": true,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 11,
"end": 12,
"name": "a"
},
{
"type": "Identifier",
"start": 13,
"end": 14,
"name": "b"
}
],
"body": {
"type": "BinaryExpression",
"start": 17,
"end": 20,
"left": {
"type": "Identifier",
"start": 17,
"end": 18,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 19,
"end": 20,
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
目标代码的 AST 结构如下:
// 目标代码的 `AST`
{
"type": "Program",
"start": 0,
"end": 48,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 48,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 47,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "sum"
},
"init": {
"type": "FunctionExpression",
"start": 12,
"end": 47,
"id": null,
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 22,
"end": 23,
"name": "a"
},
{
"type": "Identifier",
"start": 25,
"end": 26,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 28,
"end": 47,
"body": [
{
"type": "ReturnStatement",
"start": 32,
"end": 45,
"argument": {
"type": "BinaryExpression",
"start": 39,
"end": 44,
"left": {
"type": "Identifier",
"start": 39,
"end": 40,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 43,
"end": 44,
"name": "b"
}
}
}
]
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
其中里面的 start 和 end 我们不用在意,其只是为了标记其所在代码的位置。
我们关心的是 body 里面的内容,通过对比,我们发现主要不同就在于 init 这一段,一个是 ArrowFunctionExpression , 另一个是 FunctionExpression , 我们只需要将 ArrowFunctionExpression 下的内容改造成跟 FunctionExpression 即可。
3、开始操作
我们建一个 arrow.js 的文件,引入上面的两个库,即
//babel 核心库,用来实现核心转换引擎
const babel = require('@babel/core')
//类型判断,生成AST零部件
const types = require('babel-types')
//源代码
const code = `const sum=(a,b)=>a+b;` //目标代码 const sum = function(a,b){ return a + b }
这里我们需要用到 babel 中的 transform 方法,它可以将 js 代码转换成 AST ,过程中可以通过使用 plugins 对 AST 进行改造,最终生成新的 AST 和 js 代码,其整个过程用网上一个比较贴切的图就是:

关于 babel transform 详细用法,这里不多做讨论,感兴趣的话可以去官网了解。其主要用法如下:
//transform方法转换code
//babel先将代码转换成ast,然后进行遍历,最后输出code
let result = babel.transform(code,{
plugins:[
{
visitor
}
]
})
其核心在于插件 visitor 的实现。它是一个插件对象,可以对特定类型的节点进行处理,这里我们需要处理的节点是ArrowFunctionExpression,它常见的配置方式有两种:
一种是单一处理,结构如下,其中 path 代表当前遍历的路径 path.node 代表当前变量的节点
let visitor = {
ArrowFunctionExpression(path){
}
}
另一种是用于输入和输出双向处理,结构如下,参数 node 表示当前遍历的节点
let visitor = {
ArrowFunctionExpression : {
enter(node){
},
leave(node){
}
}
}
这里我们只需要处理一次,所以采用第一种方式。
通过分析目标代码的 AST,我们发现,需要一个 FunctionExpression , 这时候我们就需要用到 babel-types ,它的作用就是帮助我们生产这些节点。
我们通过其 npm 包的文档查看,构建一个 FunctionExpression 需要的参数如下:

AST 我们可以看到其 id 为 null,params 是原 ArrowFunctionExpression 中的 params,body 是一个blockStatement,我们也可以通过查看 babel-types 文档,用 t.blockStatement(body, directives) 来创建,依次类推,照猫画虎,最终得到的结果如下:
//原 params
let params = path.node.params;
//创建一个blockStatement
let blockStatement = types.blockStatement([
types.returnStatement(types.binaryExpression(
'+',
types.identifier('a'),
types.identifier('b')
))
]);
//创建一个函数
let func = types.functionExpression(null, params, blockStatement, false, false);
最后通过 path.replaceWith(func); 将其替换即可;完成代码如下:
//babel 核心库,用来实现核心转换引擎
const babel = require('@babel/core')
//类型判断,生成AST零部件
const types = require('babel-types')
//源代码
const code = `const sum=(a,b)=>a+b;` //目标代码 const sum = function(a,b){ return a + b }
//插件对象,可以对特定类型的节点进行处理
let visitor = {
//代表处理 ArrowFunctionExpression 节点
ArrowFunctionExpression(path){
let params = path.node.params;
//创建一个blockStatement
let blockStatement = types.blockStatement([
types.returnStatement(types.binaryExpression(
'+',
types.identifier('a'),
types.identifier('b')
))
]);
//创建一个函数
let func = types.functionExpression(null, params, blockStatement, false, false);
//替换
path.replaceWith(func);
}
}
//transform方法转换code
//babel先将代码转换成ast,然后进行遍历,最后输出code
let result = babel.transform(code,{
plugins:[
{
visitor
}
]
})
console.log(result.code);
执行代码,打印结果如下:

至此,我们的函数转换完成,达到预期效果。
returnStatement 其实也是跟源代码的 returnStatement 是一致的,我们只需要拿来复用即可,因此上述的代码还可以改成下面这样:
let blockStatement = types.blockStatement([
types.returnStatement(path.node.body)
]);
五、利用AST将class类转换为es5
AST 进行代码改造,不妨趁热打铁,再来试试下面这个问题。如何将 es6 中的 class 改造成 es5 的 function 形式
// 源代码
class Person {
constructor(name) {
this.name=name;
}
sayName() {
return this.name;
}
}
// 目标代码
function Person(name) {
this.name = name;
}
Person.prototype.getName = function () {
return this.name;
};
有了上面的基础,照猫画虎即可:分别比对2种AST语法差异,然后进行比对替换。下面是核心转换插件
ClassDeclaration (path) {
let node = path.node; //当前节点
let id = node.id; //节点id
let methods = node.body.body; // 方法数组
let constructorFunction = null; // 构造方法
let functions = []; // 目标方法
methods.forEach(method => {
//如果是构造方法
if ( method.kind === 'constructor' ) {
constructorFunction = types.functionDeclaration(id, method.params, method.body, false, false);
functions.push(constructorFunction)
} else {
//普通方法
let memberExpression = types.memberExpression(types.memberExpression(id, types.identifier('prototype'), false), method.key, false);
let functionExpression = types.functionExpression(null, method.params, method.body, false, false);
let assignmentExpression = types.assignmentExpression('=', memberExpression, functionExpression);
functions.push(types.expressionStatement(assignmentExpression));
}
})
//判断,replaceWithMultiple用于多重替换
if(functions.length === 1){
path.replaceWith(functions[0])
}else{
path.replaceWithMultiple(functions)
}
}
日常工作中,我们大多数时候关注的只是 js 代码本身,现在可以尝试着通过 AST 去重新认识和诠释自己的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号