正则中\1、\2的理解,利用正则找出重复最多的字符
今天看到一个题,是利用正则找重复最多的字符
let str = 'asss23sjdssskssa7lsssdkjsssdss'
const arr = str.split(/\s*/) // 把字符串转换为数组
const str2 = arr.sort().join('') // 首先进行排序,这样结果会把相同的字符放在一起,然后再转换为字符串
let value = ''
let index = 0
str2.replace(/(\w)\1*/g, function($0, $1) { // 匹配字符
if (index < $0.length) {
index = $0.length // index是出现次数
value = $1 // value是对应字符
}
})
console.log(`最多的字符: ${value} ,重复的次数: ${index}`) // s 17
主要是中间一段正则比较感兴趣,涉及到 \1,\2的理解
单独斜杠的 \1 , \2 表示的是反向引用:
‘\1’ 匹配的是 所获取的第1个()匹配的引用。例如,’(\d)\1’ 匹配两个连续数字字符。如33aa 中的33
‘\2’ 匹配的是 所获取的第2个()匹配的引用。例如,’(\d)(a)\1’ 匹配第一是数字第二是字符a,第三\1必须匹配第一个一样的数字重复一次,也就是被引用一次。如9a9 被匹配,但9a8不会被匹配,因为第三位的\1必须是9才可以,‘(\d)(a)\2’ 匹配第一个是一个数字,第二个是a,第三个\2必须是第二组()中匹配一样的,如,8aa被匹配,但8ab,7a7不会被匹配,第三位必须是第二组字符的复制版,也是就引用第二组正则的匹配内容。
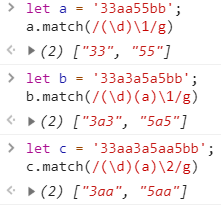

这样其实很明显了,规则就是:在 \2 的这个位置引用同第2个分组的一模一样的东西
所以上面的正则就很好理解了:/(\w)\1*/g
(\w):()分组,\w 匹配数字字母下划线
\1:引用该分组的内容
*:匹配前面的子表达式零次或多次。zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。
所以上面的函数就很好理解啦。
上面是使用replace方法得到的结果,
stringObject.replace(regexp/substr,replacement)
字符串 stringObject 的 replace() 方法执行的是查找并替换的操作。它将在 stringObject 中查找与 regexp 相匹配的子字符串,然后用 replacement 来替换这些子串。如果 regexp 具有全局标志 g,那么 replace() 方法将替换所有匹配的子串。否则,它只替换第一个匹配子串。
replacement 可以是字符串,也可以是函数。如果它是字符串,那么每个匹配都将由字符串替换。但是 replacement 中的 $ 字符具有特定的含义。如下表所示,它说明从模式匹配得到的字符串将用于替换。
注意:ECMAScript v3 规定,replace() 方法的参数 replacement 可以是函数而不是字符串。在这种情况下,每个匹配都调用该函数,它返回的字符串将作为替换文本使用。该函数的第一个参数是匹配模式的字符串。接下来的参数是与模式中的子表达式匹配的字符串,可以有 0 个或多个这样的参数。接下来的参数是一个整数,声明了匹配在 stringObject 中出现的位置。最后一个参数是 stringObject 本身。
其实再利用一次sort()也可以实现需求,如下
function sortNumber(a,b){
return b.length - a.length
}
let str = 'asss23sjdssskssa7lsssdkjsssdss'
const arr = str.split(/\s*/) // 把字符串转换为数组
const str2 = arr.sort().join('') // 首先进行排序,这样结果会把相同的字符放在一起,然后再转换为字符串
let ans = str2.match(/(\w)\1*/g)
ans.sort(sortNumber)
ans // ["sssssssssssssssss", "ddd", "aa", "jj", "kk", "2", "3", "7", "l"]
再利用sort()排序,就可以拿到最多的字符

 浙公网安备 33010602011771号
浙公网安备 33010602011771号