
使用webpasser抓取某笑话网站整站内容
使用webpasser框架抓取某一笑话网站整站内容。webpasser是一款可配置的爬虫框架,内置页面解析引擎,可快速配置出一个爬虫任务。配置方式将页面解析和数据存储分离,如果目标网站改版,也可以快速修复。
配置说明如下(该例子完整配置见http://git.oschina.net/passer/webpasser):
1.先写总的抓取参数:网页编码是gbk,请求超时时间是5秒,请求失败重试5次,抓取失败后等待时间10秒,设置10个线程抓取,每次抓取后不等待。这里不设置请求头信息、cookie,代理了。
<fetchConfig charset="gbk" timeOutSecond="5" errorRetry="5" errorDelayTime="10" runThreadNum="10" fetchPrepareDelayTime="0" >
<userAgent>Mozilla/5.0 (compatible; webpasser;)</userAgent>
<headers>
<!-- <header name="Referer" value="http://www.jokeji.cn" /> -->
</headers>
<!-- HTTP Cookie -->
<cookies>
<!-- <cookie name="cookie1" value="" host="" path=""/>
<cookie name="cookie2" value="1" /> -->
</cookies>
<!-- 代理设置: 从ip.txt中批量获读取ip,每次抓取随机使用某个ip -->
<!-- <proxies path="ip.txt"></proxies> -->
<!-- 单个代理获取 ,pollUrl的系统链接中需随机返回一个代理ip,格式是 ip:port
(当使用proxy标签时proxies失效)
-->
<!-- <proxy pollUrl="http://localhost:8083/proxyManage/pollProxyIp.action?task=xunbo" ></proxy>
-->
</fetchConfig>2.scope表示限制抓取的链接域名范围(注意limitHost里一定要是域名,不能在前后加http或/),seeds表示从这些seed为入口开始抓取。
<scope>
<limitHost value="www.jokeji.cn" />
</scope>
<!-- 种子 -->
<seeds>
<seed url="http://www.jokeji.cn/" />
</seeds>3.如果网页的链接格式符合scope的规则,则进入这个page的解析策略。digLink是用来从一个网页中挖取新的链接。用jsoup语法指定从所有的a标签挖取新链接。由于新链接是相对链接,用relativeToFullUrl处理链将相对链接转为绝对链接。

<page>
<scope>
<rule type="regex" value="http://www.jokeji.cn(.*)" />
</scope>
<!-- 链接挖取 -->
<digLink >
<rules>
<rule type="jsoup" value="a[^href]" attr="href" />
<rule type="relativeToFullUrl" />
</rules>
</digLink>
</page>4.抽取详情页中想要的具体业务数据,经过下面解析后返回指定的map数据。
(1)获取标题数据:通过jsoup语法(jquery选择器)获得title标签中的内容;由于title内容中"_"后面的内容不需要,通过“cut”便签(截取处理链)将“_”后面的内容去除。

(2)获取文章内容的数据:通过jsoup语法(jquery选择器)获得id为text110的标签里的内容。

<!-- 解析具体的业务数据,处理后是一个map
-->
<page>
<scope>
<rule type="regex" value="http://www.jokeji.cn/jokehtml/(.*).htm" />
</scope>
<field name="title" >
<!-- 提取某个字段数据的处理链 -->
<rules>
<rule type="jsoup" value="title" exp="html()" />
<rule type="cut" >
<pre></pre>
<end>_</end>
</rule>
</rules>
</field>
<field name="content" >
<rules>
<rule type="jsoup" value="#text110" />
</rules>
</field>
</page>5.解析好的数据持久化配置(存储步骤4中的数据):target为handleResultMapInterface是固定值,表示是持久化的类,classPath是具体的实现类。com.hxt.webpasser.persistent.impl.DiskJsonHandleResult是存储到硬盘的实现类demo,该类属性有rootDir(保存到哪个文件夹)、charSet(存储时的编码),详见该类。可自定义编写持久化类,继承HandleResultMapInterface接口,有些属性用配置传入。(建议持久化是另外一个独立项目提供数据存储的http接口,爬虫请求该接口将数据push进去,这样分离维护比较方便,例com.hxt.webpasser.persistent.impl.VideoPushServcieImpl)
<!-- 抓取解析后的数据持久化 -->
<resultHandler target="handleResultMapInterface" classPath="com.hxt.webpasser.persistent.impl.DiskJsonHandleResult">
<property name="rootDir" value="downdir/path/jokeji" ></property>
<property name="charSet" value="gbk" ></property>
</resultHandler>
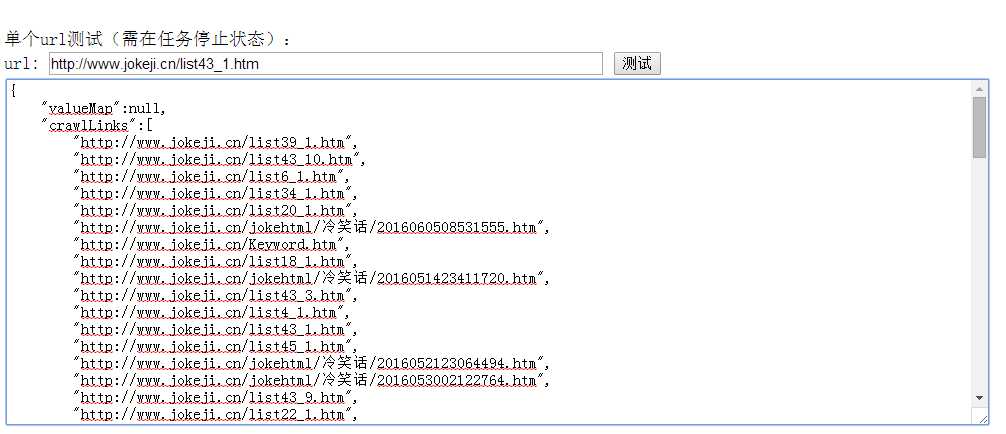
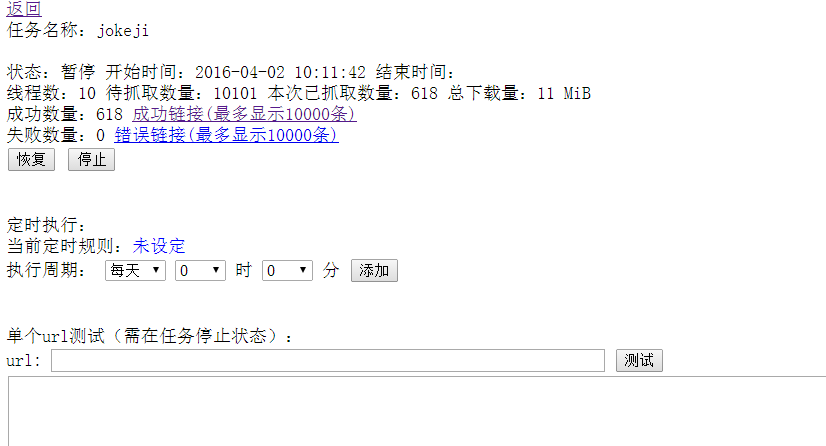
6.配置写好后就可以加入任务,启动测试了。建议可以单个测试下。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号