记录一次简单的模型训练分析过程

本篇是自己学习过程中的记录,使用的数据集比较小,主要是为了代码分析和简单的提点。代码分析的部分在之前的文章中已经总结了,本篇主要是结果分析和提升map的一些尝试,入门阶段,高手请绕行。
1|0数据集
目标:口罩
标签:mask, no-mask
图片数量:149
训练集:123个
验证集:46个
来源:https://app.roboflow.com/yolo-e1ffu/mask-lcllo/2



2|0baseline模型训练
参数:
训练框架:yolov5
模型:yolov5s
显卡:4090
训练命令:

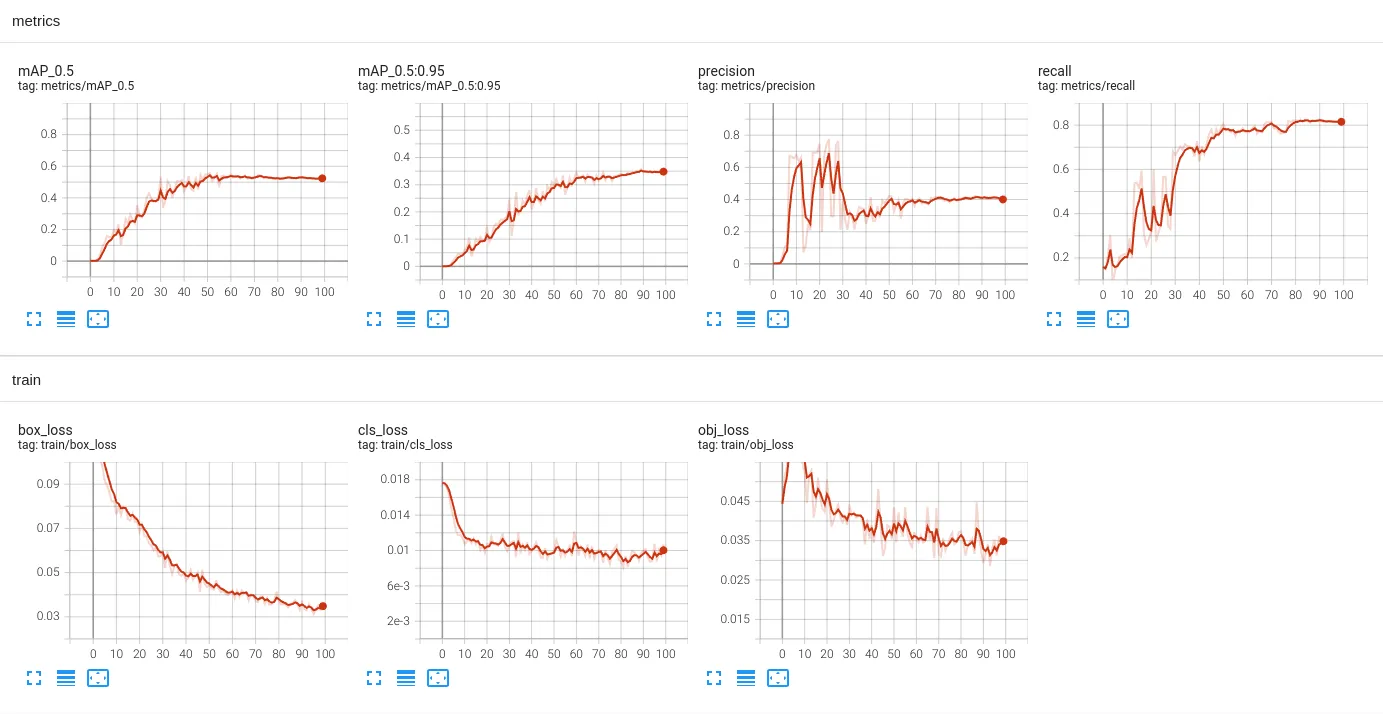
结果分析:
分析训练的结果,首先看损失曲线。损失曲线都稳定下降,并最终处于一个水平的范围,损失函数、学习率等参数正常。然后看PR曲线,P曲线有点震荡,R曲线正常,随着训练次数逐渐上升。最后看map。mask的map为0.893属于正常,no-mask的map为0.175偏小。
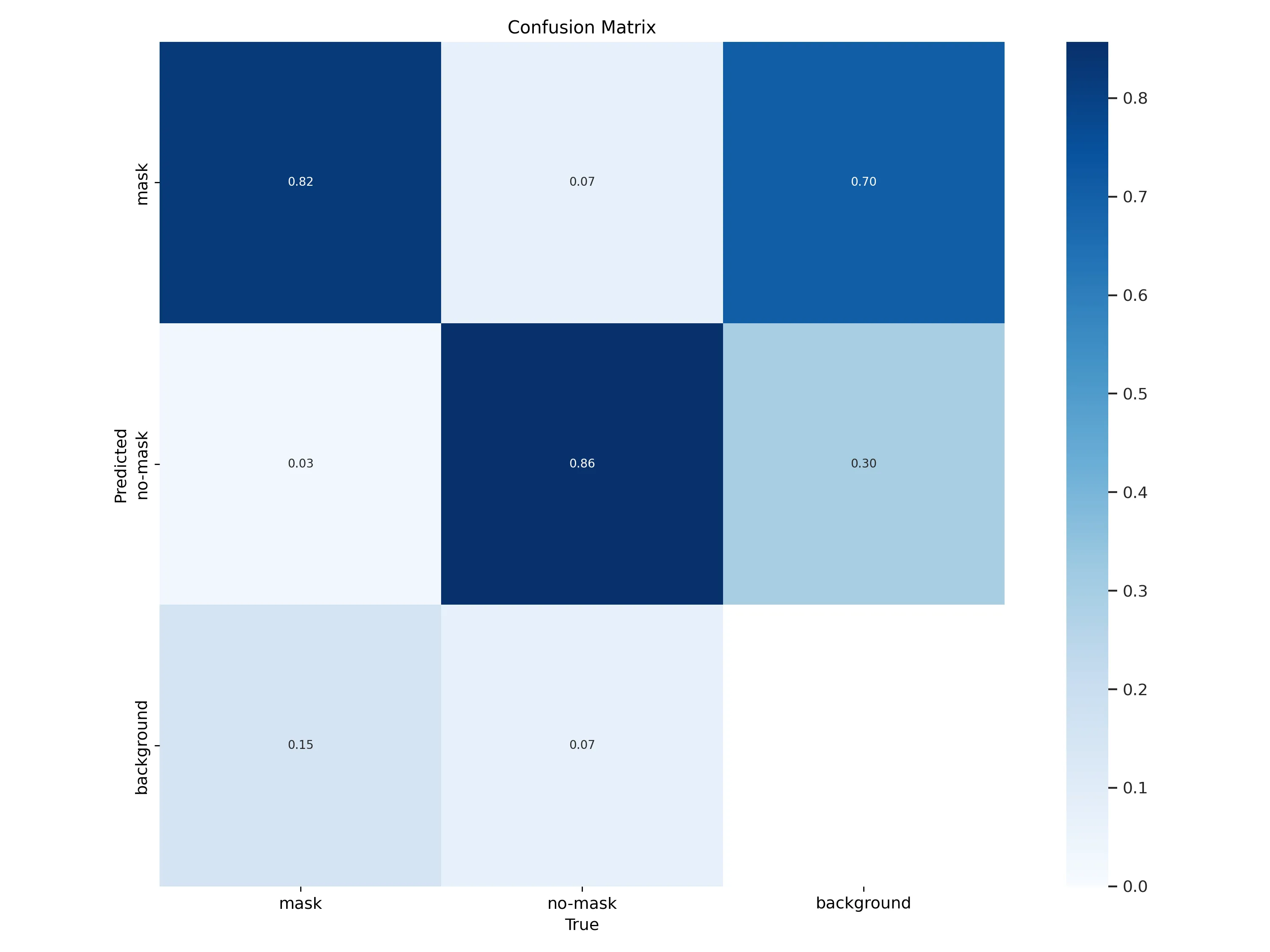
从混淆矩阵来看,no-mask被识别成mask为0.25,这个指标有点偏高,no-mask被识别成background为0.1,也有点高,也就是漏检高。
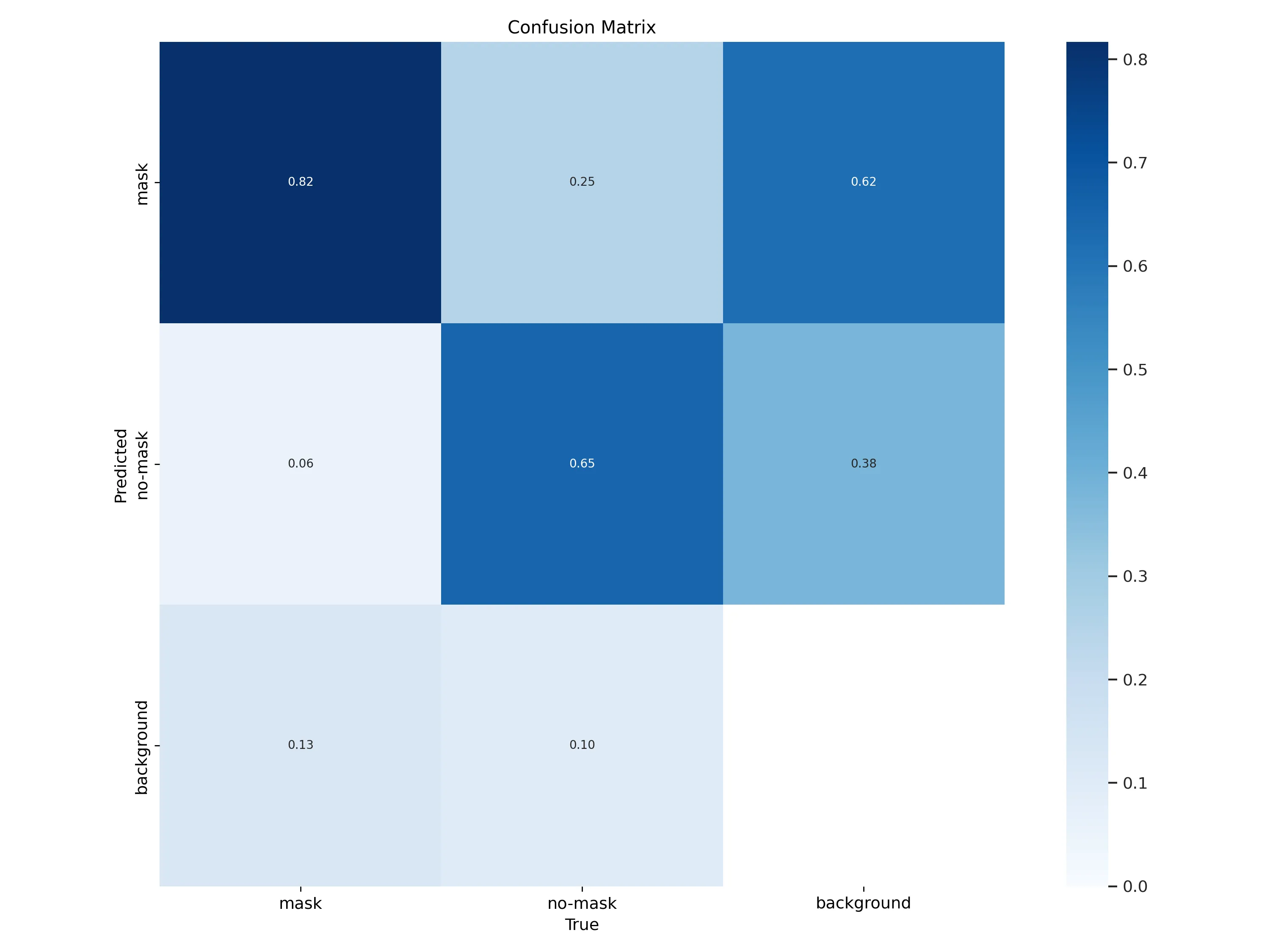
思路:no-mask的map是主要问题,能够提高no-mask的map就能大幅提高整体map。
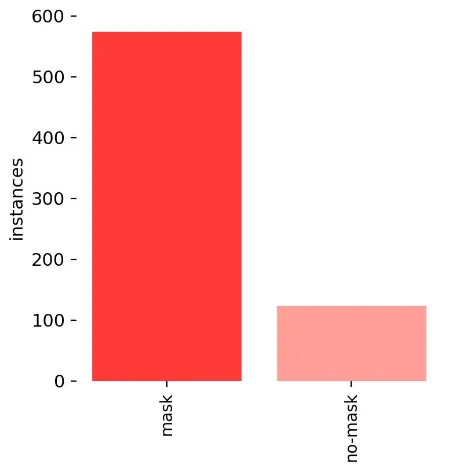
分析数据集发现no-mask标签的数据偏少,所以需要增加对应数据集。
3|0第一次增加数据集
标注不带口罩的数据集18张,1:1分为训练集和验证集。
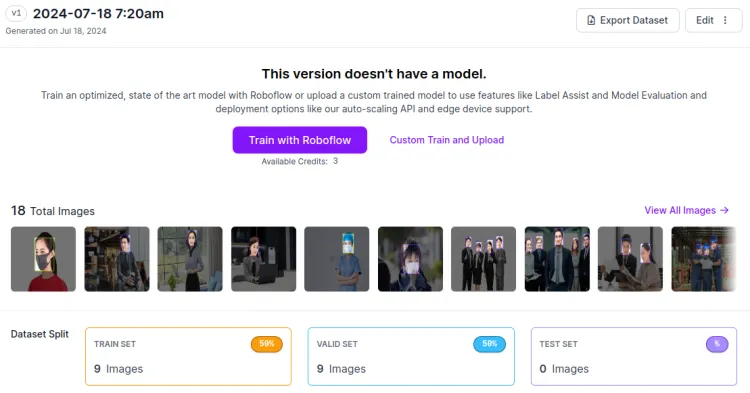
训练:
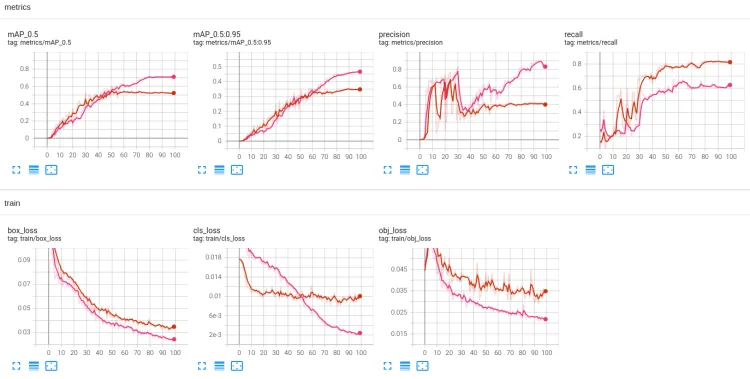
分析:
粉红色为本次训练,可以看到训练的效果相比较上一次较好。从map来看,从0.534提高到0.711。主要是no-mask类别的map从0.175提高到0.543。
4|0第二次增加数据集
继续新增no-mask相关数据集,共17张。


训练:

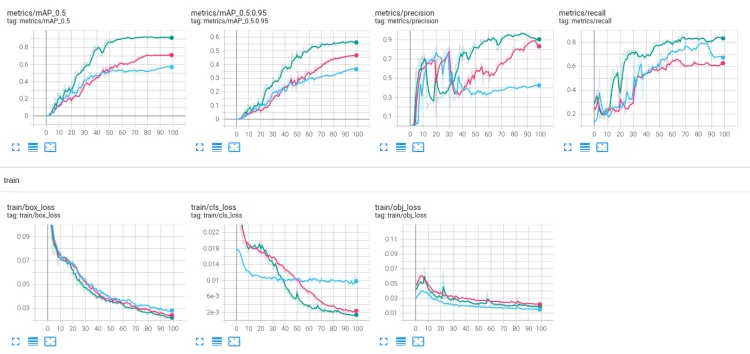
分析:
混淆矩阵的变化,no-mask的正检升高,漏检都下降到0.07
将整体map从0.711增加到0.919,no-mask的数据集从0.543上升到0.939。
5|0总结
记录map变换
| 训练记录 | map@0.5 | mask map | no-mask map |
|---|---|---|---|
| baseline | 0.534 | 0.893 | 0.175 |
| 1.0 | 0.711 | 0.88 | 0.543 |
| 2.0 | 0.919 | 0.9 | 0.939 |
增加数据集是提高map的一种重要方法,特别是在数据集较少的情况下
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/18315451.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理