内部UI自动化测试培训之python基础

这个文档的由来是公司内部UI自动化测试培训的资料。部门为了减少测试工作量,准备做UI自动化测试。我写python,其他同事都是java,所以python基础和UI自动化测试selenium的培训就由我来完成。
完整教程包括4篇内容,本篇是python的基础内容,高手请跳过。虽然是基础,但是可以看做是一个python的微型教程,如果想了解python,简单上手尝试,这个教程适合。
UI 自动化测试相关内容:
1|0前言
Python 是一门上手非常快的语言,学习python这门编程语言达到能够正常使用的程度,需要掌握的点包括:
- 语言基础特性
- 数据类型
- 流程控制
- 函数调用
- 面向对象
- 模块与包
下面从这6个方面来快速熟悉python语言
2|0语言基础特性
2|1解释性语言
程序执行原理:
计算机不能直接理解高级语言,只能理解和运行机器语言,所以必须要把高级语言翻译成机器语言,计算机才能运行高级语言所编写的程序。
编译型:
程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。
编译型语言:
C/C++、Golang。典型的就是C语言可以编译后生成可执行文件,之后无需再次编译,直接运行可执行文件即可。
解释型:
程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。因此效率比较低。
解释型语言:
PHP、JavaScript、Perl、Python、Ruby 等等
Python 是一个解释性语言,Python解释器首先会将python程序编译成中间文件 .pyc 文件,然后解释器执行pyc文件。
2|2优缺点

- WEB开发——最火的Python web框架Django, 支持异步高并发的Tornado框架,短小精悍的flask,bottle。
- 网络编程——支持高并发的Twisted网络框架, py3引入的asyncio使异步编程变的非常简单
- 爬虫——爬虫领域,Python几乎是霸主地位,Scrapy\Request\BeautifuSoap\urllib等,想爬啥就爬啥
- 云计算——目前最火最知名的云计算框架就是OpenStack,Python现在的火,很大一部分就是因为云计算
- 人工智能—— Python 是目前公认的人工智能的必备语言,pytorch和tensorflow等框架都是用python编写
- 自动化运维 devops ——问问中国的每个运维人员,运维人员必须会的语言是什么?10个人相信会给你一个相同的答案,它的名字叫Python
- 金融分析——金融行业写的好多分析程序、高频交易软件就是用的Python。到目前Python是金融分析、量化交易领域里用的最多的语言
- 科学运算—— 97年开始,NASA就在大量使用Python在进行各种复杂的科学运算,随着NumPy, SciPy, Matplotlib, Enthought librarys等众多程序库的开发,使的Python越来越适合于做科学计算、绘制高质量的2D和3D图像。和科学计算领域最流行的商业软件Matlab相比,Python是一门通用的程序设计语言,比Matlab所采用的脚本语言的应用范围更广泛
2|3性能问题
python最大的问题就是性能问题,可以参考如下性能测试。
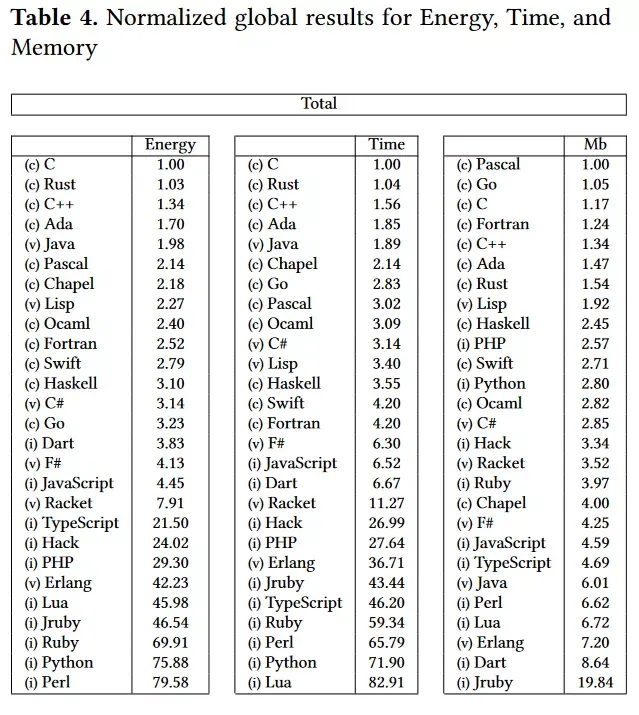
但是python并不是不能支持大型项目。比如facebook的很多大型后台服务都是python项目。
Twitter 劲敌 Threads,“魔改”了哪些 Python 技术栈?

新手小提示:如果在此之前没有接触过python编程,想要尝试复现本教程中的示例,可以通过如下几步:
- 找到一个linux服务器
- 在命令行中输出python3,进入python解释器中
- 逐条输入代码
3|0数据类型
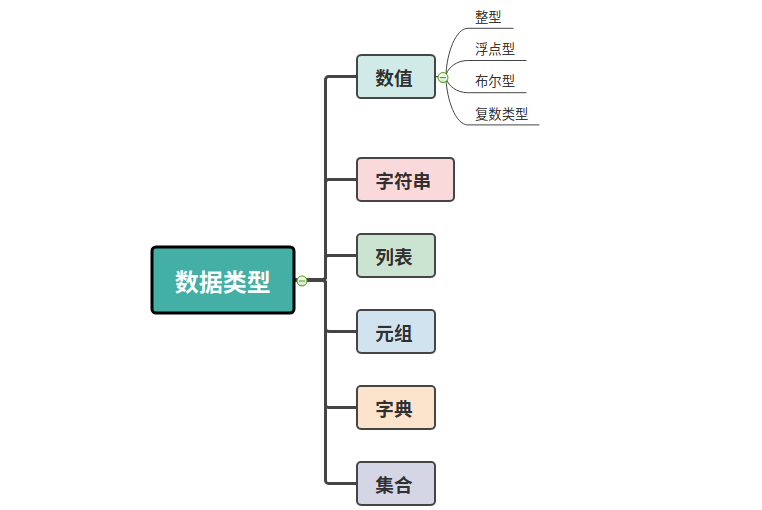
Python 有数据类型,但是变量定义时不需要指定变量的类型。格式:
对比java,C++等需要指明变量的类型
3|1数值
整型:可以存储无限大的数字,理论上没有上限
浮点型:没有精度限制
布尔:用True和False表示布尔类型。True可以当成数值1来用,False可以当成0来用
复数:一个实数和一个虚数组合构成,表示为:x+yj
3|2字符串
访问:使用下标直接访问字符串中的特定字符。可以正索引,也可以负索引
切片:所谓切片就是获取序列的一个连续子序列。字符串切片语法是:[start:end],取到的范围是下标start开始到end-1,也就是所谓的左闭右开
3|3列表
列表是一种容器类型,类似于数组,按照顺序排序元素。但是存入的元素没有数据类型的约束,可以是任意类型。
特点:无限长度、可以存入任意类型的数据结构
创建:使用中括号创建列表
访问:可以索引访问,支持切片,支持负索引,支持按步长访问
添加:append 在尾部追加 ;insert 在任意下标插入数据
删除:pop()删除队列末尾; pop(index)删除指定下标; remove(value) 删除指定值
3|4元组
元组和列表类似,但是元组是不可修改,删除元素。
特点:不可删除和修改元素,是不可变序列
创建:创建一个元组有两种方法,分别是小括号和tuple关键字
访问:可以通过下标和切片的方式访问元组
3|5字典
字典也是一种容器类型,java中叫hashmap,是由键值对组成的数据结构。
特点:访问时间复杂度为常数
创建:通过大括号和dict关键字都可以创建字典
访问:字典通过key来访问value,一共有两种访问方式[]和get方法。
添加:两种添加方法,增加keyvalue键值对和更新另一个字典
删除:两种删除方法,pop删除指定key,popitem()随机删除一个
3|6集合
python中的集合,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。
特点:元素不重复,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型。
创建:
从形式上看,和字典类似,Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
访问:集合不支持单个元素访问,可以遍历全部
添加:使用add添加元素
删除:使用remove删除指定值,如果不存在该值会抛出异常
集合操作:集合支持数学意义上的集合的操作,包括:两个集合取交集、差集、并集、补集
4|0流程控制
4|1条件判断
python使用if关键字做条件判断,语法特点:
- 使用缩进对齐来确定代码块
- 使用冒号标志结束
4|2循环语句
python只有两种循环语法,分别是for循环和while循环,没有do while这种语法
for循环
python中的for循环使用in这个关键字,从待循环的容器中取出每一个元素,赋值给循环标识i

java for循环和python for循环对比
java for循环是让变量x不断自增,直到大于20退出循环,python for循环是range(20)生成一个从0到19的容器,每次取出一个元素赋值给i。
while
while 遇到条件不满足则退出,和其他语言类似
5|0函数调用
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。函数能提高应用的模块性,和代码的重复利用率。
5|1函数定义
定义函数通过def关键字开始,冒号结束。函数代码块以统一缩进标识。
5|2函数返回
python中函数返回有一个特性:函数可以返回多个值,如:
如上示例返回两个值,函数调用时也需要用两个值接收,否则会抛出异常。
6|0面向对象
6|1类和实例
使用关键字class定义,class后面紧接着是类名。类名通常是大驼峰命名
object 是Student继承的类,如果没有继承任何类可以省略括号以及里面的内容。
6|2实例
类是抽象的模板,比如Person类,而实例是根据类创建出来的一个具体的对象。python不需要任何关键字就能实例化一个对象,使用函数调用的方法就能创建一个实例。
6|3属性
python面向对象中,变量叫做属性

6|4方法
python面向对象中,函数叫做方法


6|5构造方法
在python的类中有一个特殊的方法用于实例创建时初始化,就是构造方法。
类就如同一个模板,通过类创建的实例肯定是千差万别的。实例在创建时可以传入属于自己的属性,在python中就是通过这个构造方法__init__来实现。
在创建实例时传入name 和 job 两个参数
后续整个实例都可以使用该初始化的参数
对比java中也有构造方法
7|0模块与包
7|1模块
python中代码是通过模块和包管理的。
一个 py 文件就是一个模块。

7|2包
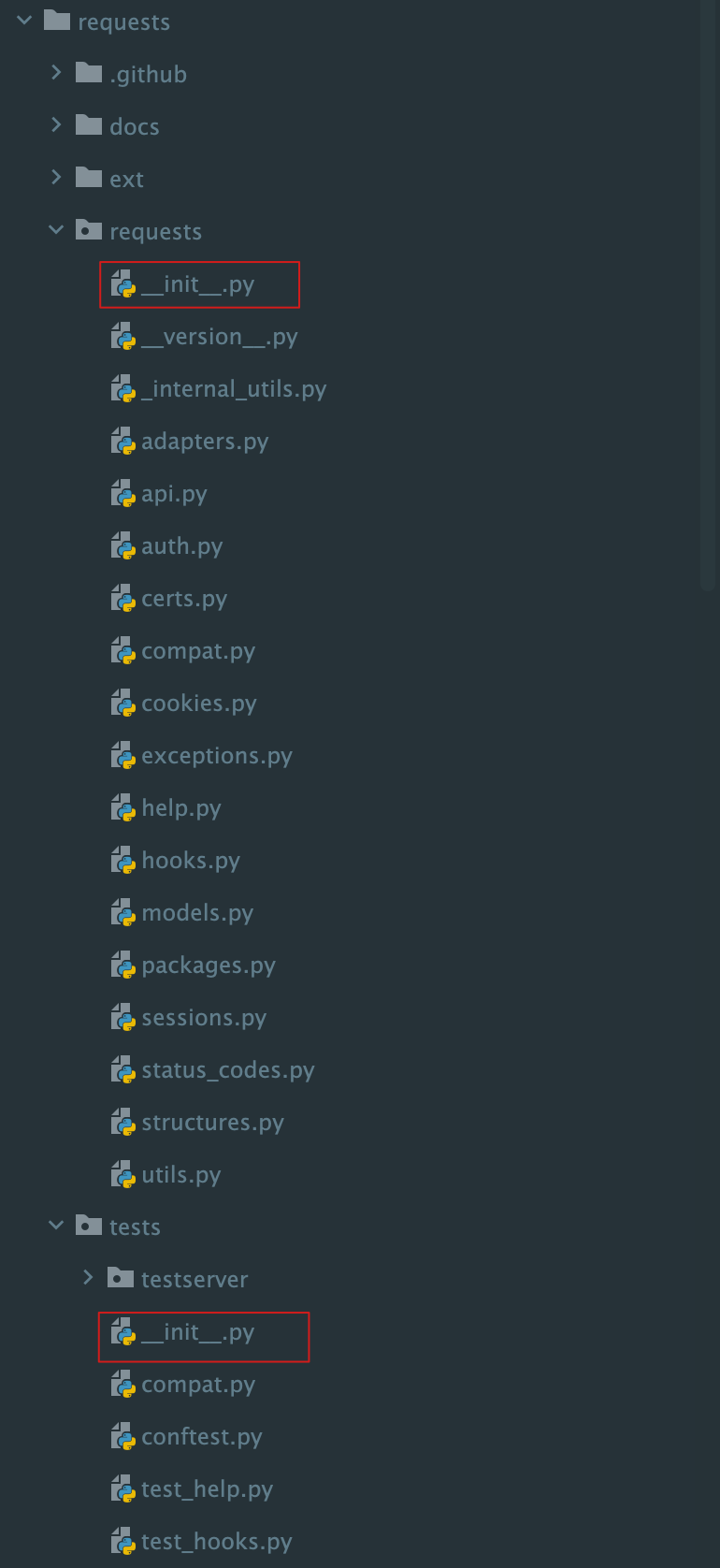
包是保存几个模块的文件夹,包中通常包含几个py文件和一个__init__.py的特殊文件。__init__.py 用于标识该文件夹是一个包。

Python 网络请求最常用的库requests目录赏析,每一个包的目录下面都有一个__init__.py文件。
8|0安装第三方包
安装第三方包,炫酷进度条。
python基础知识介绍到这里就结束了,UI自动化测试Selenium请参考另一篇 selenium 开源UI测试工具
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/18056448.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理